
분산학습의 개념
조대협 (http://bcho.tistory.com)
분산 학습 개념
분산학습이란, 모델이 커서 하나의 머신이나 장치(CPU,GPU) 에서 학습이 불가능할때, 모델을 여러개의 GPU나 또는 여러개의 머신으로 나눠서 학습을 하는 방법이다.
분산 학습의 방법
분산 학습 방법은 크게 모델 병렬화 (Tensor Parallelism), 데이터 병렬화 (Data Parallelism) 으로 분류 할 수 있다.
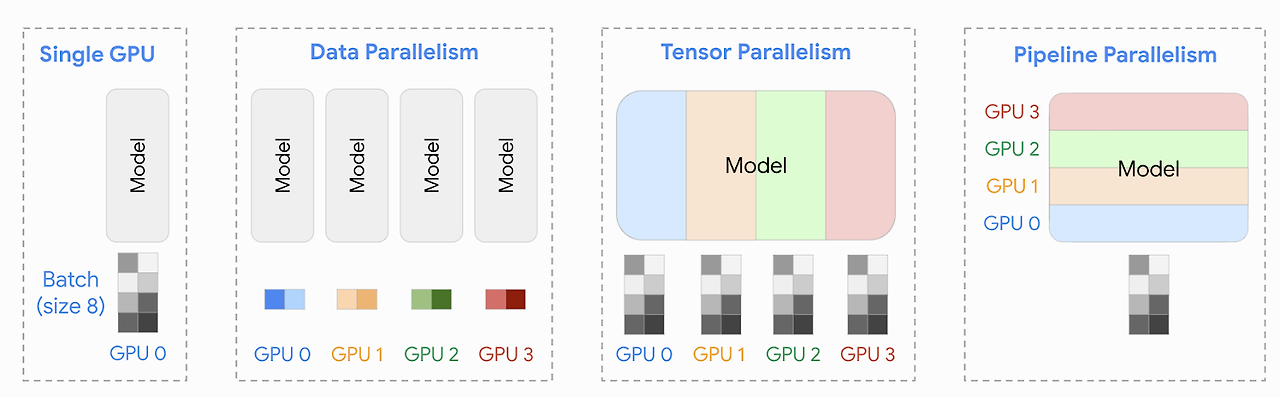
- 데이터 병렬화 : Distributed Data Parallelism (이하 DDP)라고 하는데, 이는 같은 모델을 여러개의 GPU와 여러개의 노드에서 동시에 학습을 하는 방식이다. 여러개의 머신에서 학습을 할때 학습되는 모델은 같지만, 학습에 사용되는 데이터를 서로 다른 데이터를 학습 시킴으로써, 전체 학습 시간을 줄이는 방법이다. 예를 들어 GPU 머신이 1~4 까지 있고 데이터 셋이 4000개가 있을때, 1번 머신에서는 1~1000 까지 데이터를, 2번 머신에서는 1001~2000, … 데이터를 학습 시킨 후, 학습된 Weight 값을 다시 1~4머신으로 동기화 시켜서 모델을 학습하는 방식이다.
- 모델 병렬화 (텐서 병렬화) : 텐서 병렬화는 모델 병렬화중 하나로, 모델을 횡으로 잘라서 학습하는 각각의 모델 일부를 다른 머신에서 학습하는 방식이다. 예를 들어 아래 그림과 같이 GPU1에서 레이어 1,2,3 의 반을 학습시키고, GPU2에서 레이어 1,2,3의 나머지를 학습 시킨후 GPU 3에서 이 학습된 내용을 합치는 방식이다.

모델 병렬화의 경우 대형 모델의 경우 모델 자체를 나눠서 다른 하드웨어에서 학습할 수 있다는 장점이 있지만, 모델을 어떻게 잘라야 GPU(또는 머신)의 성능을 최적화할 수 있을까에 대한 고민과, 다음 스테이지로 넘어가는 시점등에 대한 고민등 다양한 문제점이 있기 때문에 쉽게 접근할 수 는 없는 방식이다.
