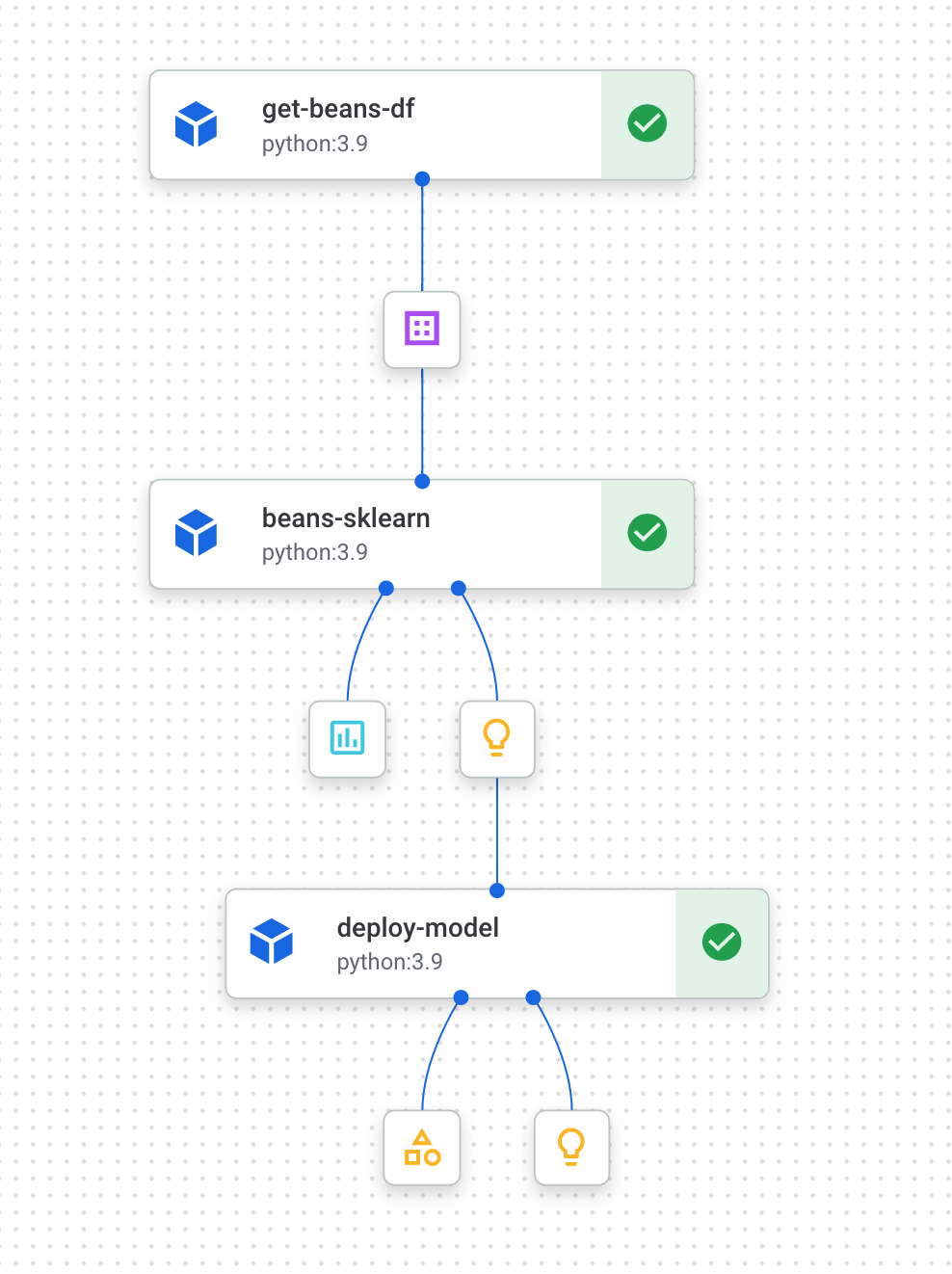
Vertex.AI Pipeline(Kubeflow pipeline) & metadata 조대협 (http://bcho.tistory.com) 이 글은 google developer codelab의 Using Vertex ML Metadata with Pipeline 예제를 기반으로 한다. . (코드 소스 : https://codelabs.developers.google.com/vertex-mlmd-pipelines) 예제 코드의 실행은 위의 링크를 참고하면, step by step으로 진행할 수 있다. Vertex.AI는 구글 클라우드의 AI 플랫폼 솔루션으로 여러가지 컴포넌트를 가지고 있다. 이 예제에서는 데이터를 읽어서 학습하고, 모델을 만들어서 배포하는 파이프라인에 대해서 설명한다. 파이프라인의 개..