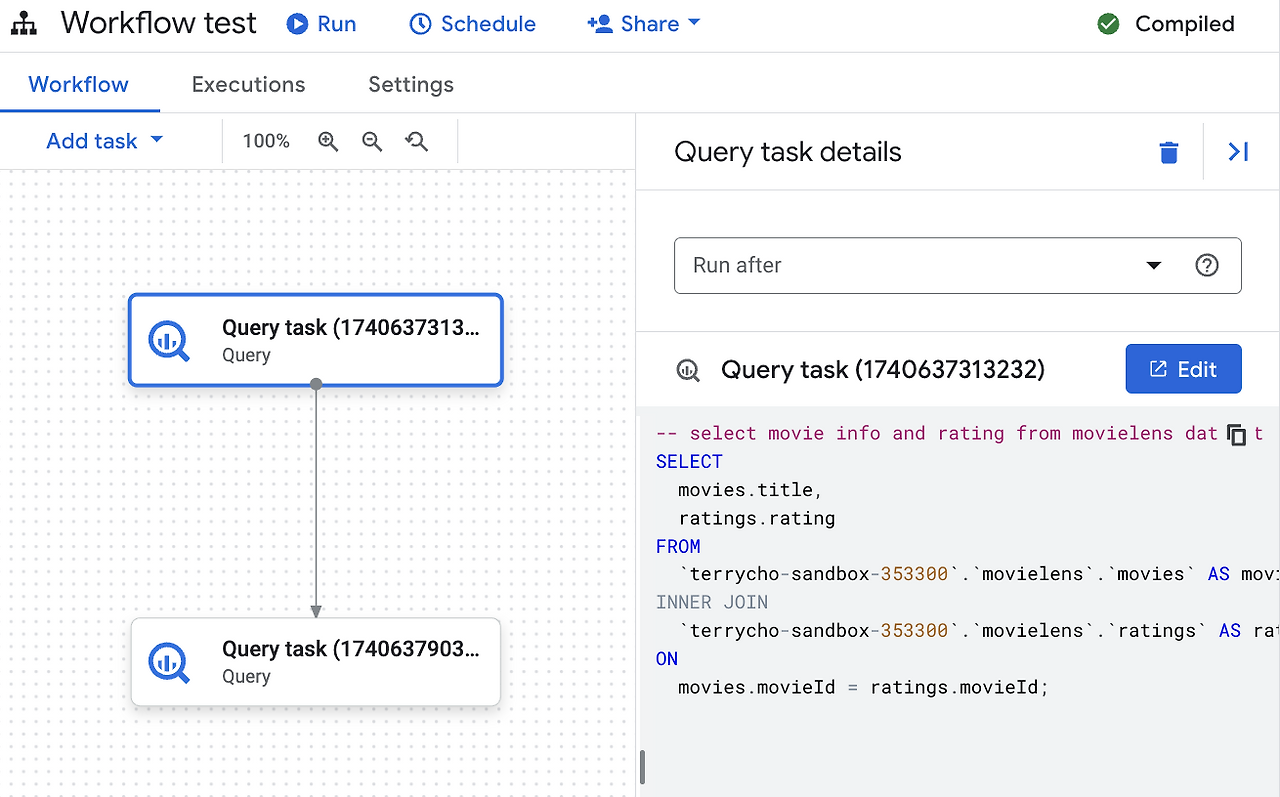
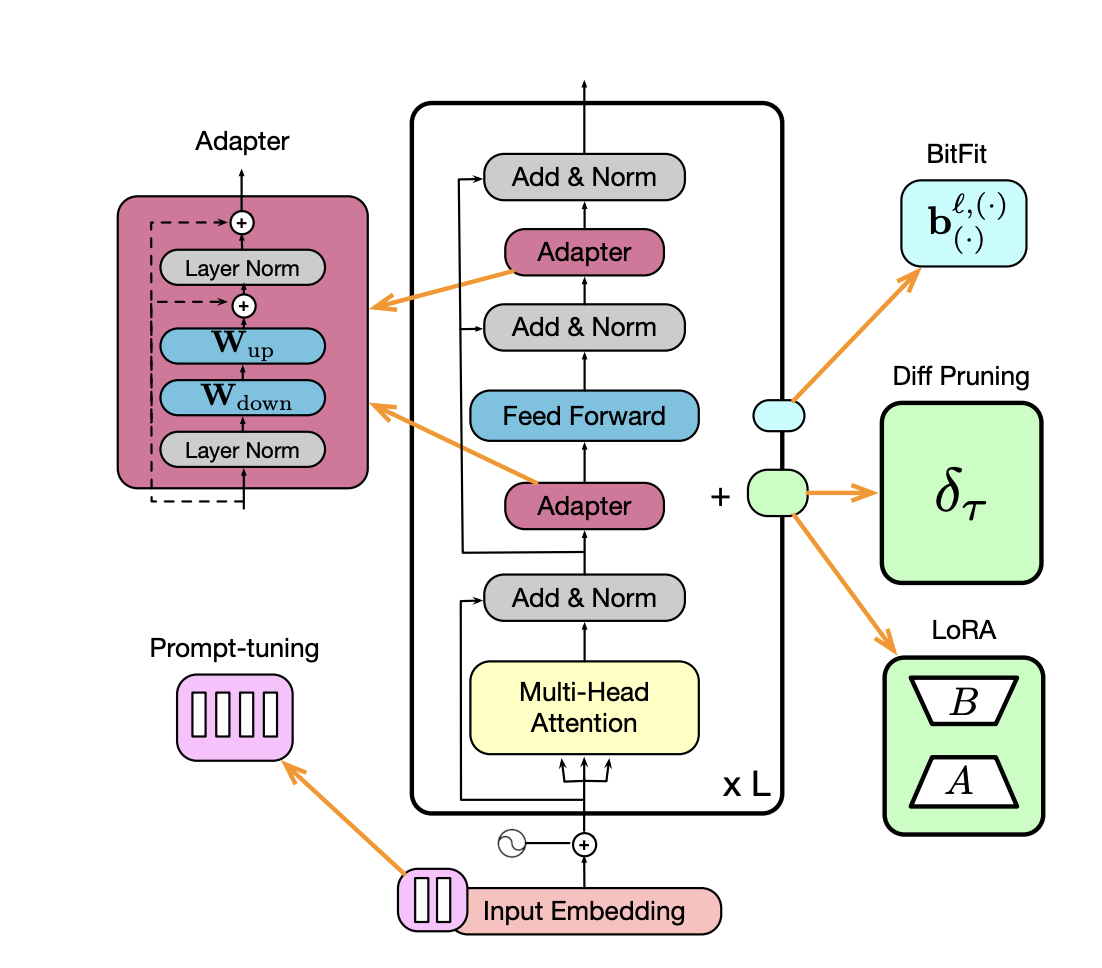
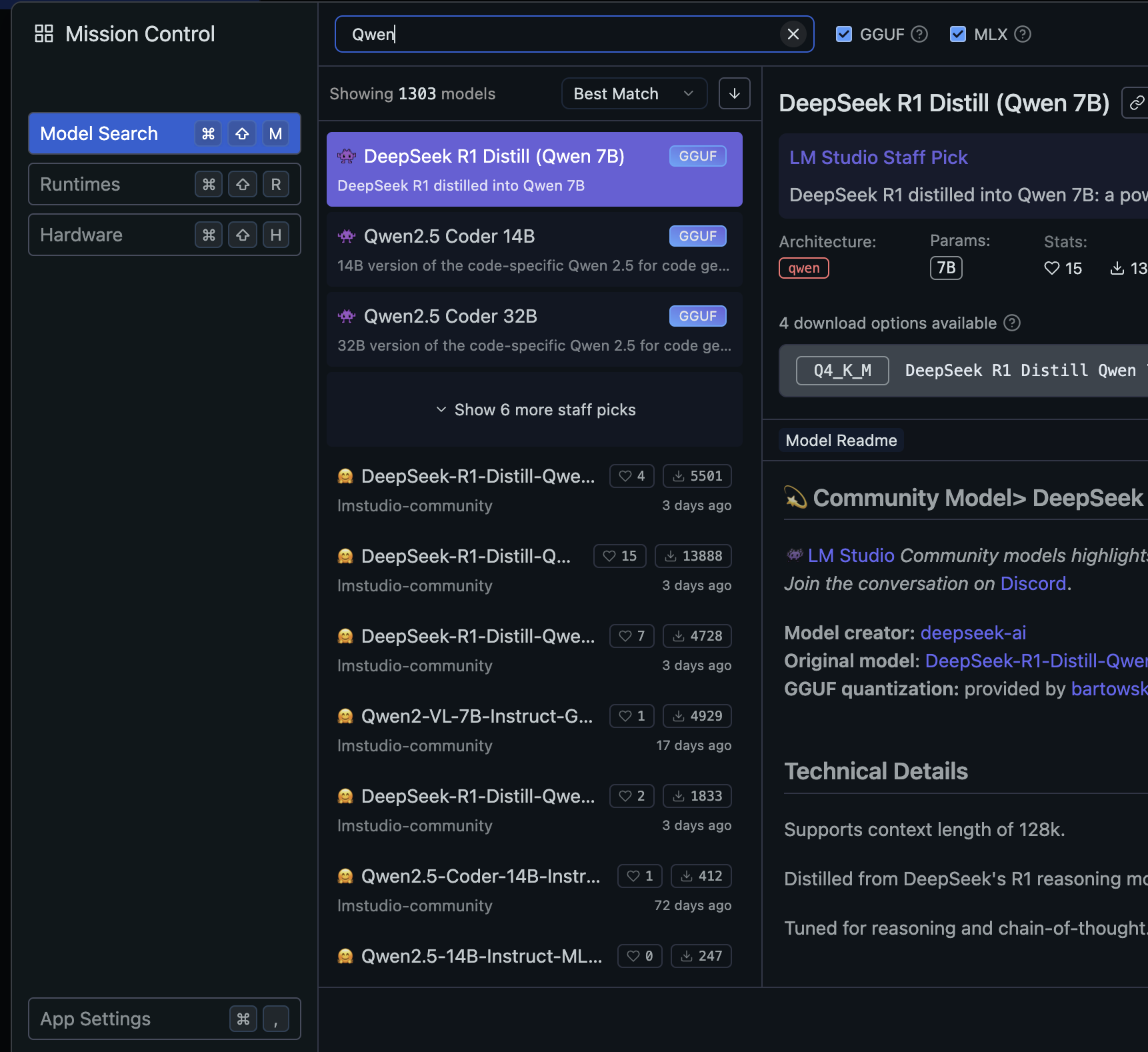
