
ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone
#3 Pinecone 둘러보기
조대협 (http://bcho.tistory.com)
Pinecone은 클라우드 매니지드 벡터 데이터 베이스로 구글,Azure,AWS 클라우드를 모두 지원한다. 여러가지 인스턴스 타입이 있으며, 최대 4천만 벡터까지 저장이 가능하다.
개발/테스트를 위한 프리티어가 있고 API키만 발급 받으면 손쉽게 사용할 수 있기 때문에, Langchain, ChatGPT와 함께 많이 사용되고 있다. 오늘은 Pinecone을 사용하는 방법에 대해서 알아보도록 한다.
먼저 pinecone.io 사이트에 접속해서 우측 상단의 Sign up 메뉴를 이용하여 회원 가입을 한후에, 사이트에 로그인한다.

로그인 후에 처음 할일은 인덱스 (pinecone안의 데이터베이스)를 생성해야 한다.
하나의 pinecone 데이터베이스 안에 여러가지 용도의 데이터베이스(인덱스)를 생성할 수 있다. 예를 들어 HR Q&A용 데이터베이스 인덱스, 영업 가이드 문서 용 인덱스 등등이다.
아래 그림과 같이 초기 메뉴에서 “Create Index”를 선택한다.
다음으로 아래 그림과 같이 메뉴가 나오면
데이터 베이스 이름은 quickstart3d로 하였다. 여기에 저장할 벡터는 3차원 벡터를 사용할 예정이기 때문에, 3차원으 Dimension을 설정하였다. 유사도 측정 알고리즘은 유클리디안 거리, 코사인 유사도, 벡터의 내적등을 사용할 수 있는데, 여기서는 유클리디안 거리를 선택하였다.
Pod 타입은 인스턴스의 사이즈를 결정하는 메뉴로, 무료 티어를 사용할 예정이기 때문에, Starter를 선택하였다. 아래는 인스턴스가 생성된 환경이다.
디폴트 무료 티어이기 때문에, Provider가 구글 클라우드로 선택되었고, us-central1 리전이 선택되었다.
그리고 환경 이름은 “gcp-starter”이다.
이제 pinecone에 데이터를 저장할 준비가 되었다.
다음 파이썬 개발환경으로 가서 pinecone의 client sdk를 pip명령을 이용하여 설치 한다.
!pip install pinecone-client
코드에서 pincone 클라이언트를 초기화 하는데, 아래 그림에서와 같이 apikey의 environment이름을 명시한다. Environment 명은 위에서 index를 생성할때 자동으로 할당되었고 이름은 gcp-starter였다.
apikey는 pinecone 콘솔의 좌측 메뉴에 보면 “API Keys” 메뉴에서 apikey를 생성할 수 있다.
아래는 클라이언트에서 연결하고 현재 있는 인덱스들의 목록을 출력하는 것이다. 앞에 콘솔에서 quickstart3d라는 이름으로 인덱스를 하나 생성하였기 때문에, [‘quickstart3d’]가 출력될것이다.
import pinecone
pinecone.init(api_key="{API KEY}", environment="gcp-starter")
pinecone.list_indexes()
pinecone에 저장할 테스트 데이터를 정의한다.
import matplotlib.pyplot as plt
data = [
("A", [0.1, 0.1, 0.1]),
("B", [0.2, 0.2, 0.2]),
("C", [0.3, 0.3, 0.3]),
("D", [0.4, 0.4, 0.4]),
("E", [0.5, 0.5, 0.5]),
("QV", [0.1, 0.1, 0.6]),
]
# 데이터 전처리: 레이블과 3차원 값 추출
labels = [item[0] for item in data]
values = [item[1] for item in data]
# 3차원 그래프 설정
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 데이터 포인트에 레이블 추가
for i, label in enumerate(labels):
x, y, z = values[i]
if label == "QV":
ax.scatter(x, y, z, label=label, marker='^', s=110) # 삼각형 모양, 크기 2배
ax.text(x, y, z, label)
else:
ax.scatter(x, y, z, label=label)
ax.text(x, y, z, label)
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.set_title('3D Plot')
# 범례 추가
ax.legend()
plt.show()
3차원 벡터 A,B,C,D,E를 생성하였고, QV 벡터는 쿼리를 할 벡터로 QV 벡터와 유사한 벡터를 A,B,C,D,E에서 찾아낼 것이다.
위의 코드 블럭을 실행하면 아래와 같이 3차원 공간에서 A~E,QV 벡터를 출력해줄 것이다.