예를 들어 100 레이어짜리 모델이 있을때, 1~20 레이어까지 잘라서 GPU에 할당했을때 GPU 성능이나 메모리가 남을 수 도 있고, 50 레이어까지 잘라서 할당했을때는 GPU 메모리가 모자를 수 있다.
또는 위의 그림에서 GPU1과 2의 연산 시간이 너무 오래 걸리면 GPU3 가 놀면서 낭비될 수 있다.
이런 이유로 데이터 병렬화가 많이 사용된다.
데이터 병렬화의 경우 각 GPU나 머신에서 학습된 데이터를 다시 각 머신과 GPU로 동기화를 해야 하는데, 이렇게 각각의 노드 (GPU나 머신)에서 학습된 값을 다른 모든 노드로 복제해서 합치는 과정을 AllReduce라고 한다. (아래 그림에서 토폴로지 참고)

출처 : https://pytorch.org/tutorials/intermediate/dist_tuto.html
그러면 백앤드에서 이 GPU 간의 통신 또는 다른 머신간의 통신을 담당해줄 백엔드 라이브러리가 필요한데, 대표적으로 NVIDIA 의 NCCL이 많이 사용되고, 대안으로 MPI나 Uber에서 개발한 Horovod, 페이스북에서 개발한 Gloo 등이 있다.
아래는 파이토치 데이터 분산학습 (DDP)의 예로, NCCL 백앤드를 사용한 예제이다. MPI를 사용하는 예제의 경우에는 dist.init_process_group("nccl" 을 dist.init_process_group("mpi" 로 변경하면 된다.
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group("nccl", rank=rank, world_size=world_size) #MPI 백앤드를 사용할경우 "nccl"을 "mpi"로 변경
torch.cuda.set_device(rank)
def cleanup():
dist.destroy_process_group()
def train(rank, world_size):
setup(rank, world_size)
# 모델 및 데이터 생성
model = torch.nn.Linear(10, 10).to(rank)
model = DDP(model, device_ids=[rank])
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
data = torch.randn(20, 10).to(rank)
# 간단한 학습 루프
for _ in range(10):
optimizer.zero_grad()
output = model(data)
loss = output.sum()
loss.backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
world_size = 4 # GPU 4개 사용 예시
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
MPI의 경우는 HPC 와 같은 분산 수퍼 컴퓨팅에 사용되는 프레임웍으로, GPU에도 사용이 가능하지만, 주로 CPU 위주의 작업에서 유리하다. 아래는 NCCL과 MPI의 분산 학습 성능 테스트 예시 자료로, NCCL이 훨씬 좋은 성능을 내는 것을 볼 수 있다.
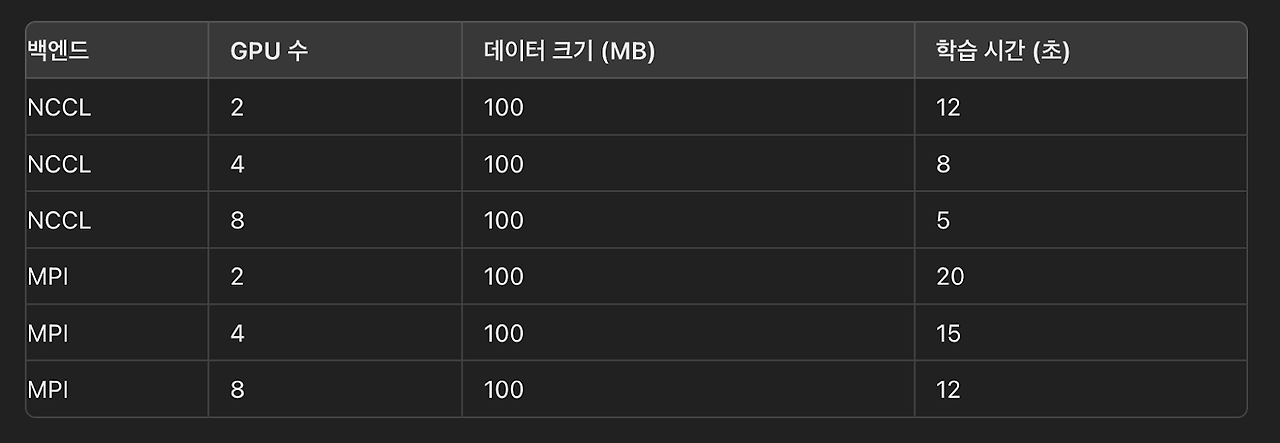
이러한 백앤드 통신은 GPU-to-GPU 또는 머신-to-머신 간의 네트워크 통신이 발생하기 때문에, GPU간의 대역폭 또는 머신간의 대역폭이 매우 중요한 요인으로 작용한다.
