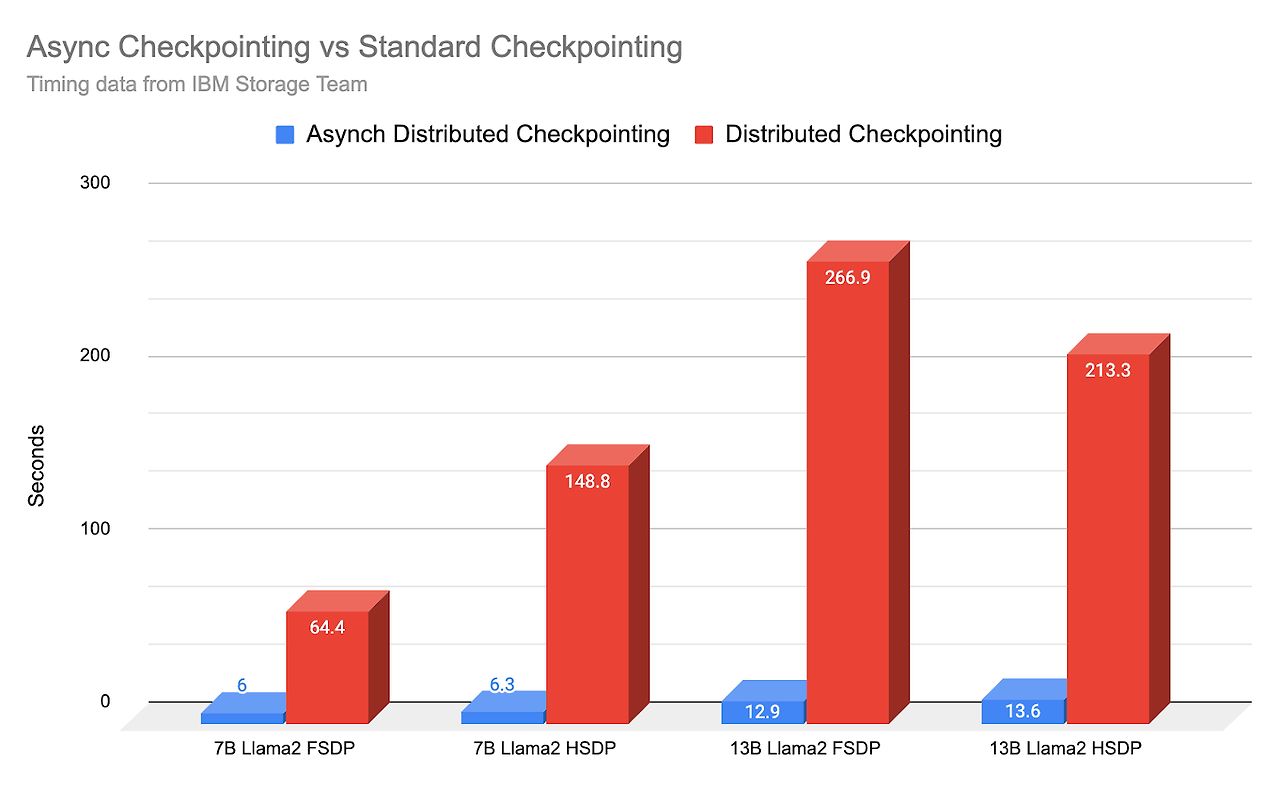
대규모 분산 학습에서 고려할 사항조대협 (http://bcho.tistory.com) 그러면 실제로 분산 학습은 어떻게 이루어질까, 하나의 머신에서 여러 GPU를 사용하는 멀티 GPU의 경우에는 코드만 싱글 GPU 코드와 다르지 다른 설정은 다르지 않다. 그러나 멀티 머신 학습의 경우에는 각 머신에서 학습 코드를 실행해줘야 하고, 같은 데이터 소스로 부터 데이터를 각 머신에서 읽어와야 한다. 그렇다면 동시에 여러 머신에 학습 코드를 어떻게 실행할까?스케쥴러수동으로, 특정 서버에서 각각 학습 코드를 실행할 수 도 있지만, 보통 수십,수백개의 머신에서 하나의 학습만을 돌리는 일은 드물다. 중간 중간 실험을 위해서 작은 모델을 학습하기도 하고, 전체 머신들에서 하나의 거대 모델들을 돌리기도 한다. 만약 50..