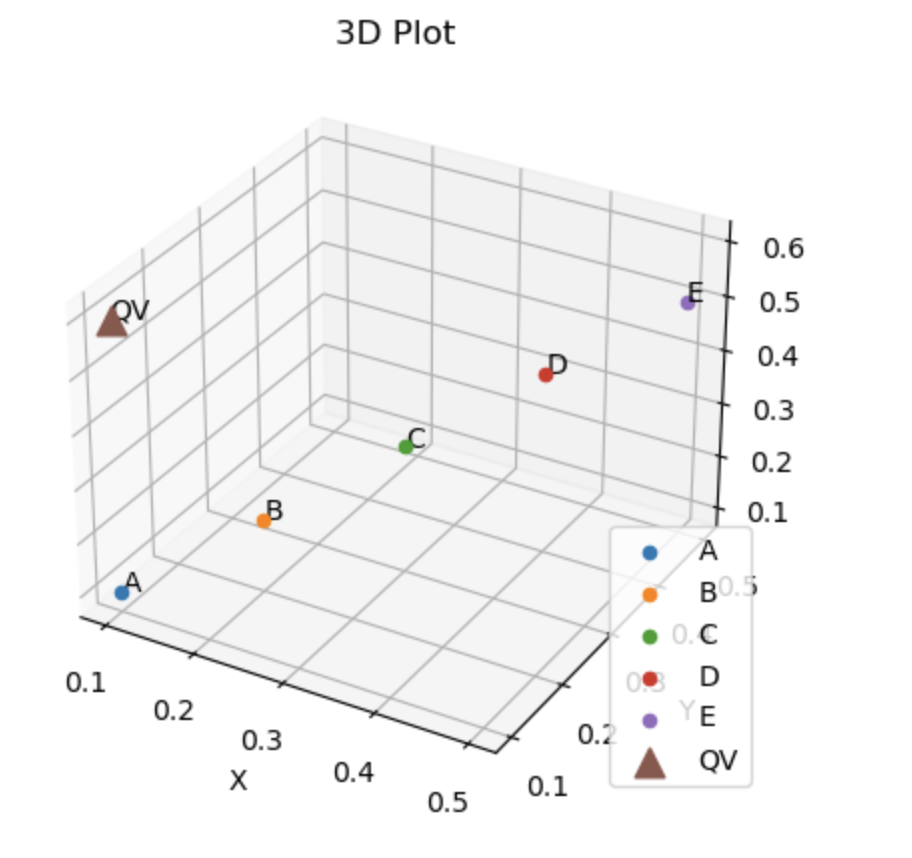
다음 Pinecone에 데이터를 저장할것인데, pinecone.Index를 이용하여 quickstart3d Index의 레퍼런스를 얻어온 후에, upsert 를 이용하여 A,B,C,D,E 벡터를 저장하였다.
index = pinecone.Index("quickstart3d")
index.upsert(data[:4])
index.describe_index_stats()
이렇게 저장된 벡터에서 QV 와 가까운 벡터를 쿼리한다. 이때 top_k=3으로 줌으로써, 리턴값을 최대 3개만 리턴하도록 하였다.
query_result=index.query(
data[5][1],
top_k=3,
include_values=True
)
print(query_result)
결과는 다음과 같다.
{'matches': [{'id': 'C', 'score': 0.17094484, 'values': [0.3, 0.3, 0.3]},
{'id': 'B', 'score': 0.180629909, 'values': [0.2, 0.2, 0.2]},
{'id': 'D', 'score': 0.221259832, 'values': [0.4, 0.4, 0.4]}],
'namespace': ''}
C,B,D가 QV 벡터와 가장 유사한것으로 리턴하였고, score가 작을 수록 유사한 벡터이기 때문에 C,B,D 순으로 유사하다.
오늘은 간단하게 pinecone의 사용방법에 대해서 알아보았고, 다음 글에서는 pinecone의 데이터 구조등에 대해서 살펴보도록 한다.
'빅데이타 & 머신러닝 > 생성형 AI (ChatGPT etc)' 카테고리의 다른 글
| ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #5 ChatGPT에서 Pinecone 에 저장된 문서를 기반으로 답변하기 (0) | 2023.11.21 |
|---|---|
| ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #4 텍스트 임베딩하기 (1) | 2023.11.16 |
| ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #2 - 임베딩과 유사도 검색 (1) | 2023.11.09 |
| ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #1 (0) | 2023.11.09 |
| VAE를 통해서 본 이미지 생성 모델의 원리 (0) | 2023.11.03 |