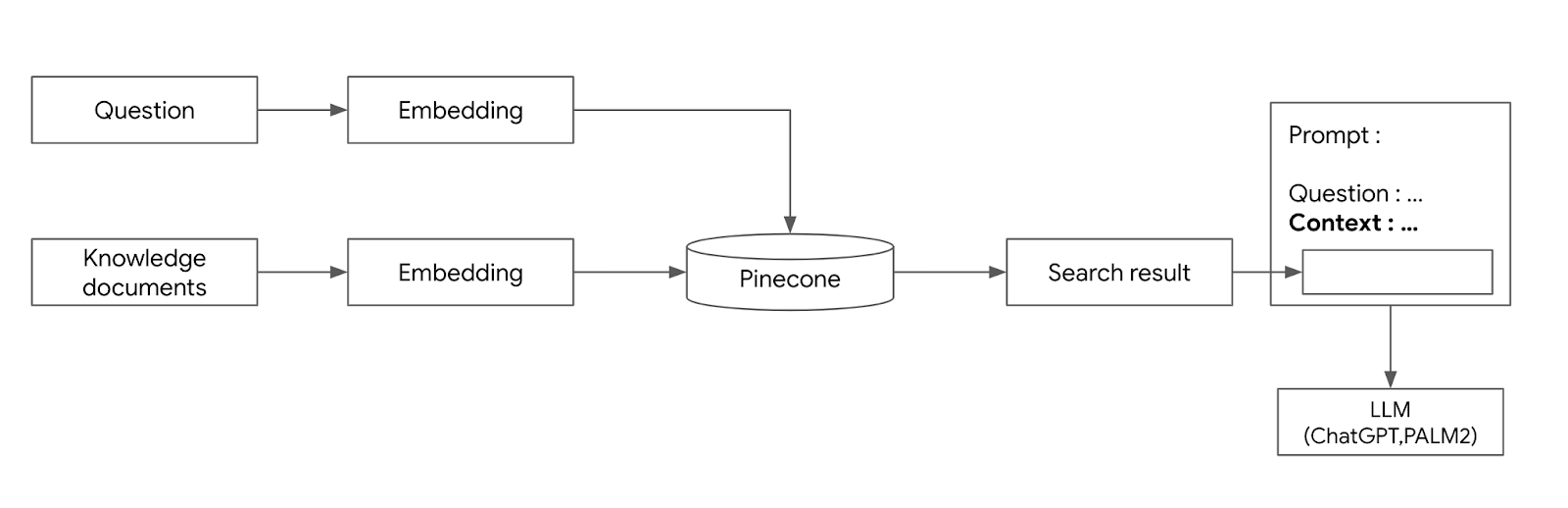
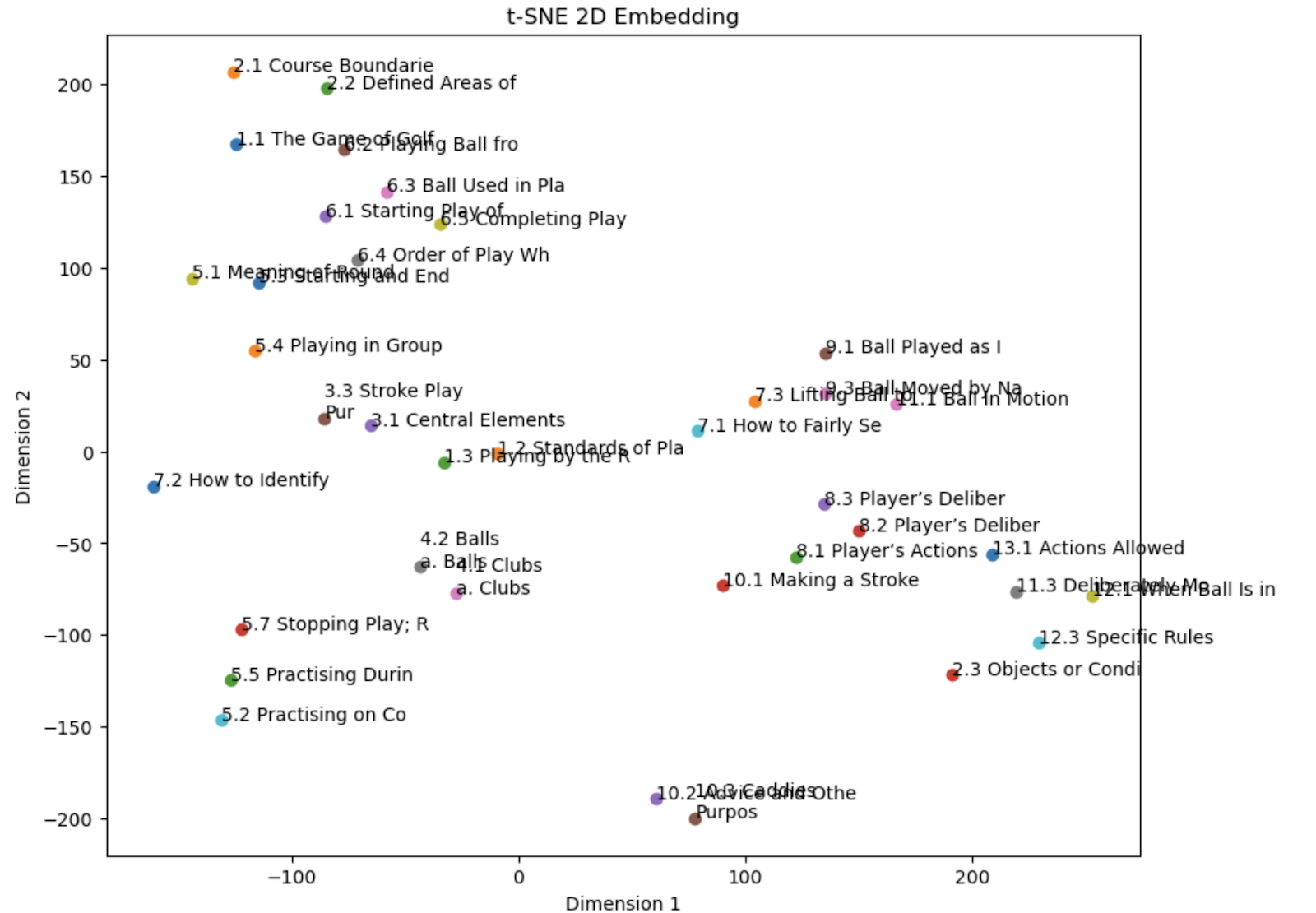
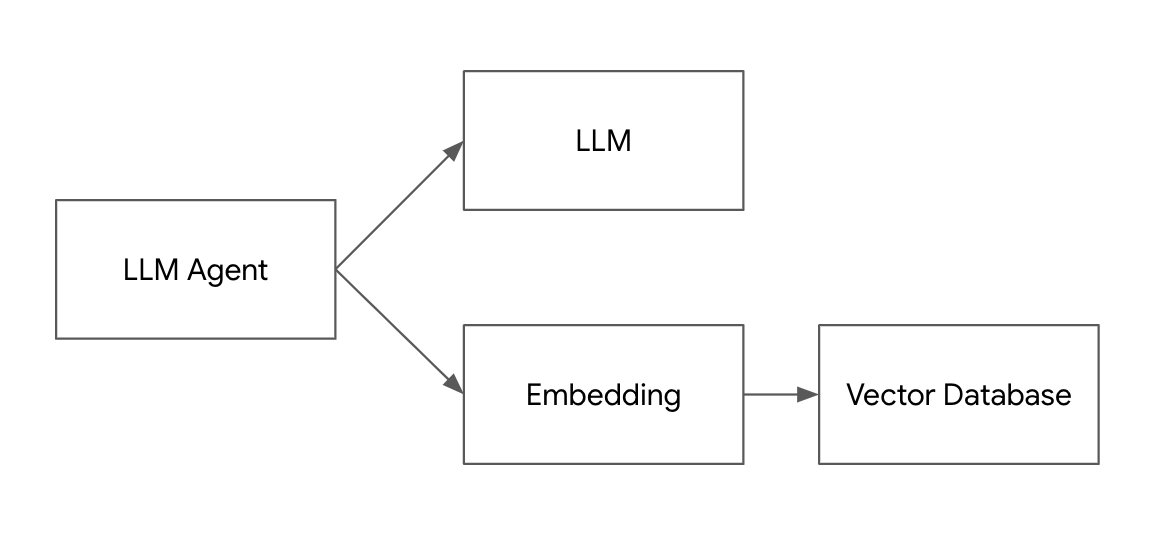
ChatGPT에서 Pinecone 에 저장된 문서를 기반으로 답변하기 조대협 (http://bcho.tistory.com) 지난 글에서 간단한 Pinecone의 사용방법에 대해서 알아보았다. 이번글에서는 텍스트를 임베딩하여 Pinecone에 저장하고, 이를 검색하는 방법에 대해서 소개한다. import pinecone import os import openai # Set your OpenAI API key openai.api_key = "{your API Key}" input_directory = "./golf_rule_paragraph" def extract_info_from_file(file_path): with open(file_path, 'r', encoding='utf-8') as file: #..