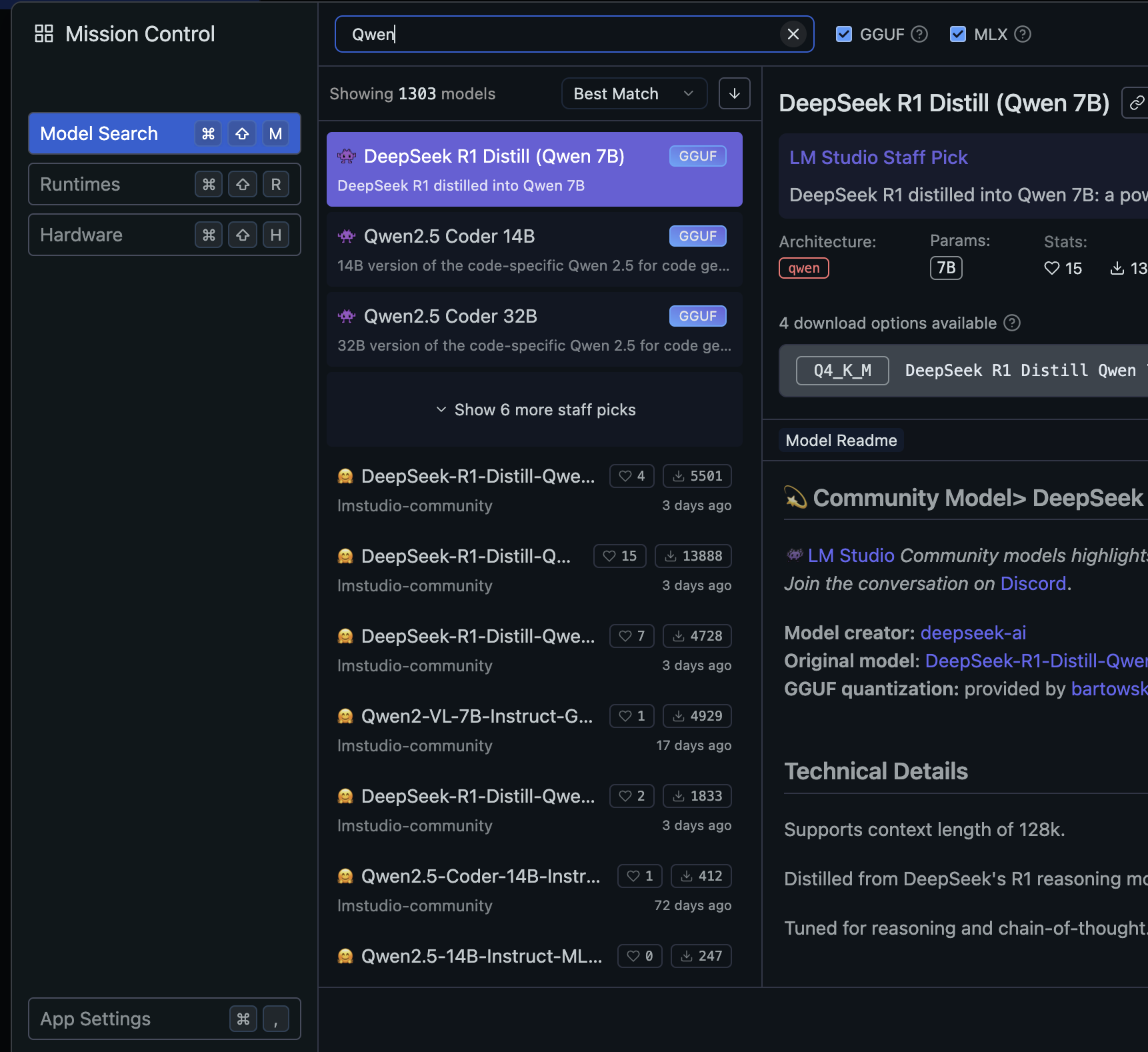
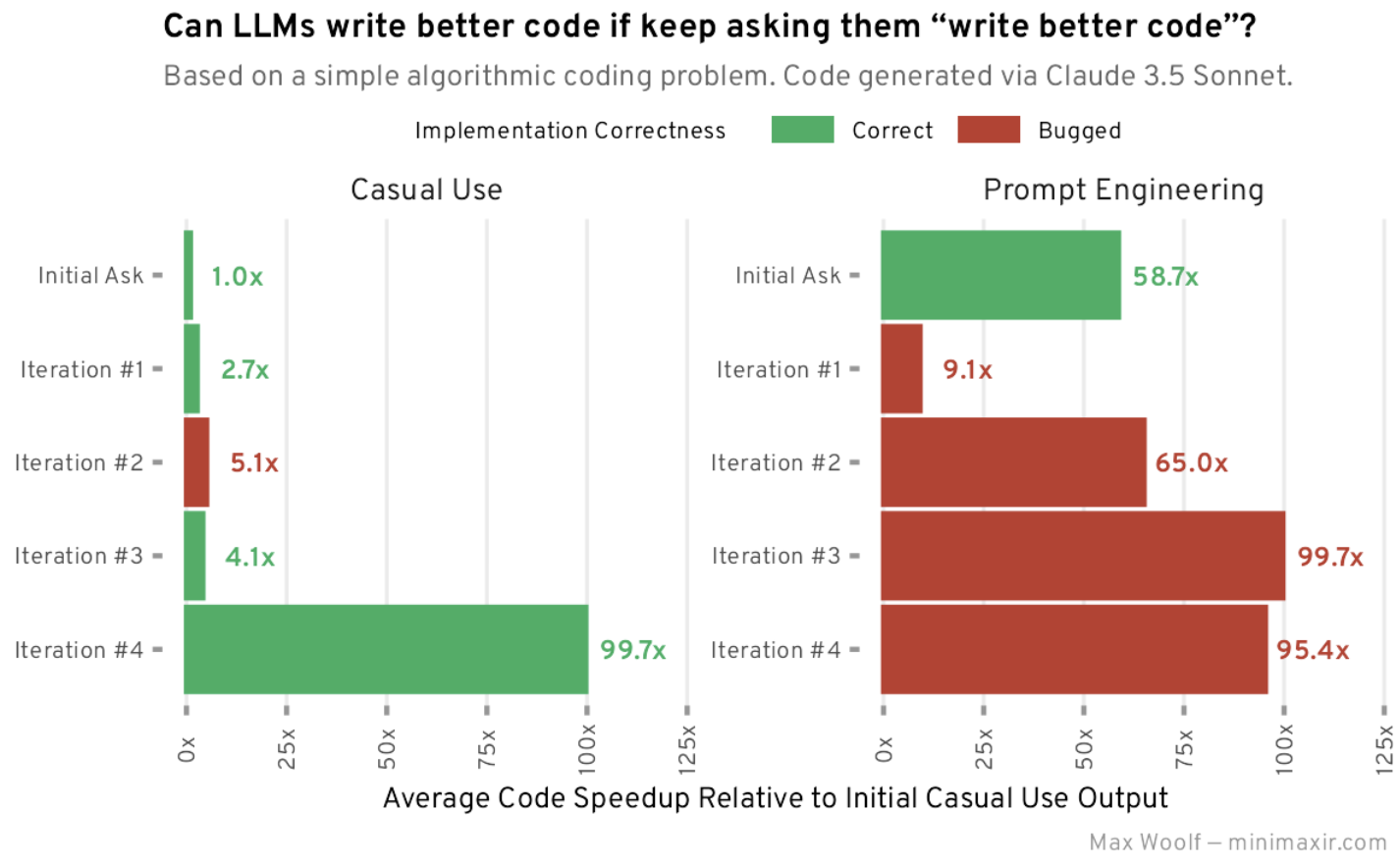
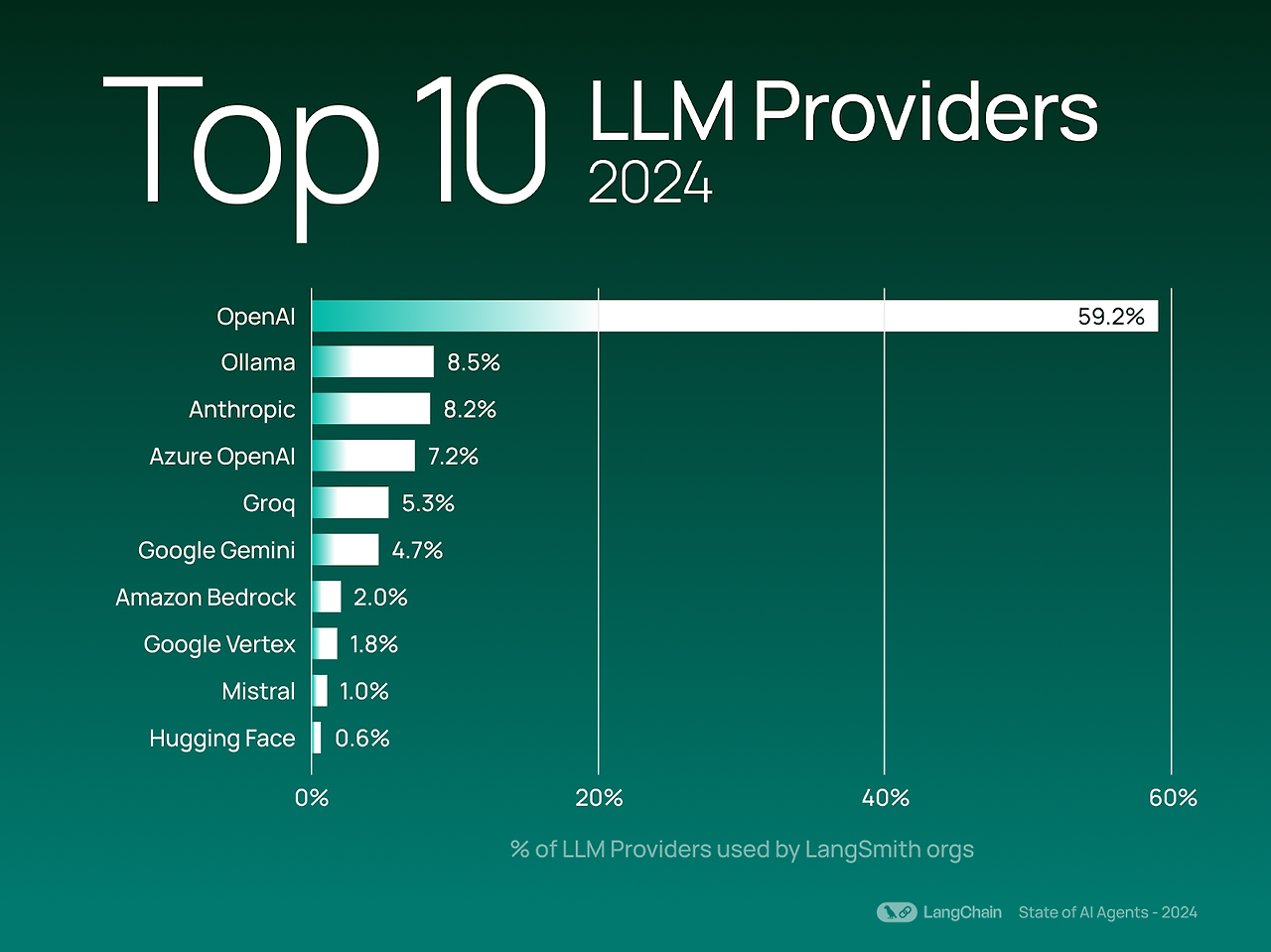
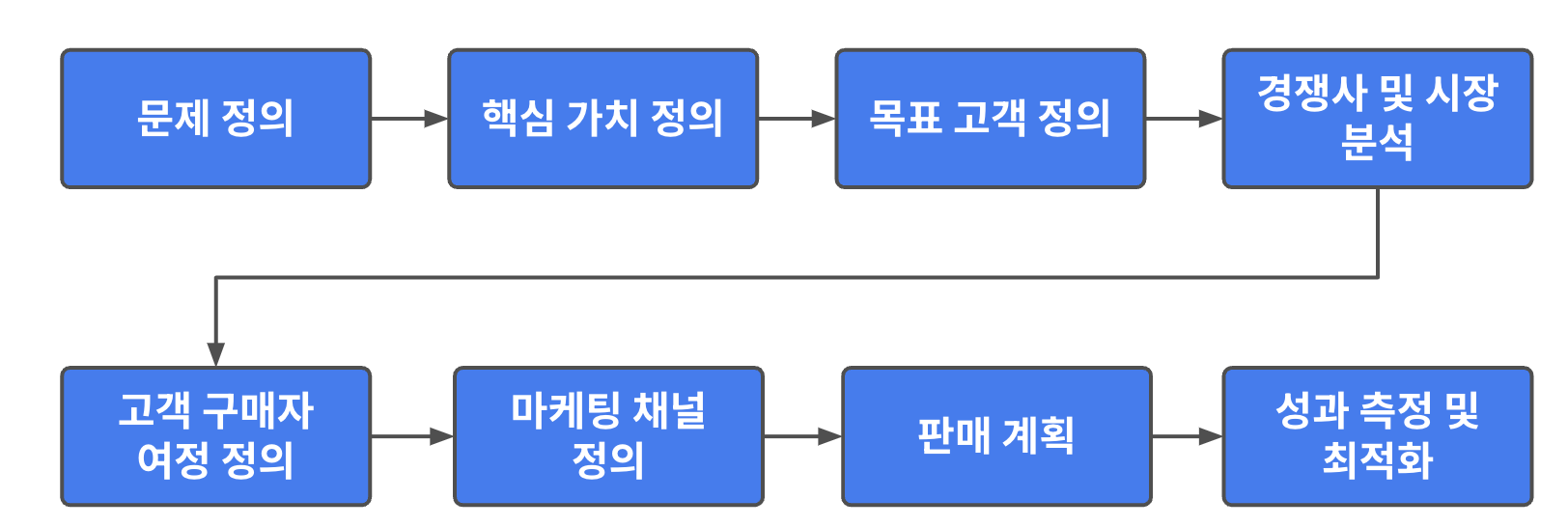
요즘 LLM이 유행하면서 로컬 환경에서 소형 LLM인 sLLM을 실행하는 경우가 많은데, sLLM은 종류도 많을뿐더라, 코드를 직접 실행하고, 런타임을 최적화하기가 매우 어렵다.이런 문제를 해결하기 위해서 sLLM을 손쉽게 실행할 수 있는 환경이 있는데, 가장 널리 사용되는 환경으로는 Ollama와 LMStudio가 있다. Ollama는 아래와 같이 CLI환경에서 프롬프트를 입력할 수 있다. 또한, HTTP REST API를 제공하기 때문에 애플리케이션 개발에도 유용하게 사용할 수 있다. 개인적으로는 LMStudio를 좀 더 선호하는데, LMStudio는 아래와 같이 GUI 베이스로, 쳇봇 GUI를 지원하기 때문에 좀더 깔끔하게 사용할 수 있고, 히스토리 관리등이 가능하다. 맥북 PRO M1으로 실..