구글 클라우드 로드밸런서를 이용한 인스턴스간 부하 분산
조대협 (http://bcho.tistory.com)
클라우드 VM 생성하는 방법을 숙지 하였으면, 다음으로 여러개의 VM 사이에 부하를 분산할 수 있는 로드밸런서 기능에 대해서 알아보자.
구글의 로드 밸런서는 일반적인 L4 스위치와 같이 일반적인 TCP/UDP 프로토콜에 대한 라우팅이 가능하다.
여기에 더해서
HTTP 프로토콜에 대해서는 HTTPS Termination 뿐만 아니라, HTTP URI에 따라서 가까운 서버나 특정 서버로 라우팅이 가능한 L7과 유사한 기능을 가지고 있다. (자세한 내용은 http://bcho.tistory.com/1111)를 참고
다른 글에서도 여러번 언급했지만, 구글의 클라우드 로드밸런서를 사용하게 되면, 서버로 들어오는 트래픽을 인터넷이 아니라 구글이 전세계에 배포한 엣지 노드중 가장 위치적으로 가까운 노드에 접속을 한 후에, 구글의 광케이블 백본망을 통해서 서버로 트래픽을 전송하기 때문에 네트워크 구간 속도를 획기적으로 줄일 수 있다. (자세한 내용은 http://bcho.tistory.com/1109 참고)
또한 몇가지 재미있는 특징이
Pre-warm up 이 필요 없음
몇몇 클라우드 로드밸런서의 경우에 갑자기 높은 부하가 들어오면 그 부하를 받아내지 못하는 경우가 있다. 이를 방지 하려면 미리 그 만한 부하를 수십분 동안 줘서 로드밸런서의 크기를 키워 주는 Pre-warm up 작업을 하거나 직접 클라우드 업체에 연락을 해서 용량 증설 요청을 해야 한다. 그러나 이러한 방식은 예측하지 못한 부하가 들어왔을 때 대응이 어렵다는 단점이 있고 Pre-warm 이라는 개념을 모르고 있는 사용자의 경우 종종 준비 못한 상황에서 트래픽을 받아내지 못해서 운영상에 문제를 겪는 경우가 종종있다. 구글 클라우드의 로드밸런서는 이러한 제약 사항이 없이 들어오는 부하에 맞춰서 Pre-warm up이 없이 바로 스케링이 가능하다.
리전 레벨의 부하 분산이 가능함
멀티 리전에 백앤드를 배포하였을때, 구글의 클라우드 로드밸런서는 단일 IP주소로 리전간에 로드밸런싱이 가능하다. 로드밸런싱은 클라이언트가 가까운 리전을 우선으로 라우팅을 하고, 만약 리전 장애시에는 다른 리전으로 자동으로 Fail over한다. DNS 라운드 로빈 방식등의 부가적인 방식을 쓰는 것이 아니라 단일 정적 IP를 사용하기 때문에 별다르 설정이 필요 없고, 방화벽 규칙등 인프라 규칙등을 설정하는데 용이 하다.
모든 트래픽에 대해서 Logging이 가능
모든 부하에 대해서 로깅이 가능하다. 보통 로드밸런서의 경우에는 부하량이 많아서 로그를 남기지 않는 경우가 많은데, 외부로 부터의 해킹 시도나 오류가 발생했을때, 맨 앞단의 로드밸런서의 access log가 중요하다. 구글 클라우드의 경우에는 이 모든 Log를 남겨주고 API를 통해서 수집도 가능하기 때문에 차후 분석이 가능하다.

