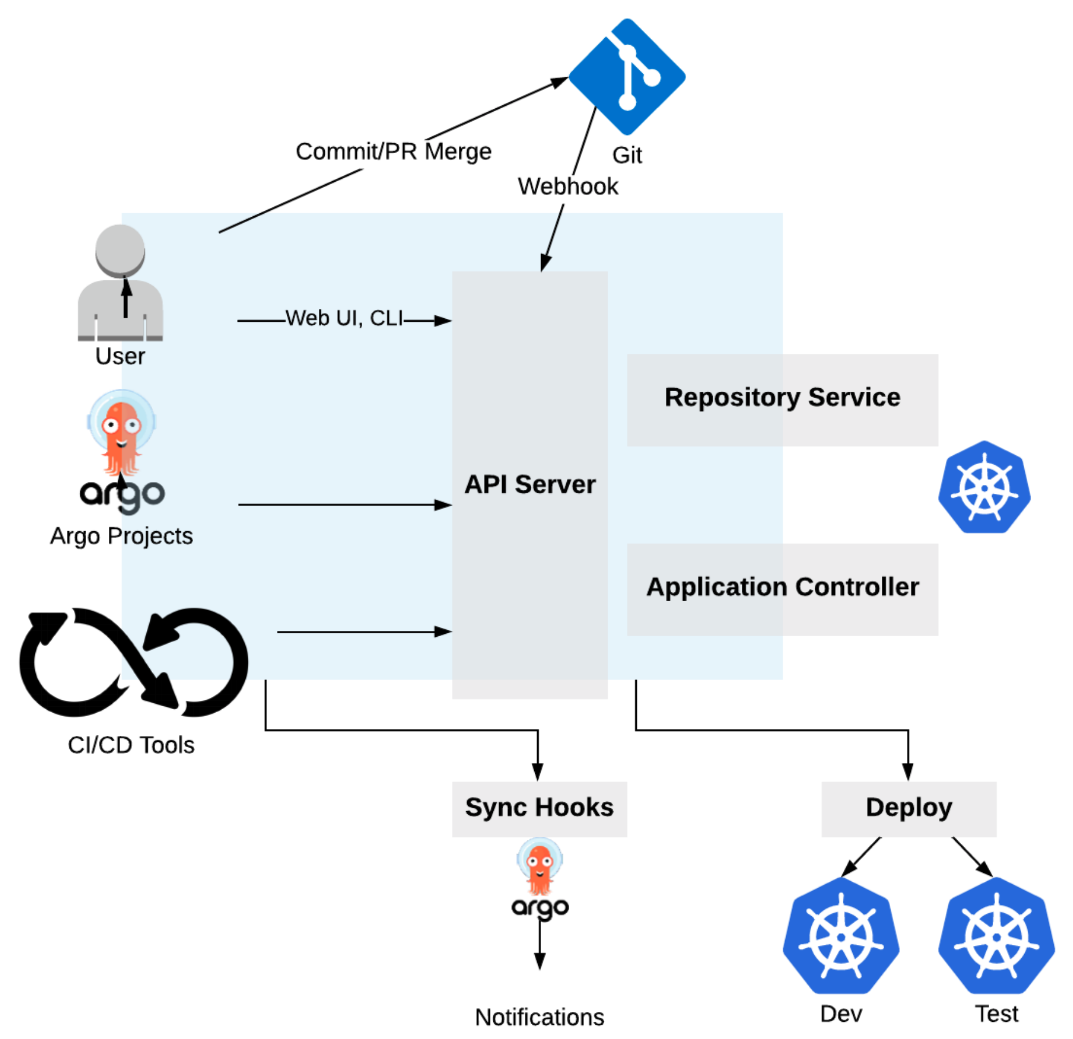
정명훈 (구글 클라우드)IT에서의 효율성IT에서 효율성을 얻을 수 있는 최고의 방법은 무엇일까? 반복과 재사용이다. 아날로그 현실 세계와 달리 디지털 기반의 IT 세계에서는 동일한 결과물을 만드는 것이 매우 쉽다. 친구나 동료가 말한 목소리를 기억하고 전달하는 아날로그 방식은 내용을 빼먹기도 하지만, 디지털로 남겨지는 스마트폰 녹음은 10년이 지나도 그대로 전달할 수 있다. 한 번 녹음된 디지털 음성은 10개를 복제하던 100개를 복제하던 품질이 그대로 유지된다. IT 발전의 역사는 반복과 재사용을 통한 효율화의 역사이다. 어떻게 하면 하드웨어 또는 소프트웨어를 모듈 단위로 만들어 재사용할 수 있게 고민한다. 함수를 통해서, 컴포넌트를 통해서 그리고 API를 통해서 소프트웨어를 재사용한다. 인텔과 AM..