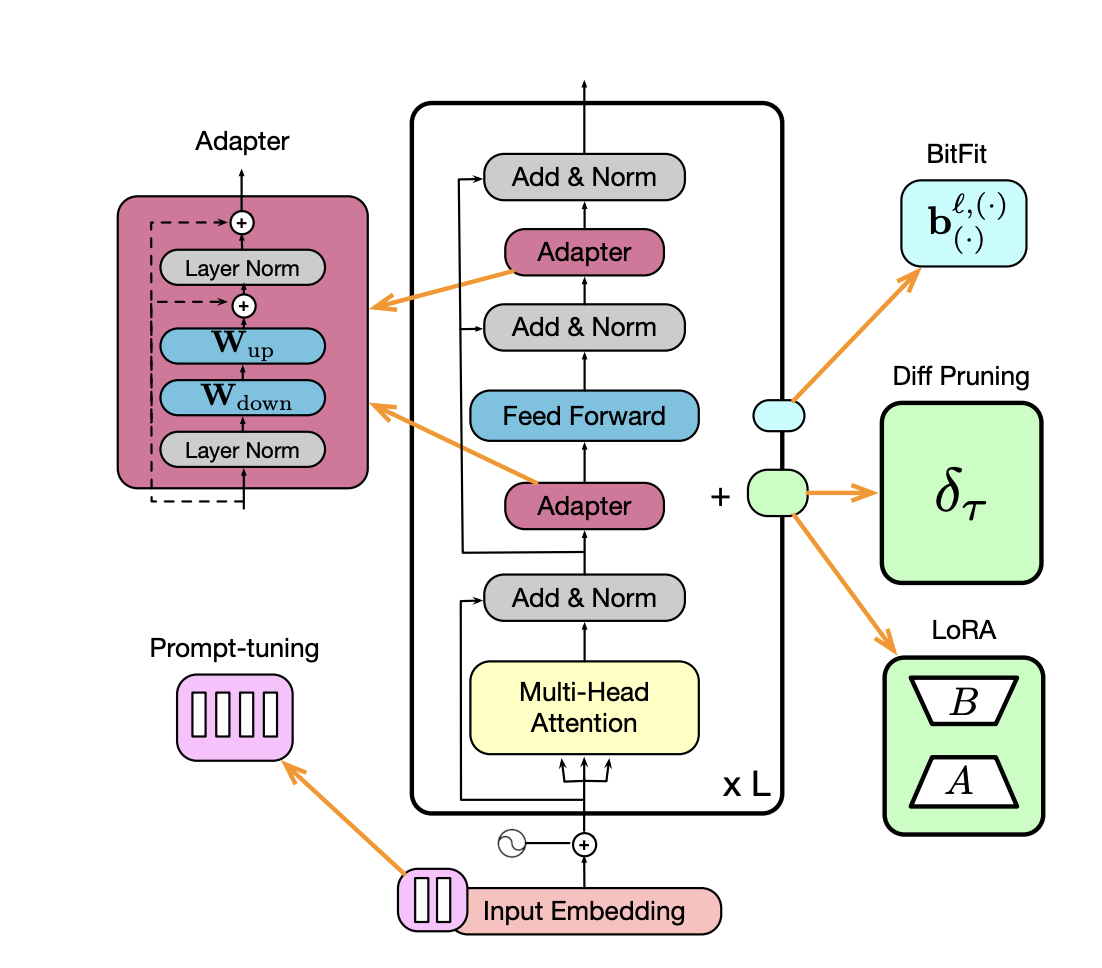
LoRA 파인튜닝 개념의 이해조대협 (http://bcho.tistory.com) LLM 모델에 대한 Fine tuning시에, 가장 기본적인 방법은 모델을 학습데이터로 새롭게 처음부터 학습하는 방법인데, 이 방법은 (GPU)비용이 너무 많이 들고 시간도 많이 걸린다. 그래서 대안으로 등장한것이 PEFT (Parameter-Efficient Fine-Tuning) 이라는 개념으로 , 원본 모델의 패러미터(Weight)값은 고정 시키고 작은 수의 파라미터만 훈련하거나 작은 모듈을 추가하여 학습 하는 방법으로, 과적합 (Overfitting)을 방지하고 연산량을 줄이 는 방식이다. AdapterPEFT 방법으로는 오늘 살펴볼 LoRA나 Adapter 등의 방식이 있다.Adapter 방식은 기존 모델 아키텍처..