
ChatGPT에서 Pinecone 에 저장된 문서를 기반으로 답변하기
조대협 (http://bcho.tistory.com)
지난 글에서 간단한 Pinecone의 사용방법에 대해서 알아보았다.
이번글에서는 텍스트를 임베딩하여 Pinecone에 저장하고, 이를 검색하는 방법에 대해서 소개한다.
import pinecone
import os
import openai
# Set your OpenAI API key
openai.api_key = "{your API Key}"
input_directory = "./golf_rule_paragraph"
def extract_info_from_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
# 파일의 첫 줄을 읽어옴
first_line = file.readline().strip()
# 숫자와 제목 추출
number, title = first_line.split(' ', 1)
# maintext 변수에 나머지 텍스트 저장
maintext = file.read()
# 결과를 튜플로 반환
return number, title, maintext
# create pinecone connection
pinecone.init(api_key="{your pinecone api key}", environment="gcp-starter")
pinecone.create_index("golfrule",dimension=1536,metric="cosine")
index = pinecone.Index("golfrule")
# 디렉토리 내 모든 파일에 대해 작업 수행
for filename in os.listdir(input_directory):
file_path = os.path.join(input_directory, filename)
if os.path.isfile(file_path):
# 임베딩하는 부분
number, title, maintext = extract_info_from_file(file_path)
embedding = openai.Embedding.create(
model = "text-embedding-ada-002",
input = maintext
)
embedded_text = embedding['data'][0]['embedding'] #embedding with 1536 dim
# 메타데이터와, 원본 텍스트, 임베딩된 텍스트를 같이 저장
index.upsert([(number,embedded_text,{"title":title,"text":maintext})])
위의 코드는 text_embedding-ada-002 모델을 이용하여, 골프 규칙을 임베딩한후에, 메타 데이터와 함께 저장하는 코드인데,
index.upsert([(number,embedded_text,{"title":title,"text":maintext})])
먼저 number를 id로 하고, embedded_text를 저장하였다. 앞의 예제에 비해서 추가된 부분이 메타 데이터를 저장하는 부분인데, tilte과 text를 메타 데이터로 저장하였다. pinecone의 저장 value는 임베딩 데이터이다. 그래서 검색에서 결과 문서를 찾아내더라도 임베딩된 값을 리턴하기 때문에, 이 임베딩 값은 사람이 이해할 수 없고 그래서 사용할 수 없다. 그래서 메타데이터에 원본 문서와 제목을 같이 저장하였다.
메타 데이터는 이렇게 추가 정보를 저장하는데 사용될 수 도 있지만, 검색 필터링에도 사용된다.
예를 들어 년도를 메타 데이터에 저장해놓고, 년도별 검색을 한다던가 또는 주소에서 “도"를 저장해놓고, “도"별로 검색할 수 있다.
You attended falcon - architecture discovery training program.

참고 : 위의 코드에서는 golfrule이라는 인덱스를 생성하는 부분이 있다. 처음 실행후 두번째 실행 부터는 이미 인덱스가 있기 때문에, 에러가 날 수 있으니, 두번째 실행 부분 부터는 create_index 부분을 제외하고 실행하기 바란다.
위의 예제에서 사용한 텍스트 파일은 각 파일이 하나의 골프 규칙에 따라서 정의된 문서들이다.
- 즉 하나의 파일이 여러개의 문장을 포함하고 있기 때문에, 여러개의 문장을 하나의 벡터로 임베딩 시키면 내용의 디테일이 희석될 수 있다.
- 이 예제는 파일단위로 임베딩을 했지만 일반적으로 텍스트파일은 하나의 큰 파일에 저장되는 경우가 많은데, 그러면 이 파일을 여러개의 chunk로 잘라낸 후에 임베딩을 해야 한다. 이때 어떻게 하나의 파일을 여러개의 조각으로 자르는지가 매우 중요하다. 문장 단위로 자를 수 도 있고, 문단 단위로 자를 수도 있고, 같은 의미를 가지고 있는 문장을 묶어서 자를 수 도 있는데, 이를 chunking strategy라고 한다. RAG에서 중요한 부분중에 하나는 어떤 Chunking strategy를 사용하는가인데, 이 부분은 추후에 별도의 글에서 서술하도록 하겠다.
성능
위의 예제는 간단하게 이해를 돕기 위해서 for 루프를 돌면서 upsert로 하나하나 레코드를 insert했지만, 사실 데이터베이스에서 대량의 레코드를 하나씩 입력하는 것은 성능면에서 좋지 않다. 아래는 Insert 성능을 향상 시키기 위한 몇가지 팁이다.