특히 LLM 모델의 경우 전체 성능에서 AllReduce가 차지하는 시간이 20~30% 로, AllReduce가 GPU간 또는 머신간 통신을 사용한다는 점을 보면 GPU간 통신 대역폭이나 머신간 네트워크 통신이 얼마나 중요한지 알 수 있다.
GPU 간의 통신
일반적으로 GPU 는 서버에 PCI-e 슬롯위에 인스톨이 되는데, GPU간의 통신은 송신 GPU → PCIe → CPU → PCIe → 수신 GPU 식으로 이루어지기 때문에, PCI-e 슬롯의 성능을 넘어설 수 없다. 이를 해결하기 위해서 NVIDIA GPU의 경우 NVLink라는 기술을 사용하는데, GPU간에 NVLINK 아답터를 이용하여 직접 GPU간을 연결하는 기술이다. 아래 그림은 RTX 그래픽 GPU에서 NVLINK 아답터를 이용하여 두개의 GPU를 직결한 사진이다.

이 경우, GPU간의 통신은 GPU → NVLink → GPU를 사용하기 때문에, 중간에 PCI-e 슬롯을 거치지 않기 때문에, 훨씬 빠른 성능을 기대할 수 있다.
아래 그림은 NVIDIA 개발자 사이트에서 PCI-e와 NVLink 의 성능을 비교한 그래프인데, PCI-e 대비 NVLINK가 4 GPU에서 5배 가량 성능 차이가 나는것을 볼 수 있다.
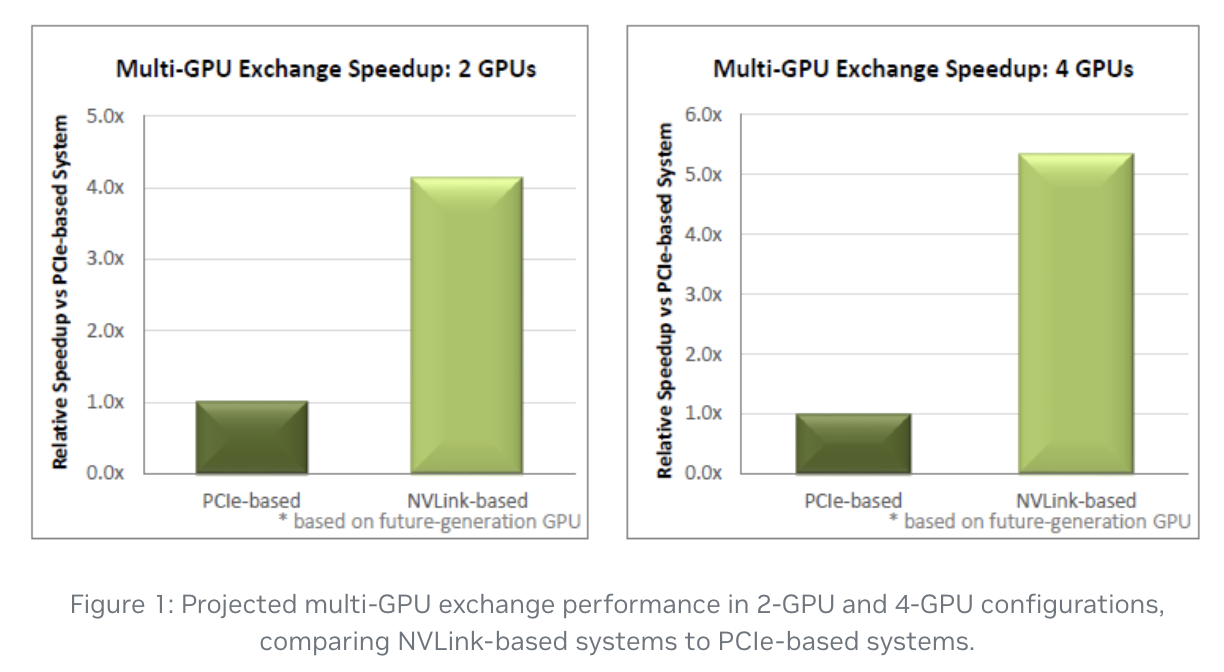
출처 : https://developer.nvidia.com/blog/how-nvlink-will-enable-faster-easier-multi-gpu-computing/
머신간 통신
