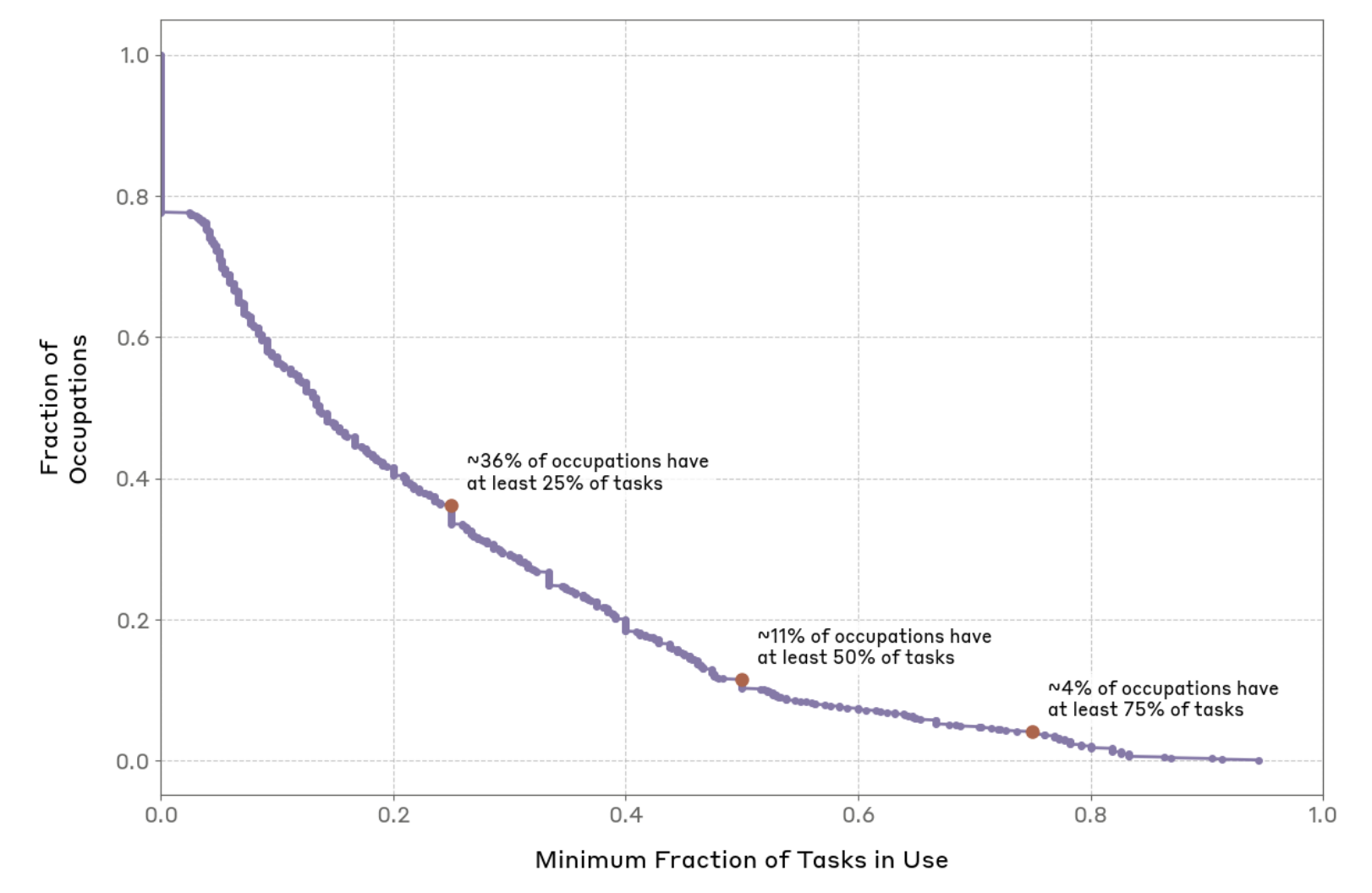
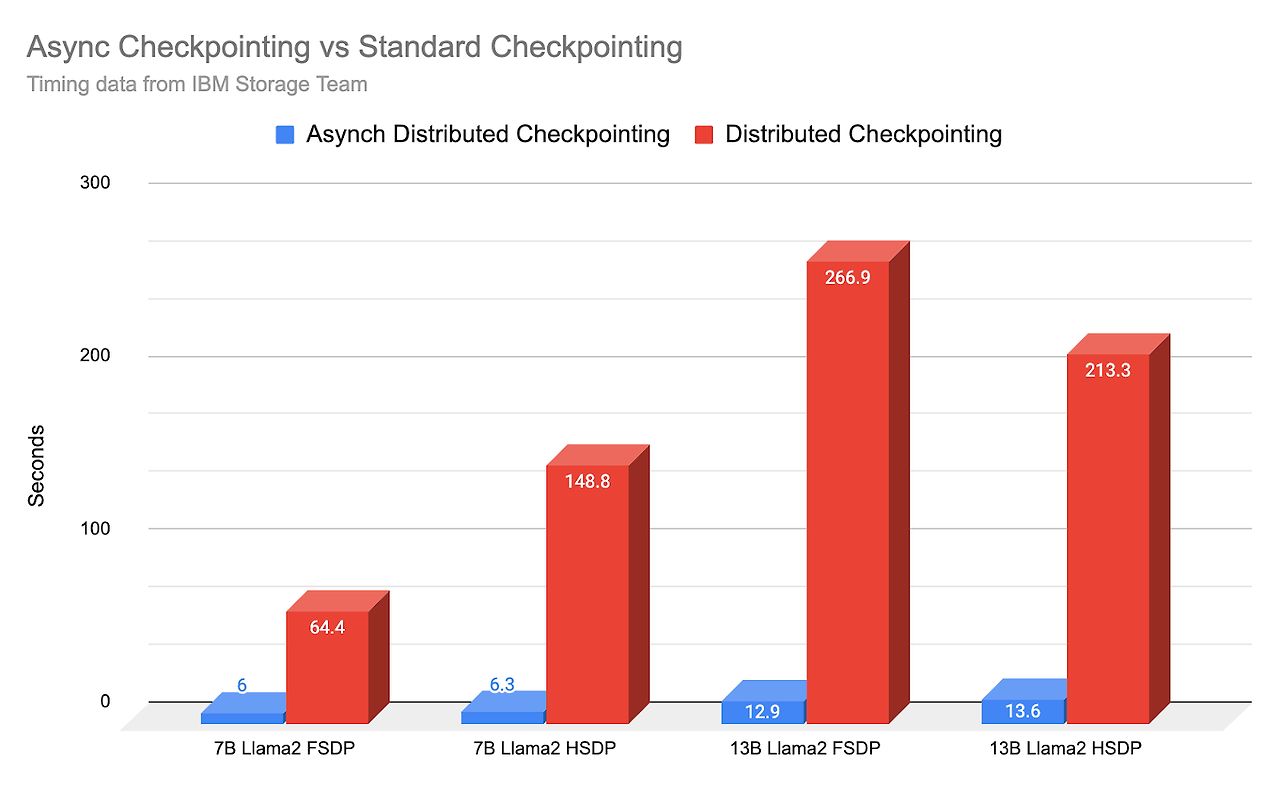
조대협 (http://bcho.tistory.com 앤트로픽에서 운영중인 모델의 데이터를 분석해서, 앤트로픽 모델이 주로 누가 어디에 사용하는지를 정리한 논문이 있어서 정리해본다. https://arxiv.org/abs/2503.04761v1?fbclid=IwY2xjawJWyMVleHRuA2FlbQIxMAABHVWipyblGC0KyHFa9XOFI58D9_YyB-2OTRySYTyE2sQ1xAiR4QwW5wXIEg_aem_FxQeOTGerX42xiHBiCRZIQ Which Economic Tasks are Performed with AI? Evidence from Millions of Claude ConversationsDespite widespread speculation about artificial i..