
대규모 분산 학습에서 고려할 사항
조대협 (http://bcho.tistory.com)
그러면 실제로 분산 학습은 어떻게 이루어질까, 하나의 머신에서 여러 GPU를 사용하는 멀티 GPU의 경우에는 코드만 싱글 GPU 코드와 다르지 다른 설정은 다르지 않다. 그러나 멀티 머신 학습의 경우에는 각 머신에서 학습 코드를 실행해줘야 하고, 같은 데이터 소스로 부터 데이터를 각 머신에서 읽어와야 한다.
그렇다면 동시에 여러 머신에 학습 코드를 어떻게 실행할까?
스케쥴러
수동으로, 특정 서버에서 각각 학습 코드를 실행할 수 도 있지만, 보통 수십,수백개의 머신에서 하나의 학습만을 돌리는 일은 드물다. 중간 중간 실험을 위해서 작은 모델을 학습하기도 하고, 전체 머신들에서 하나의 거대 모델들을 돌리기도 한다.
만약 500개의 머신에서 100개의 머신을 학습하는 모델을 실행했다고 가정하자, 그러면 네트워크의 지연을 줄이기 위해서 해당 머신들은 최대한 인접해 있어야 한다. 또한 학습중에 하드웨어 장애가 발생하면, 전체 학습이 멈추었을때 하드웨어 장애가 발생하지 않은 머신으로 해당 학습 내용을 이동 시켜서 다시 학습을 진행할 수 있어야 한다.
이렇게 학습 워크로드를 여러 머신에 걸쳐서 스케쥴링하고, 재시작등의 관리를 해줄 수 있는 솔루션을 스케쥴러 또는 워크로드 관리 솔루션이라고 하는데, 분산 학습에서 널리 사용하는 스케쥴러로는 쿠버네티스와 슬럼 (https://slurm.schedmd.com/documentation.html) 이 대표적이다.
Slurm은 머신러닝 분산 학습전에 HPC 컴퓨팅에서 이미 사용되고있던 워크로드 관리 솔루션이다. 쿠버네티스는 컨테이너 기반으로, 보통 컨테이너를 사용하는 경우에는 쿠버네티스, 컨테이너를 사용하지 않는 경우에는 Slurm 을 많이 사용한다.
하드웨어 에러
GPU 기반 학습에서 고려해야할점중 하나는 GPU 하드웨어 에러이다.
CPU 에 비해서 상대적으로 GPU는 새로운 인프라라고 볼 수 있고, 아직 장애에 대한 대응 능력이 CPU에 비해서 많이 높지는 않다. 예를들어 CPU의 경우 라이브 마이그레이션이라는 기능을 이용해서, 메모리의 내용을 실시간으로 복제해서, 장애시나 유지보수시에 서버를 다운 없이 다른 서버로 이동할 수 있는데 반하여 GPU는 아직 이런 기술들이 준비되어 있지 않다.

위의 자료는 메타에서 LLAMA3를 학습할때의 내용을 논문으로 정리해놓은 부분을 발췌한 것인데, 총 16000 GPU로 학습을 했을때, 54일동안 총 466번의 학습 실패가 있었으며, 이중 47번은 미리 계획된 유지보수 였다. 나머지 419번중 78%가 장애로 발생한것이었으며, 그중에서 58.7%가 GPU이슈 였다. 이 처럼 GPU 문제로 인한 장애 발생 비중은 분산 학습에서 매우 높기 때문에, GPU 장애등의 노드 장애로 인한 학습 정지시에 이를 Resumable 하게 하는 구성이 필요하다. 보통 체크포인트를 저장한 후에, Job이 실패할시에 자동으로 체크포인트를 읽어서 그 시점부터 Resume 하는 구조를 사용하는데, 이 구성은 torchrun을 이용하면 손쉽게 구성할 수 있다.