Managed group vs unmanaged group
로드밸런서 설정에 앞서서 managed group과 unmanaged group에 대한 개념을 이해할 필요가 있다.
그룹은 인스턴스의 집합으로, 이 단위로 로드밸런서에 연결할 수 있다.
그룹은 크게 unmanaged group과 managed group 두가지로 정의된다.
Unmanaged group
Unmanaged group 은 인스턴스를 수동으로 묶어 놓은 그룹이다. 인스턴스의 사이즈나 종류에 상관 없이 그냥 묶어 놓는 묶음이다. 수동으로 아무 종류의 인스턴스나 추가해 넣을 수 있기 때문에 오토 스케일링은 불가능하다. Unmanaged group을 이해하려면 반대로 managed group의 개념을 이해하면된다.
Managed group
Managed group의 인스턴스는 사용자가 직접 추가할 수 는 없고, managed group을 만들때, 템플릿을 만들어서 인스턴스 생성을 클라우드가 하게 한다. 템플릿이란 인스턴스를 만들기 위한 붕어빵(틀?)과 같은 건데, VM의 사이즈, OS 이미지등 설정을 미리 정해놓으면, 클라우드가 인스턴스를 생성할때 이 템플릿에 정해진 설정에 따라서 인스턴스를 추가하게 된다. 템플릿 생성은 약간 내용이 길기 때문에 차후에 다른 글에서 따로 설명하도록 한다.
대략적인 특징을 이해했으면, 로드밸런서를 통한 부하 분산 구성을 구현해보자.
Managed group은 템플릿 생성등 절차가 더 복잡하기 때문에, 나중에 따로 설명하기로 하고, 이 글에서는 unmanaged group 기반으로 그룹을 생성해서 부하를 분산하는 구성을 설정한다.
인스턴스 준비하기
먼저 부하를 받을 인스턴스를 구성한다. 간단한 node.js express 웹 애플리케이션을 구성하여 배포한다.
애플리케이션은 / 로 접속했을 경우, 접속한 VM 인스턴스의 IP 정보등을 간단하게 리턴해주는 애플리케이션이다. (아래 “/” 경로에 대한 route 코드 참고)
var router = express.Router();
var os = require('os');
/* GET home page. */
router.get('/', function(req, res, next) {
res.json(os.networkInterfaces());
});
module.exports = router;
코드가 준비되었으면, VM 을 생성하자. lb-test-1 이라는 이름의 인스턴스로 asia-east1-a에 small 타입의 인스턴스로 생성을 하였다.
Allow HTTP traffic 옵션을 ON해서 HTTP 트래픽을 받도록 하였으며, Internal IP와 External IP를 자동 할당하도록 설정하였다.
External IP를 설정한 이유는 로드밸런서가 제대로 작동함을 테스트하기 위해서 로드밸런서를 거친 요청과 로드밸런서를 거치지 않은 요청 둘을 각각 보내서 테스트하기 위함이고, 만약 운영 환경에서 실제로 서비스 할때는 굳이 External IP를 부여할 필요 없이 Internal Ip만 부여하고 외부에서 직접 접근을 차단하고 로드밸런서를 통한 HTTP 접근만을 허용하는 것이 보안상 유리 하다.

추가적인 설정으로는 아래 그림과 같이 management tab에서 Automation의 Startup script에 아래와 같은 Shell 스크립트를 추가한다. Start up 스크립트는 VM이 기동되자 마자 자동으로 수행되는 스크립트로, 이 예제에서는 VM이 기동 된후 자동으로 node.js 인스턴스를 구동하도록 npm start 를 수행하도록 하였다.

VM이 생성되었으면, VM에 node.js 소스코드를 배포 한다. (scp, ftp나 git repository를 사용하건 본인 취향에 맞는 방법으로 복제한다.)
인스턴스 디스크 스냅샷 추출하기
앞에서 만든 인스턴스를 마스터 인스턴스로 같은 내용의 인스턴스를 복제할것인데, 복제를 위해서 디스크를 복제할 필요가 있다. 현재 디스크의 복제본을 “스냅샷"이라는 형태로 떠놓는데, Compute Engine 메뉴에서 snapshots 메뉴로 들어가면 디스크의 스냅샷을 뜰 수 있다.

스냅샷 메뉴로 들어온 후 상단의 CREATE SNAPSHOT 메뉴를 선택한 후, 아래 그림처럼 스냅샷 이름 “restapi-instance-snapshot” 이라는 이름으로 입력하고 Source disk는 앞에서 생성한 lb-test-1 의 디스크를 선택해서 스냅샷을 생성한다.
인스턴스 복제 하기
첫번째 인스턴스를 생성하였으니, 이번에는 부하 분산을 위해 두번째 인스턴스를 생성해보자, 두번째 인스턴스는 첫번째 인스턴스와 동일한 설정을 사용할 것이기 때문에 첫번째 인스턴스를 복제해서 사용한다.
첫번째 인스턴스에 대한 상세 정보에 들어가면 상단에 “CLONE”을 누르면 같은 설정의 인스턴스를 생성할 수 있다.