하나의 머신에서 멀티 GPU (1~8GPU)를 사용하는 학습의 경우에는 GPU간 NVLink를 이용하여, GPU간 통신 속도를 향상 시킬 수 있다. 그러면 머신간의 통신은 어떻게 할까? 머신간의 통신 속도를 높이기 위해서 보통 NVIDIA H100 GPU를 기준으로 보면, 보통 Infiniband 를 이용하여 3.2 TBps의 노드간 통신 속도를 제공하도록 하드웨어를 설정한다.
클라우드 벤더의 경우 Infiniband를 사용하는 경우도 있고, 일반적인 TCP/IP 네트워크를 사용하는 경우도 있고 벤더마다 기술이 다르고 대역폭도 다소 차이가 난다.
NVSwitch
그런데 머신간의 통신도 결국은 PCI-e 버스를 통해서 CPU를 걸쳐서 네트워크 인테페이스 (NIC) 를 통해서 통신이 된다.
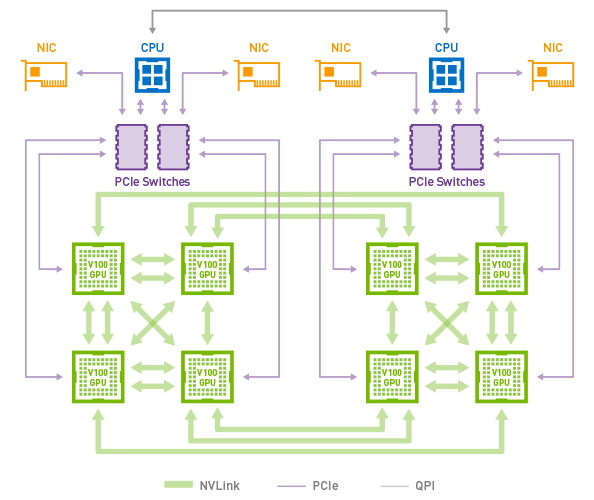
출처 : https://www.anandtech.com/show/12581/nvidia-develops-nvlink-switch-nvswitch-18-ports-for-dgx2-more
즉 PCI-e의 성능으로 인하여 결국은 병목이 발생할 수 있다는 것인데, 이를 NVIDIA에서 해결하기 위해서 NVIDIA 가 사용하는 방법이 NVSwitch라는 방법이 있다. NVLink의 개념을 멀티 노드간 통신으로 확장한 개념으로 보면 되는데, 전용 스위치를 개발해서 GPU를 직결하는 방법이다. (아래 그림 참고)
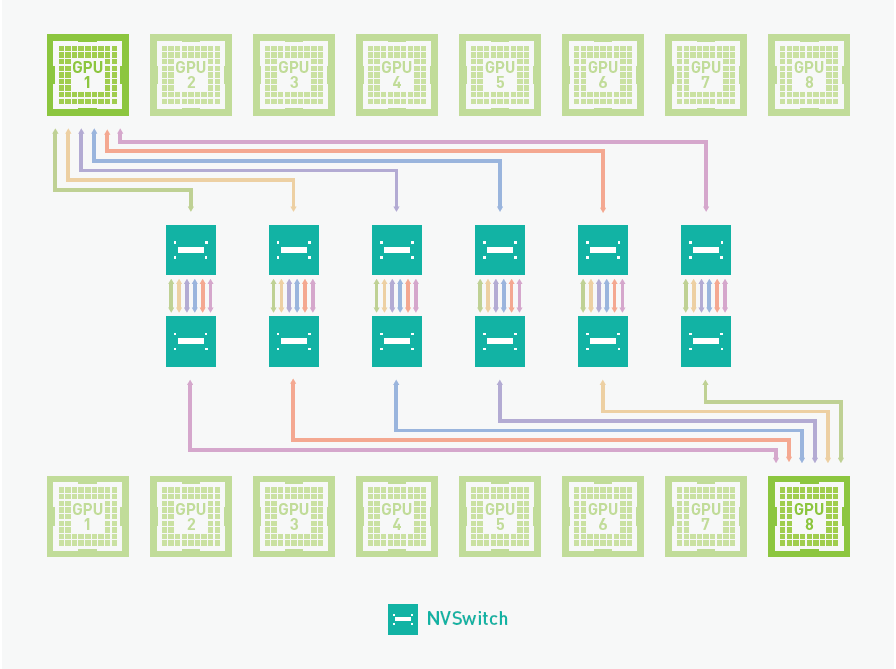
출처 : https://www.amax.com/modernizing-gpu-network-data-transfer-with-nvidia-nvswitch/
이로 인하여 GPU 머신간의 통신이 PCI-e 슬롯을 거치지 않고 직접 NVSwitch를 통해서 GPU-to-GPU간 직접 통신이 가능하게 된다.