만약 하드웨어 장애가 발생하였을 경우, 장애가 난 하드웨어를 복구해야 다시 학습을 재게할 수 있는데, 클라우드나 인프라 제공 업체가 하드웨어를 정비해서 다시 올리기까지는 수시간이 걸리고, 그로 인해서 전체학습을 다시 진행할 수 없는 문제가 생긴다. (하드웨어가 리커버리될때까지 기다려야하기 때문에, 그만큼 하드웨어 자원과 인적 자원이 낭비 된다.) 이런 문제를 대비하기 위해서, 고객이 2~3 노드를 미리 구매해놓고, 스탠바이 상태로 학습에 참여시키지 않다가. 노드 장애가 났을때, 이 대기중인 노드를 학습 노드로 참가시켜서 빠르게 복귀하는 방식을 사용한다.
스토리지
스토리지 역시 분산 학습에서 중요한 성능 요소로 작용한다. 여러 노드가 동시에 같은 분산 학습데이터를 읽어서 GPU 메모리에 학습 데이터를 로딩해야 하고, 또한 고속으로 체크포인트를 디스크에 저장해야 한다.
특히 체크포인트가 큰 경우에는 파일에 쓰는 시간이 많이 걸려서 NCCL 타임 아웃 에러가 발생하는 주요 원인이 될 수 있다.
고성능 대용량 공유 스토리지는 가격이 비싸기 때문에 보통 S3나 GCS와 같은 블롭 스토리지를 백앤드 스토리지로 사용하는데, 이 스토리지는 성능이 너무 느리기 때문에, FUSE 라는 오픈 소스를 이용하여 블롭 스토리지를 로컬 볼륨으로 마운트 한후에, 로컬 디스크를 캐슁으로 사용하는 경우가 많다. 거대 언어모델등의 경우에는 데이터 사이즈가 워낙 커서 이 방법을 많이 사용한다.
다른 방법으로는 고성능 스토리지를 사용하는 방법이 있는데, NFS의 경우에는 성능이 안나오는 경우가 많기 때문에, NetApp과 같은 어플라이언스 장비를 사용하거나. 병렬 처리에 특화된 스토리지를 사용하는 경우가 많다. 오픈소스 스펙으로는 Lustre와 DAOS가 대표적인데, 아마존 클라우드의 경우에는 Lustre 스토리지를 지원하고 있다. 그외에도 https://www.weka.io/ 와 같이 머신러닝에 최적화된 분산 스토리지가 있기는 하지만 반드시 스케쥴러 솔루션과의 조합 (쿠버네티스)등을 고려해서 마운트가 제대로 되는지를 확인해야 한다.
스토리지의 성능은 연결된 클라이언트별 대역폭과 초당 전송 속도 IOPS등을 고려해야 한다.
다른 주목할만한 스토리지로는 https://dnn.com/ 스토리지가 있는데, NVIDIA는 스토리지의 데이터를 바로 GPU 메모리로 로드할 수 있는 DMA(Direct Memory Access)라는 기술을 제공하는데, 이 dnn 스토리지 제품중에는 DMA를 지원하는 스토리지가 있다.
체크 포인팅
앞에서도 살펴봤듯이 체크포인팅은 전체적인 성능 및 장애 대응에 있어서 중요한 요인으로 작용한다. 그래서 체크포인트 저장을 효율적으로 하는 것이 중요한데, 체크포인트 순간에 파일에 모두 체크포인팅 내용을 저장하고, 학습을 계속하는 동기식 방식은 시간이 많이 걸린다. 그래서 이를 개선하기 위해서 학습을 하면서 이 내용을 파일에 저장하는 비동기 체크 포인팅 방법을 사용할 수 있다.
아래 실험 결과를 보면 7B 모델에서 비동기 체크포인팅을 사용하지 않은 경우 저장 속도가 148.8 초인데, 반해 비동기 체크포인팅을 사용할 경우 6.3초로 약 23배 이상 빨리진것을 확인할 수 있다.