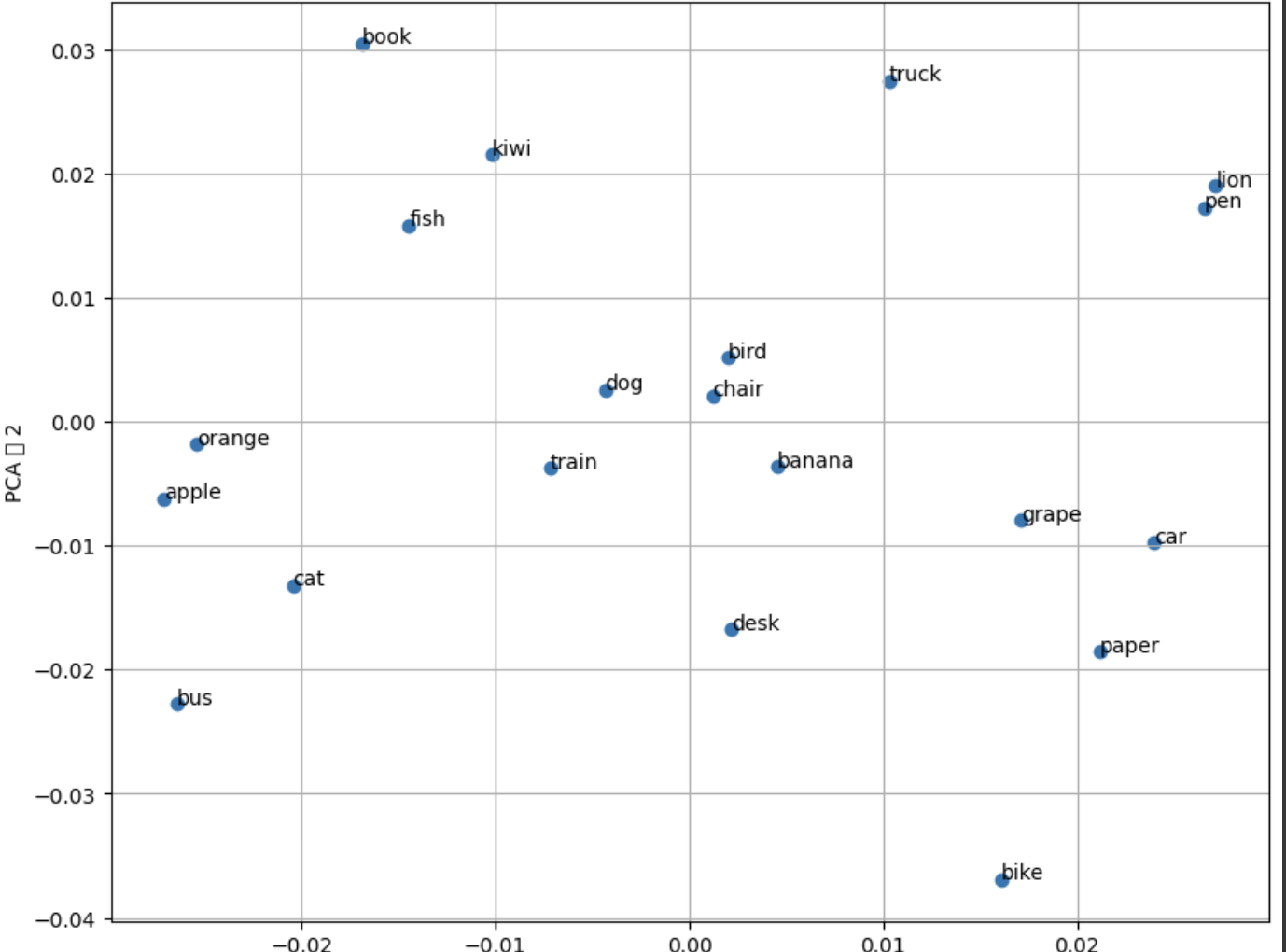
요즘 인터넷에 보면 가장 많이 나오는 단어가 바이브 코딩(Vibe coding)이 아닌가 싶다. Cursor와 같은 AI 코딩 도구를 이용해서, 코딩을 모르는 사람도 자연어로 요구 사항을 설명하면 AI가 자동으로 코드를 생성해준다. 유투브 채널에 보면 온갖 바이브 코딩에 대한 이야기이고, 개발자는 이제 없어질 것이며 신입은 필요가 없다는 이야기도 나오는데, 잘못된 오해가 많은 것 같고, 제대로 바이브 코딩을 하는 방법에 대한 가이드가 상대적으로 적은 것 같아서, 바이브 코딩에 대한 오해와, 어떻게 하면 바이브 코딩을 제대로 할 수 있을지에 대해서 설명하고자 한다. 바이브 코딩의 정의바이브 코딩은 OpenAI의 공동 창립자인 Andrej Karpathy에 의해서 2025년 2월에 소개되었다. 바이브 코딩은..