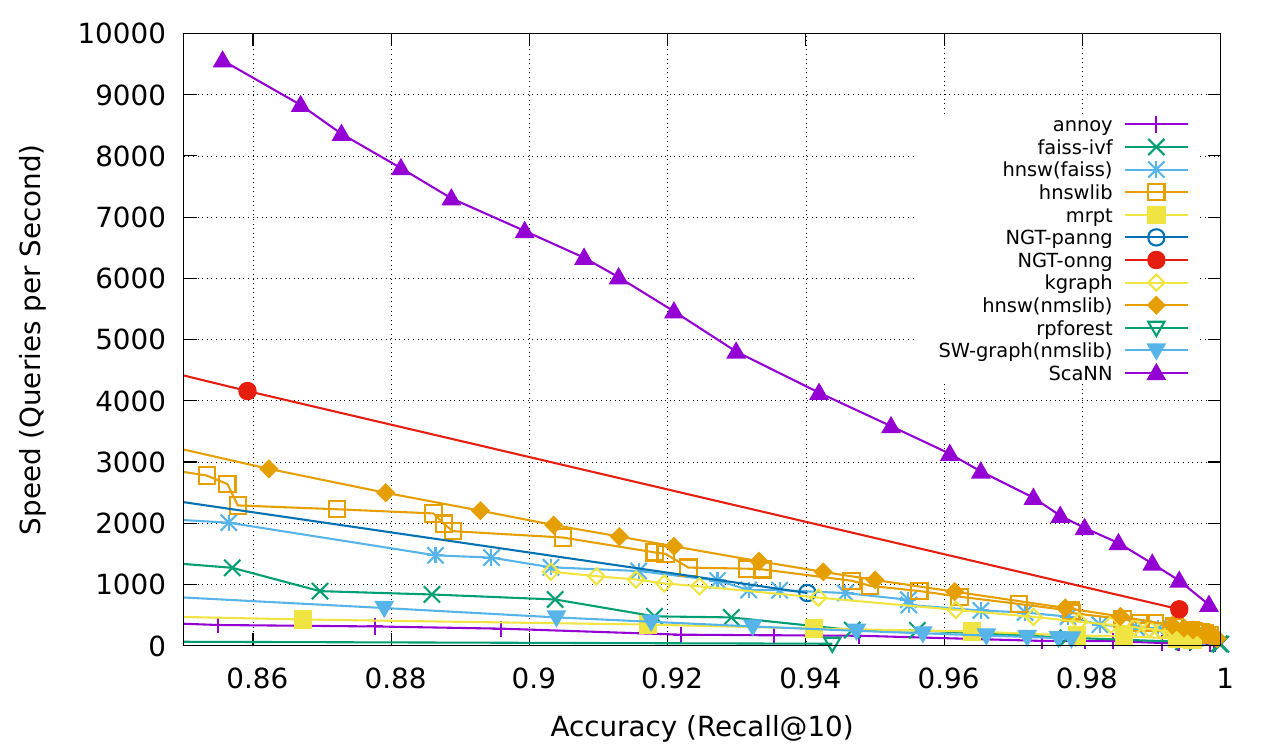
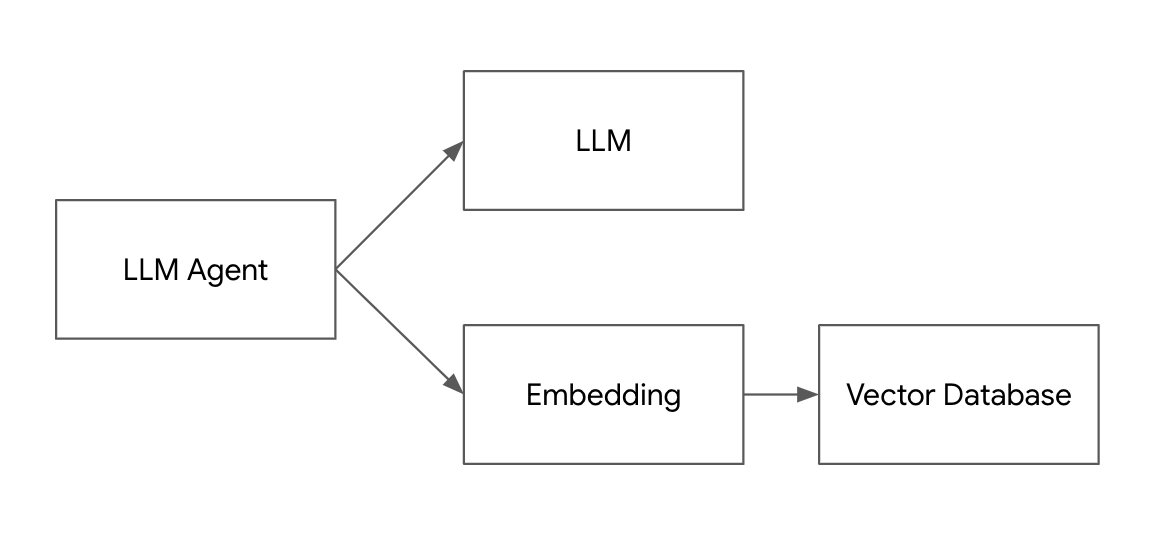
ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #2 - 임베딩과 유사도 검색 조대협 (http://bcho.tistory.com) 앞의 글에서 RAG가 어떻게 작동하는지에 대한 대략적인 개념에 대해서 살펴보았다. 이 글에서는 벡터데이터 베이스가 유사한 문서를 찾아내는 방법인 유사도 검색과, 텍스트등의 데이터를 이 벡터 공간으로 맵핑 시키는 임베딩의 개념에 대해서 알아보도록 한다. 임베딩의 개념 Pinecone 데이터베이스를 이해하기 위해서는 먼저 임베딩이라는 개념을 이해해야 한다. 텍스트를 그냥 데이터 베이스에 저장하는 것이 아니라, 벡터로 바꿔서 저장하는데, 단순하게 해시와 같은 방법으로 맵핑을 하는 것이 아니라 벡터 공간에 의미를 담은 상태로 변환하는 것을 임베딩..