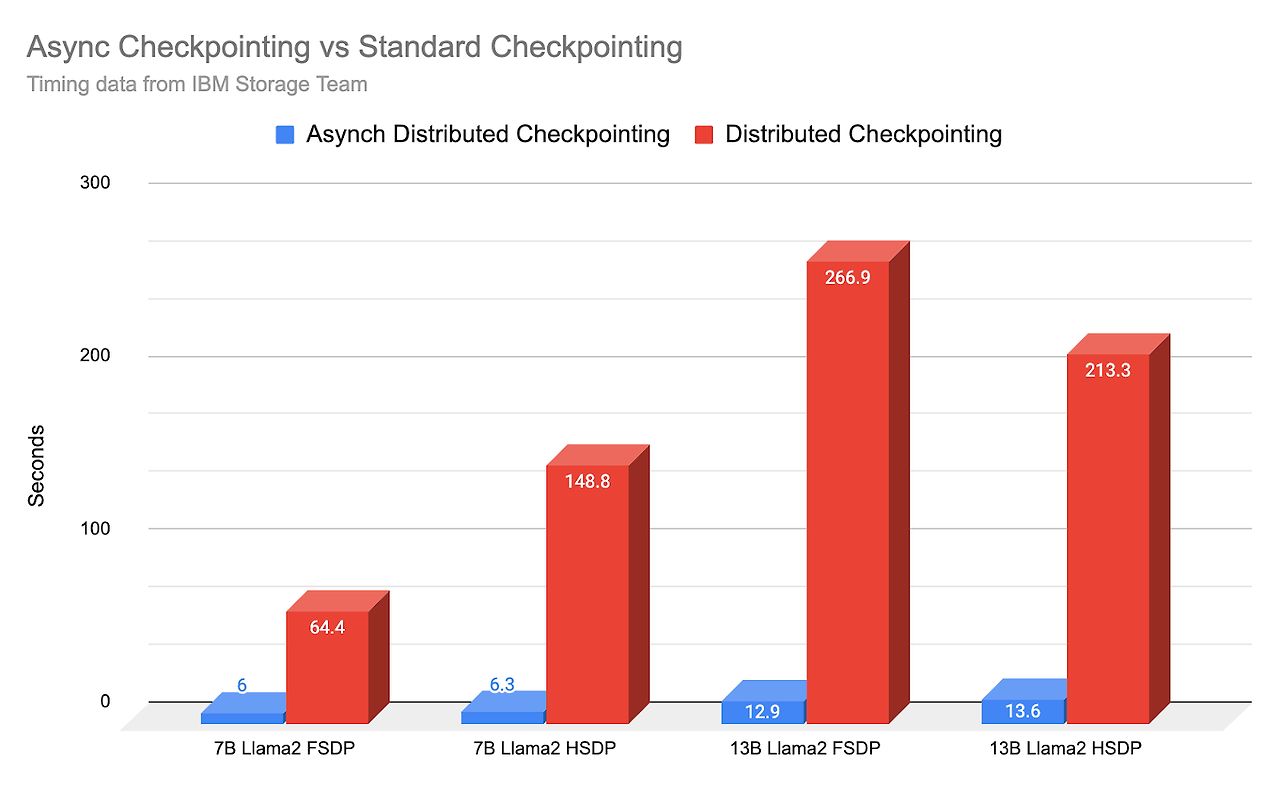
참고 : https://pytorch.org/blog/reducing-checkpointing-times/
'빅데이타 & 머신러닝 > Pytorch' 카테고리의 다른 글
| 5. 파이토치 - 분산 학습의 개념과 하드웨어 (1) | 2024.09.03 |
|---|---|
| 파이토치 분산 학습 도구 비교 (0) | 2024.08.20 |
| 파이토치 4 - 쿠버네티스에서 학습하기 (0) | 2024.08.19 |
| 파이토치 3. 파이토치라이트닝 (0) | 2024.08.16 |
| 파이토치 2. 선형회귀 (Linear Regression)을 통한 코드 구조 이해 (0) | 2024.08.06 |