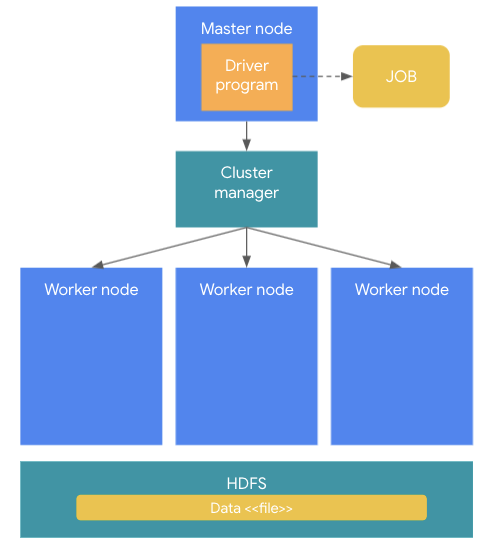
Apache Spark의 개념 이해 #1 기본 동작 원리 및 아키텍처 조대협 (http://bcho.tistory.com) 아파치 스파크는 빅데이터 분석 프레임웍으로, 하둡의 단점을 보완하기 위해서 탄생하였다. 하둡을 대체하기 보다는 하둡 생태계를 보완하는 기술로 보면 되는데 실제로 기동할때 하둡의 기능들을 사용하게 된다. 하둡이 맵리듀스 방식으로 디스크(HDFS)에 저장된 파일 데이터를 기반으로 배치 분석을 진행한다면, 스파크는 디스크나 기타 다른 저장소(데이터 베이스등)에 저장된 데이터를 메모리로 올려서 분석하는 방식으로 배치 분석 뿐만 아니라, 스트리밍 데이터 양쪽 분석을 모두 지원한다. 기본 동작 원리 및 아키텍쳐 기본적인 동작 원리를 살펴 보면 다음과 같다. 스파크 클러스터의 구조는 크게 Mas..