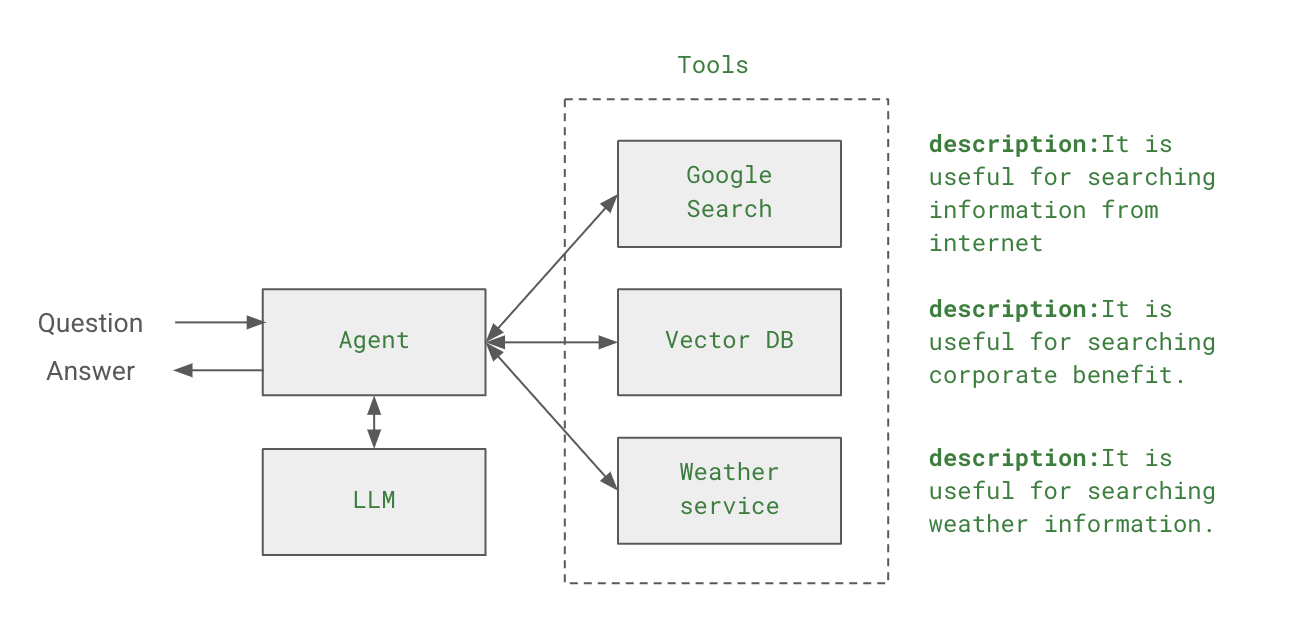
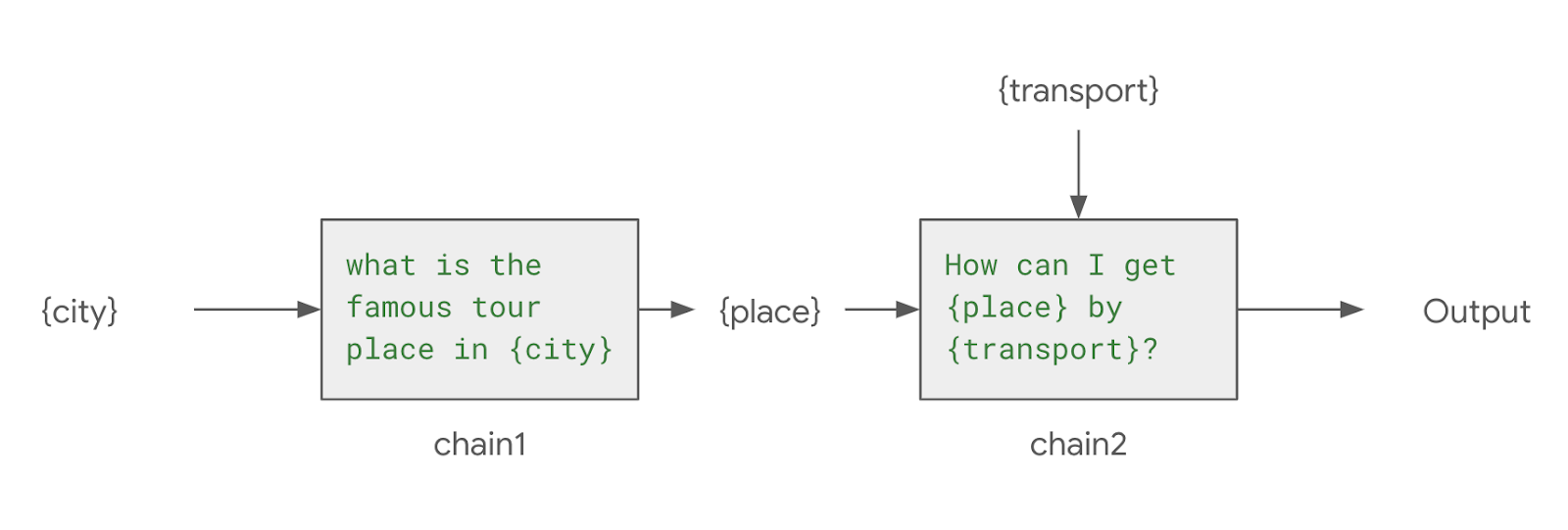
앞의 예제는 agent를 생성할때 initialize_agent를 사용하는 방식으로 Langchain 0.1.0 까지는 지원하지만 deplicate 될 예정이고 새 버전의 create_react_agent 함수를 사용하기를 권장하고 있다. create_react_agent를 사용하려면 직접 agentExecutor도 선언해야 하고, 프롬프트도 정의해야하기 때문에 기존 방식에 비해서 다소 번거롭지만 좀 더 많은 컨트롤을 할 수 있다. 이번에는 create_react_agent를 이용하는 방식을 설명하면서 내부적으로 agent가 어떻게 동작하는지를 자세하게 살펴보고, 더불어서 langsmith 모니터링 툴을 이용하여, agent에서 내부의 동작을 어떻게 모니터링하고 추적하는지에 대해서 알아보록 한다. Lan..