배치 Insert
먼저 하나씩 레코드를 삽입하는 것이 아니라, 하나의 콜에서 여러개의 레코드를 동시에 삽입할 수 있도록 배치 Insert를 사용한다. 아래 코드는 하나의 콜에서 100개의 배치 단위로 insert 하는 예제이다.
import random
import itertools
def chunks(iterable, batch_size=100):
"""A helper function to break an iterable into chunks of size batch_size."""
it = iter(iterable)
chunk = tuple(itertools.islice(it, batch_size))
while chunk:
yield chunk
chunk = tuple(itertools.islice(it, batch_size))
vector_dim = 128
vector_count = 10000
# Example generator that generates many (id, vector) pairs
example_data_generator = map(lambda i: (f'id-{i}', [random.random() for _ in range(vector_dim)]), range(vector_count))
# Upsert data with 100 vectors per upsert request
for ids_vectors_chunk in chunks(example_data_generator, batch_size=100):
index.upsert(vectors=ids_vectors_chunk) # Assuming `index` defined elsewhere
코드 출처 : https://docs.pinecone.io/docs/insert-data#batching-upserts
병렬 Insert
다음은 데이터 입력을 싱글 쓰레드가 아니라 멀티 쓰레드를 이용하여 병렬 처리를 할 수 있다. 병렬 입력은 위에서 언급한 배치와 같이 사용이 가능하다. 다음은 병렬로 입력하는 예제이다.
index = pinecone.GRPCIndex('example-index')
def chunker(seq, batch_size):
return (seq[pos:pos + batch_size] for pos in range(0, len(seq), batch_size))
async_results = [
index.upsert(vectors=chunk, async_req=True)
for chunk in chunker(data, batch_size=100)
]
# Wait for and retrieve responses (in case of error)
[async_result.result() for async_result in async_results]
코드 출처 : https://docs.pinecone.io/docs/insert-data#batching-upserts
문서 검색
문서를 임베딩해서 저장했으면, 질문에 대한 답변을 가지고 있는 문서를 검색하는 코드를 만들어보자.
질문 문자열을 임베딩한 후에, 질문 임베딩 값과 pinecone에 저장되어 있는 문서간의 유사도를 측정하여 유사도가 높은 3개의 문서를 검색한후에, 해당 레코드에서 원본 문서와 제목을 추출하여 출력하는 코드이다.
# 질의할 질문
question = "What happens when a golf ball hits someone else and changes course?"
#질의할 질문을 임베딩한다.
embedding = openai.Embedding.create(
model = "text-embedding-ada-002",
input = question
)
embedded_question = embedding['data'][0]['embedding'] #embedding with 1536 dim
#임베딩한 질문으로, 유사한 문서 3개를 찾는다.
query_result=index.query(
vector=embedded_question,
top_k=3,
include_values=False,
include_metadata=True
)
#print(query_result.matches[0])
result_ids = [ result.id for result in query_result.matches]
# 결과를 출력한다.
for result in query_result.matches:
id = result.id