CLONE을 누르면 다음과 같이 동일 설정으로 인스턴스 생성이 자동으로 진행되는 것을 확인할 수 있다.
이때 디스크 이미지를 앞에서 생성한 lb-test-1과 동일한 이미지를 사용해야 하기 때문에, 앞서 생성한 “rest-instance-snapshot” 이미지를 선택한다.

내 외부 IP 설정도 자동 배정으로 되는 것을 아래 그림과 같이 확인하고

스타트업 스크립트도 동일한지를 확인한다.

접속 확인
로드 밸런서를 테스트할 lb-test-1, lb-test-2 VM이 생성이 되었으면 정상적으로 웹 애플리케이션이 올라왔는지 확인해보자. 예제에서 할당된 주소는 lb-test-1이 외부/내부 IP가 104.155.213.74/10.140.0.4, lb-test-2가 107.167.186.59/10.140.0.5 가 부여되었다.
각각의 외부 IP로 접속해보면 아래와 같이 각각 부여된 내부 IP를 리턴하는 것을 확인할 수 있다.


인스턴스 그룹 생성하기
로드밸런서 테스트를 하기 위한 VM 생성이 모두 끝났다. 이제 로드 밸런서에 이 인스턴스를 연결하기 위해서, 인스턴스들을 그룹으로 묶어 보자.
인스턴스 그룹 생성은 Compute Engine 메뉴에서 Instance groups를 선택한다.

create instance group을 선택한후, unmanaged group 생성을 선택한다.
다음 아래 그림과 같이 instance group 이름을 입력하고, zone은 인스턴스를 생성한 zone과 같은 zone으로 선택한다. 다음 create method에서 앞서 생성한 두개의 인스턴스를 선택할 것이기 때문에, “Select existing instances”를 선택한다.
그리고 VM instances에서 앞에서 생성한 lb-test-1, lb-test-2를 선택하여 추가한다.

이제 로드밸런서에 연결할 인스턴스 그룹이 생성되었다. 이제 로드밸런서를 설정하고, 생성한 그룹을 로드 밸런서에 연결해보자
STATIC IP 할당하기
로드밸런서 설정에 앞서서 로드밸런서에 지정할 정적 IP를 생성하자

위의 그림 처럼 Networking 메뉴에서 External IP addresses를 선택한 후에, 정적 IP 예약 한다. lb-test-ip라는 이름으로 생성하고 타입을 Global 로 선택한다. Regional IP는 특정 Region에만 부여가 가능하고, Global IP는 여러 Region에 걸쳐서 사용할 수 있는 IP 이다. 여기서 예약된 IP는 뒤에 로드밸런서가 생성된 후에, 이 로드밸런서에 부여하게 된다.
로드밸런서 생성
이제 로드밸런서를 설정하기 위한 모든 준비가 끝났다.
로드 밸런서를 생성하기 위해서 Networking에 Load balancing 메뉴로 들어가자.
로드밸런서 생성은 크게 다음과 같은 단계를 통해서 생성이 된다.
프로토콜 선택
백앤드 서비스 설정
Host & Path rule 설정
프론트 앤드 설정
각각의 디테일 내용에 대해서 알아보자
프로토콜 선택
로드밸런서 생성을 시작하면 제일 처음 프로토콜을 선택하게 되는데, HTTP, TCP,UDP 3가지 프로토콜을 지원한다. 이 예제에서는 HTTP 프로토콜을 사용한다.

