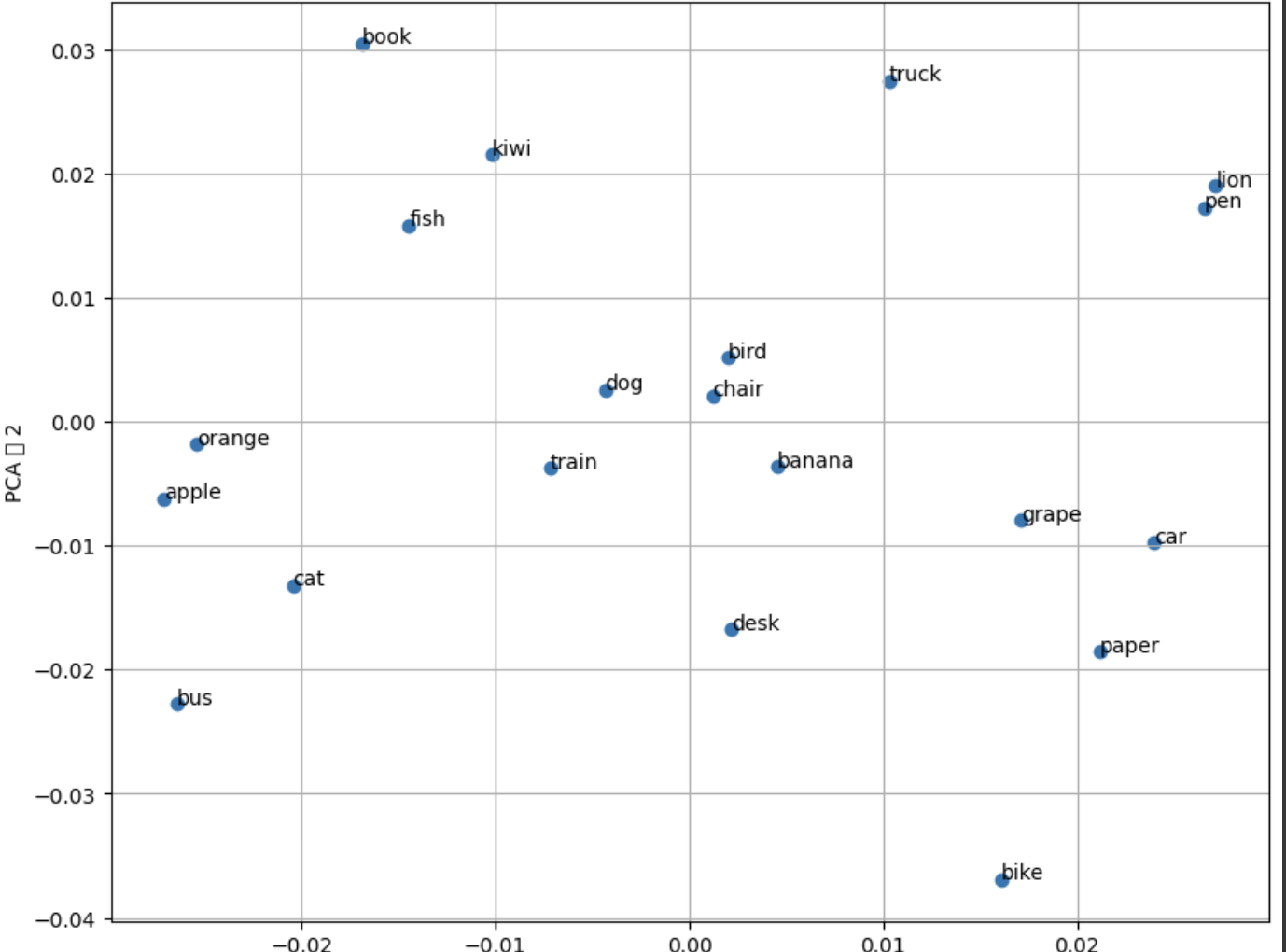
조대협 (http://bcho.tistory.com) 자연어 처리(NLP)의 핵심 기술 중 하나인 단어 임베딩(Word Embedding), 그 중에서도 단어 간 유사도를 어떻게 파악하는지 그 원리를 깊이 있게 파헤쳐 보려고 한다.혹시 컴퓨터가 어떻게 단어의 의미를 이해하고, "고양이"와 "강아지"가 유사한 단어라는 것을 알아차리는지 궁금한 적 없는가? 그 비밀은 바로 단어 임베딩에 있다! 핵심 원리: "비슷한 동네에 사는 단어는 비슷한 친구다!"단어 임베딩의 핵심 아이디어는 아주 직관적이다. 바로 **"유사한 맥락에서 등장하는 단어는 유사한 의미를 가진다"**는 분포 가설(Distributional Hypothesis) 에 기반을 두고 있다. 쉽게 말해, 비슷한 문맥에서 자주 함께 등장하는 단어들은 의..