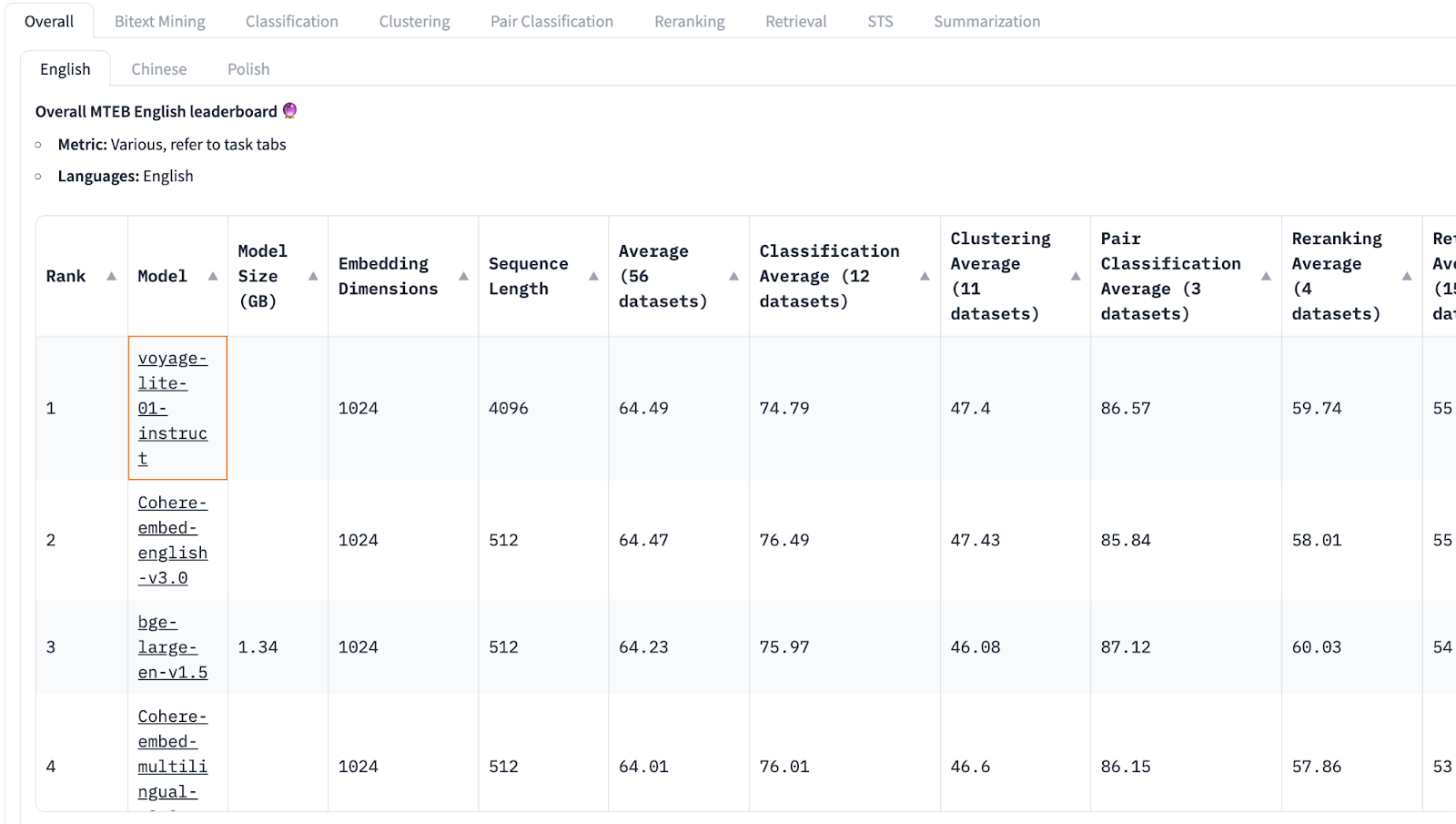
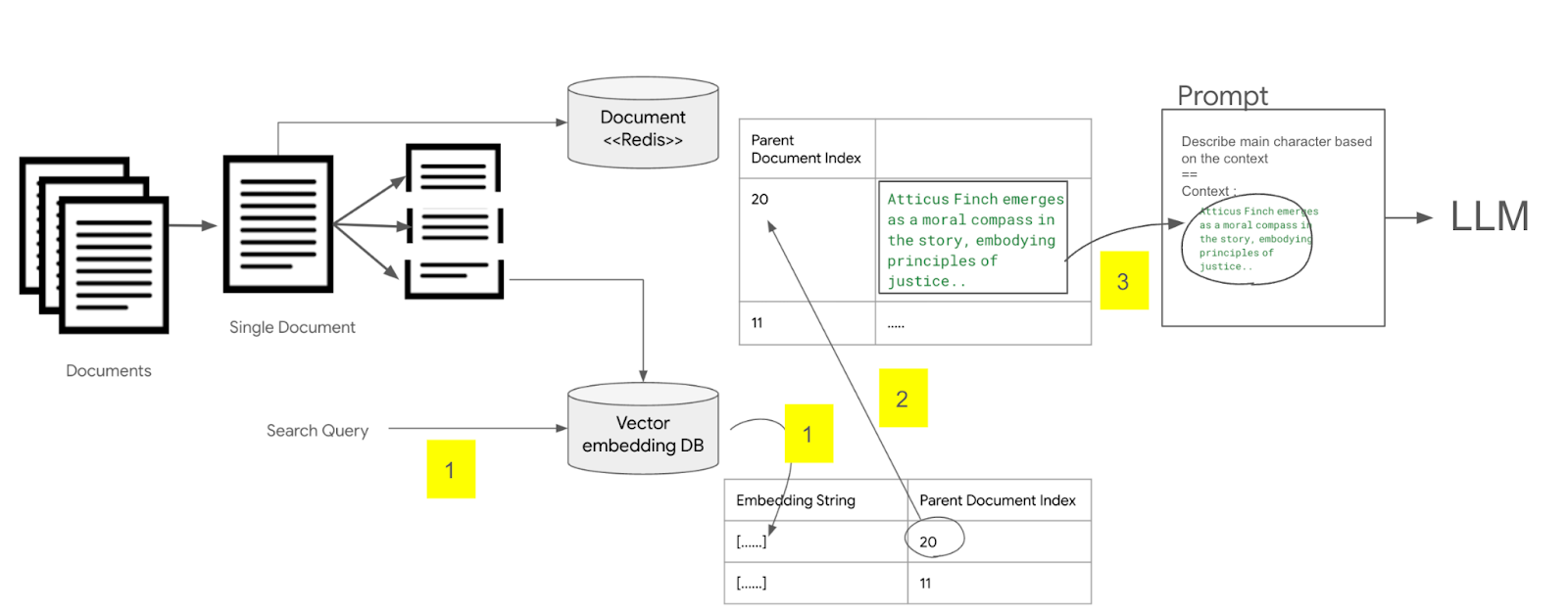
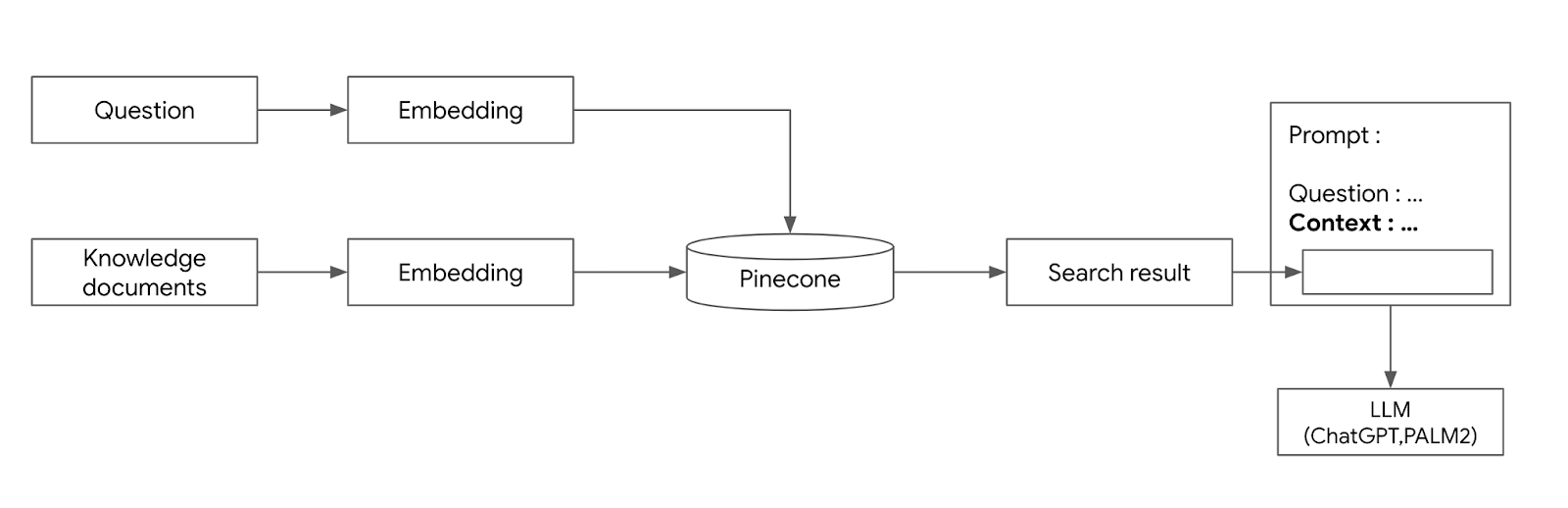
임베딩 API 비교 및 선택 조대협 (http://bcho.tistory.com) 이 글에서는 접근이 쉽고 많이 사용되는 open ai의 임베딩 모델을 사용했지만, 여러 임베딩 모델들이 있고, 임베딩 모델 마다 성능이 다르며 임베딩의 목적또한 다르다. RAG 를 소개하는 글이기 때문에, 문서 검색 (Document Retrieval) 기능이 주요 유스 케이스이지만, 임베딩은 분류(Classification), 클러스터링(Clustering) 등 다양한 시나리오로 사용이 가능하다. 구글의 Vertex.AI 임베딩 모델의 경우, 임베딩의 목적에 따라서 임베딩 타입을 지정하게 할 수 있다. 출처 : https://cloud.google.com/vertex-ai/docs/generative-ai/embeddin..