백앤드 서비스 선택
프로토콜 선택이 끝났으면 백앤드 서비스를 선택하는데, 백앤드 서비스는 앞에서 생성한 인스턴스 그룹이 된다.
참고 : 하나의 로드밸런서에 하나의 인스턴스 그룹을 설정하는 것 뿐 아니라, 동시에 다른 인스턴스 그룹을 각각 다른 백앤드로 정의하여 인스턴스 그룹간의 부하 분산도 가능하다. 두개 이상의 인스턴스 그룹을 이용한 롤링 업그레이드 구성 이런 기능을 이용하면, 두개의 인스턴스 그룹을 만들어서 A,B 그룹으로 부하 분산을 하고, 서버 패치나 배포시 A 그룹을 정지시키고 배포를 한후, 재기동 하고, B 그룹을 정지 시키고 배포를 한후 재 기동 하는 롤링 업그레이드 방식으로 무정지 서비스 배포가 가능하다. 리전간 (또는 존간) 라우팅 구성 또는 아래 그림과 같은 같은 기능의 백앤드를 각각 다른 리전에 배포하면 리전 단위의 장애가 발생하였을때, 정상적인 리전으로 요청을 라우팅하여 리전 단위의 HA (고가용성) 구성이 가능하다. 물론 같은 방식으로 존(ZONE)간의 라우팅을 통한 HA 구성도 역시 가능하다. HTTP URI 기반의 라우팅 HTTP의 URI 또는 호스트명(서로 다른 호스트명도 하나의 로드밸런서로 라우팅이 가능하다)을 기반으로 특정 서버 그룹으로 요청을 라우팅 할 수 있는 기능이다. 일반적인 네트워크 장비인 L4등에서는 구현이 불가능한 기능인데 원리는 단순하다. 아래 그림처럼 /static URL를 갖는 요청은 “static-resources” 라는 서버 그룹으로 라우팅 하고, /video URL을 갖는 요청은 “video-resources”라는 서버 그룹으로 라우팅 하는 식이다. 매우 간단한 기능이기는 하지만 그 활용도가 매우 높다. 웹서버, 스트리밍 서버등으로 컨텐츠 타입에 따라 서버를 나눌 수 도 있지만, 마이크로 서비스 아키텍쳐 (MSA)로 되어 있는 경우, 각 서비스 컴포넌트가 다른 URL을 가지기 때문에, 앞단에 API Gateway와 같이 URL에 따라 라우팅을 해주는 프록시 계층이 필요한데, 구글의 로드밸런서는 이 기능을 지원하기 때문에, 백앤드 서비스가 MSA로 구성되어 있을 경우 이 기능을 유용하게 사용할 수 있다. |
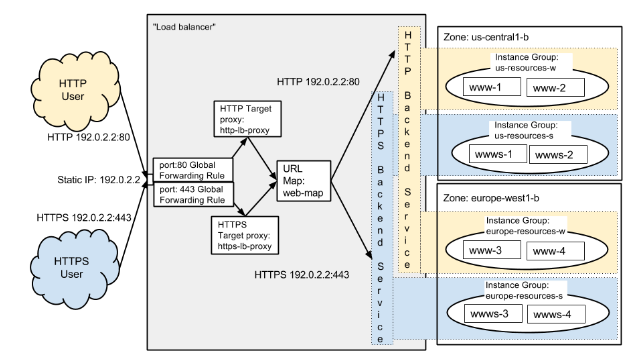
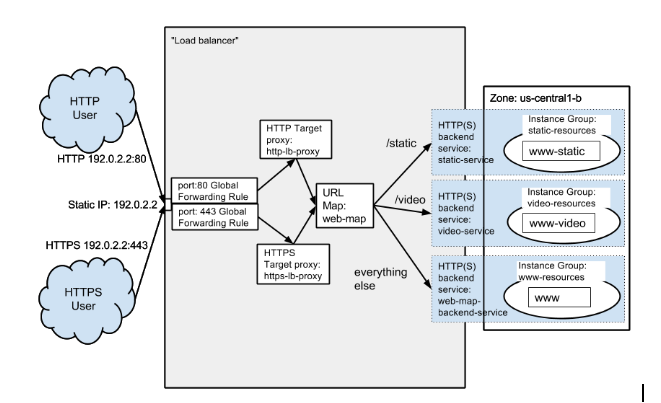
백앤드 서비스의 구성은 백앤드 서비스를 선택하면 기존에 있는 백앤드 서비스를 선택하거나 또는 새로 생성하는 것을 선택할 수 있는데, 여기서는 새로운 백앤드 서비스를 구성한다. 새로운 서비스 생성을 선택하면 아래 그림과 같이 백앤드 서비스의 이름을 입력하고 (여기서는 lb-test-backend 로 구성하였다.) 앞에서 생성한 Instance group인 lb-test-group을 선택하면 된다.
다음으로는 로드밸런서에서 들어온 트래픽을 instance group의 인스턴스들의 어느 포트로 전달할것인지를 “Port numbers”에 정의하는데, 여기서는 HTTP 트래픽을 전달하는 것이기 때문에, 80을 선택한다.