text = result.metadata['text'] #문서의 원본 텍스트
title = result.metadata['title'] #문서의 제목
score = result.score #문서의 유사도
print(id,score,title)
print("\n")
print(text)
print('='*10)
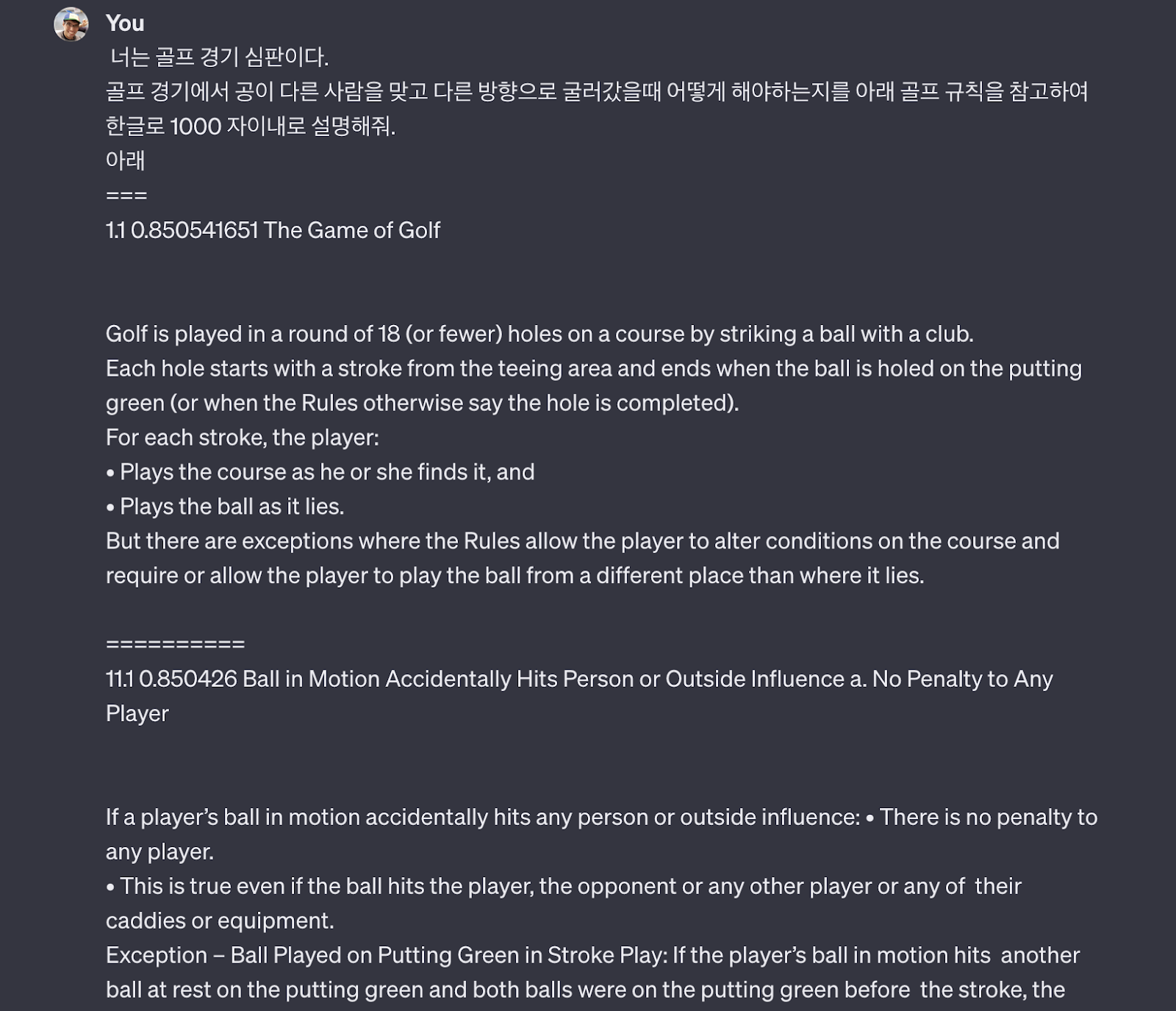
위의 예제에서는 "What happens when a golf ball hits someone else and changes course?" “골프
경기에서 공이 다른 사람을 맞고 다른 경로로 굴러갔을때 어떻게 해야하나?”에 대한 질문이다.
아래와 같은 결과들을 얻을 수 있었다.
1.1 0.850541651 The Game of Golf
Golf is played in a round of 18 (or fewer) holes on a course by striking a ball with a club.
Each hole starts with a stroke from the teeing area and ends when the ball is holed on the putting green (or when the Rules otherwise say the hole is completed).
For each stroke, the player:
• Plays the course as he or she finds it, and
• Plays the ball as it lies.
But there are exceptions where the Rules allow the player to alter conditions on the course and require or allow the player to play the ball from a different place than where it lies.
==========
11.1 0.850426 Ball in Motion Accidentally Hits Person or Outside Influence a. No Penalty to Any Player
If a player’s ball in motion accidentally hits any person or outside influence: • There is no penalty to any player.
• This is true even if the ball hits the player, the opponent or any other player or any of their caddies or equipment.
Exception – Ball Played on Putting Green in Stroke Play: If the player’s ball in motion hits another ball at rest on the putting green and both balls were on the putting green before the stroke, the player gets the general penalty (two penalty strokes).
b. Ball Must Be Played as It Lies
If a player’s ball in motion accidentally hits any person or outside influence, the ball must be played as it lies, except in two situations:
Exception 1 – When Ball Played from Anywhere Except Putting Green Comes to Rest on Any Person, Animal or Moving Outside Influence: The player must not play the ball as it lies. Instead, the player must take relief:
• When Ball Is Anywhere Except on Putting Green. The player must drop the original ball or another ball in this relief area (see Rule 14.3):
⮚ Reference Point: The estimated point right under where the ball first came to rest on the person, animal or moving outside influence.
