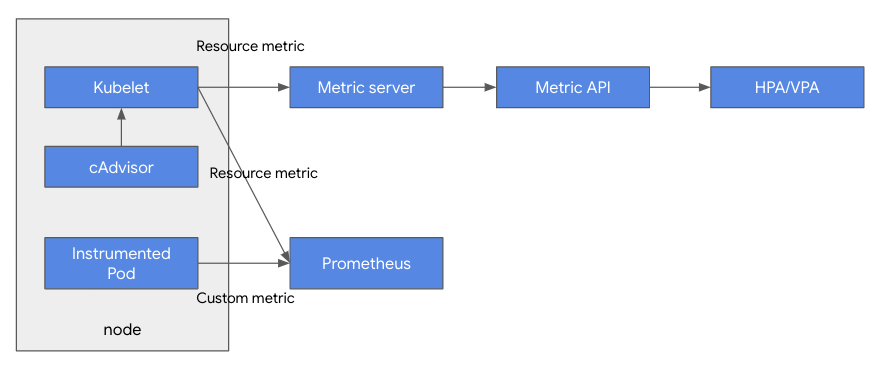
이벤트 베이스 쿠버네티스 오토스케일링 KEDA 보통 인스턴스 수를 늘이는 오토 스케일러는 메모리나 CPU와 같은 기초적인 자원 사용양에 따라서 작동하는 경우가 많다. 그러나 이보다는 애플리케이션의 큐 길이나 메시지 큐의 길이 또는 특정 이벤트에 따라서 자원을 스케일링 하는 것이 더 논리적인데, 이렇게 하기 위해서는 커스텀 메트릭을 프로메테우스등으로 수집한후, 이 메트릭을 CA (Cluster Autoscaler)에 적용하는 방법으로 구현해야 하는데, 구현의 복잡도가 높다. KEDA 오픈 소스는 Redis나 기타 오픈소스 또는 클라우드 자원과 쉽게 통합하여, 거기서 발생하는 이벤트를 이용하여 오토 스케일링을 손쉽게 가능하게 해준다. https://keda.sh/docs/1.4/scalers/redis-li..