다음으로 하단에 보면 “Health check” 라는 메뉴가 보이고, 선택하게 되어있는데, Health check는 인스턴스 그룹내의 인스턴스가 양호한지를 체크하고, 만약에 정상적이지 않으면 비정상 노드는 부하분산에서 빼버리는 기능을 수행한다. Health check에 대한 설정을 하지 않았기 때문에, 새로 생성하기를 선택하면 아래와 같은 화면이 출력된다.

새롭게 생성하는 Health check의 이름을 입력하고, Health check 방식을 그 아래에 입력한다.
Protocol은 HTTP를 사용하기 때문에 HTTP를 입력하고, Port에는 HTTP 포트인 80포트 (실제 VM Instance에서 HTTP 80포트를 이용하여 서비스를 제공한다.) 그리고 서비스가 정상인지를 확인하는 URL을 /로 입력하였다.
이렇게 입력하면 로드밸런서는 백앤드 서비스내의 인스턴스에 http://xxx.xxx:80/ 로 HTTP 요청을 보내고 요청이 HTTP 200 OK로 리턴되면 정상이라고 판단한다. 이 체크 주기를 조정할 수 있는데, 아래 Health check criteria 에서 정의 한다. Check Interval은 체크 주기이고, Timeout은 이 시간(초)내에 응답이 없으면 장애라고 판단을 한다.
여기서는 하나의 백앤드 서비스만 구성을 했지만 앞의 ‘참고'에서 설명한 바와 같이 하나의 로드밸런서에 여러개의 백앤드 서비스를 구성하여 연결할 수 있다.
Host & Path rule 설정
Host & Path는 앞의 참고에서 설명한 것과 같이 HTTP 요청의 호스트명( photo.example.com , api.example.com)에 따라 백앤드 서비스로 라우팅을 하는 규칙을 설정하는 것과 HTTP URI를 기반으로 라우팅 규칙을 설정하는 단계로, 여기서는 모든 트래픽을 모두 한 백앤드 서비스로 라우팅을 할것이기 때문에 host나 URI 부분에 별도의 규칙을 명기하지 않고 비워놓은 상태에서 앞서 생성한 lb-test-backend 백앤드 서비스를 지정한다.

프론트앤드 설정
맨 마지막으로 프론트 앤드 서비스를 설정하는데, 여기서는 어떤 프로토콜을 어떤 IP와 포트로 받을 것인지, HTTPS의 경우에는 SSL Certificate (인증서)를 설정하는 작업을 한다.
여기서는 HTTP 프로토콜을 80 포트로 설정하기 때문에 아래와 같이 설정하고, IP는 앞에서 할당한 정적 IP 인 lb-test-ip 를 할당한다.

모든 설정이 완료되었다.
테스트
모든 설정이 완료 되었기 때문에 테스트를 진행해보자. 테스트를 바로 진행하면 아래와 같은 화면이 뜰 것이다.

로드밸런서가 초기 셋업되는 시간까지 약 30초정도 시간이 걸린다. 30 초 정도 후에 로드 밸런서의 주소 (이 예제의 경우 130.211.8.67)로 해보면 다음과 같이 앞에서 앞에서 생성한 10.140.0.4 와 10.140.0.5로 번갈아가면서 부하가 분산이 됨을 확인할 수 있다.


다음에는 managed group을 이용한 auto scale out 방법에 대해서 소개하도록 한다.
'클라우드 컴퓨팅 & NoSQL > google cloud' 카테고리의 다른 글
| 구글 클라우드의 대용량 분산 큐 서비스인 Pub/Sub 소개 #1 (2) | 2016.07.13 |
|---|---|
| 오토 스케일 아웃(Auto scale out)을 사용해 보자 (1) | 2016.06.13 |
| 다양한 라우팅 기능을 제공하는 구글의 클라우드 로드 밸런서 (2) | 2016.06.02 |
| 구글 클라우드 플랫폼 제품 소개 (0) | 2016.06.01 |
| 구글 클라우드 생성하기 - VM 생성과 접속 (7) | 2016.05.31 |