⮚ Size of Relief Area Measured from Reference Point: One club-length, but with these limits:
: <중략>
LLM에서 RAG 아키텍처
지금까지 pinecone에 문서를 저장하고, 이 문서를 검색하는 방법에 대해서 알아보았다. 그러면 ChatGPT와 같은 LLM에서는 이 문서 검색을 어떻게 통합해야할까?
아래는 프롬프트 예제이다.
아래와 같이 검색된 문서의 결과를 프롬프트내에 {컨택스트}로 삽입하여, 해당 문서 내용을 참고하게 해서 답변을 하도록 하면 된다.
아래는 검색된 결과를 참고하여 chatgpt가 생성한 결과이다.

이 구조를 정리하자면 다음 그림과 같다.
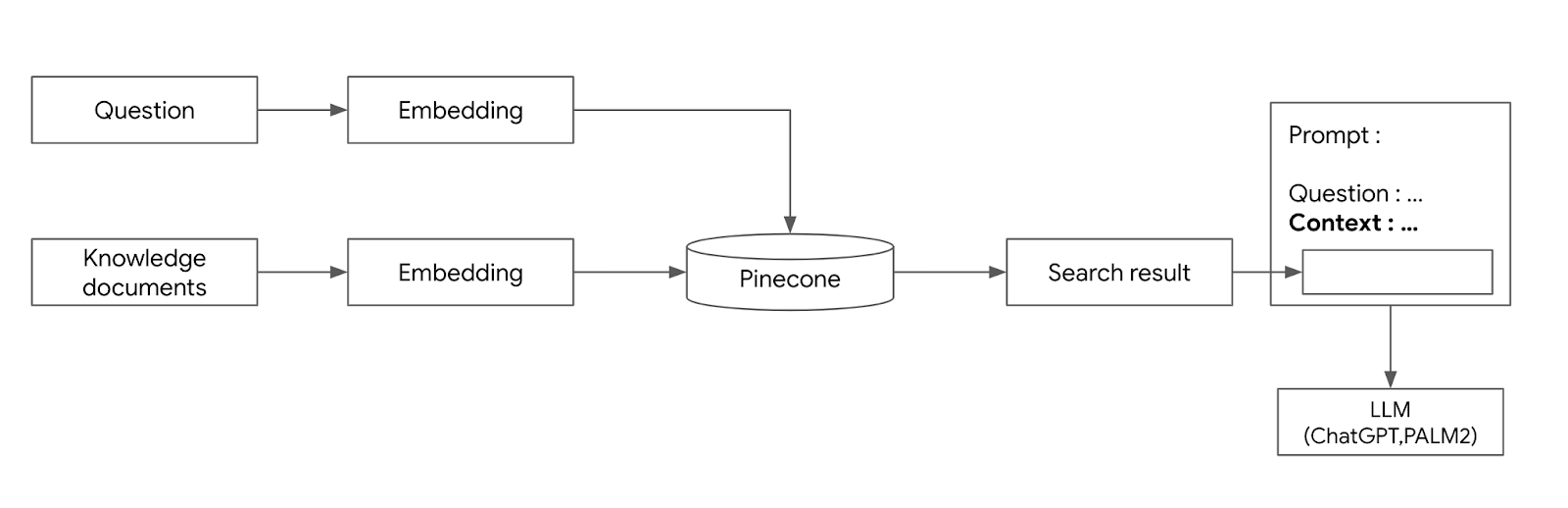
- 먼저 Knowledge document들은 임베딩해서 Pinecone에 저장한다.
- 검색 질의를 입력받고, 질의 내용을 임베딩하여 pinecone에서 검색한다.
- 검색된 문서들을 context로 해서 프롬프트내에 서술하고, 이 프롬프트를 이용하여 LLM에 질문을 한다.
이 예제에서는 문서 검색 부분 까지만 구현을 하였는데, ChatGPT에 API로 컨택스트를 넣어서 호출하는 방법은 어렵지 않으니 생략하기로 한다. 이런 RAG 통합 구현은 ChatGPT와 같은 LLM API를 직접 호출하는 방식도 있지만 LLM 개발을 위한 Langchain과 같은 프레임웍을 사용하면 조금 더 쉽게 구현할 수 있다. 다음번에 기회가 있을때 Langchain에 대해서도 소개하도록 하겠다.