사실 NVSwitch를 사용하면 최대의 성능을 기대할 수 있겠지만, 여기서 주의 깊게 생각해봐야 하는 문제는 과연 이런 고속 네트워크 성능이 필요할까 이다.
3.2 Tbps의 대역폭을 NVlink Infiniband를 사용하지 않더라도, 거대 모델이라 하더라도 학습에 3.2 Tbps를 사용하지 않는 경우가 많다. 1.2~1.6 정도밖에 사용하지 않는 경우가 대부분이고, 만약 대역폭을 많이 사용한다는 것은 AllReduce 작업이 많다는 것이기 때문에, 코드 최적화를 통해서 네트워크 작업을 줄이는 것이 좋다. (백앤드 대역폭이 빠르다고 하더라도 결국은 네트워크 IO 작업이고 시간이 많이 소모되는 작업이다.)
그리고 NVSwitch는 NVIDIA의 특정 장비를 요구하기 때문에, 클라우드 벤더의 경우 지원이 안되는 경우가 있을 수 도 있다.
앞에서도 살펴봤지만, NVIDIA는 GPU 자체 성능도 뛰어나지만, 대규모 학습을 지원하기 위한 인프라를 폭넓게 지원하고 있다. 이 때문에, NVIDIA가 계속적으로 시장을 장악하고 있지 않나 하는 개인적인 생각을 해본다.
'빅데이타 & 머신러닝 > Pytorch' 카테고리의 다른 글
| 6. Pytorch - 대규모 분산학습에서 고려할 사항 (0) | 2024.10.03 |
|---|---|
| 파이토치 분산 학습 도구 비교 (0) | 2024.08.20 |
| 파이토치 4 - 쿠버네티스에서 학습하기 (0) | 2024.08.19 |
| 파이토치 3. 파이토치라이트닝 (0) | 2024.08.16 |
| 파이토치 2. 선형회귀 (Linear Regression)을 통한 코드 구조 이해 (0) | 2024.08.06 |