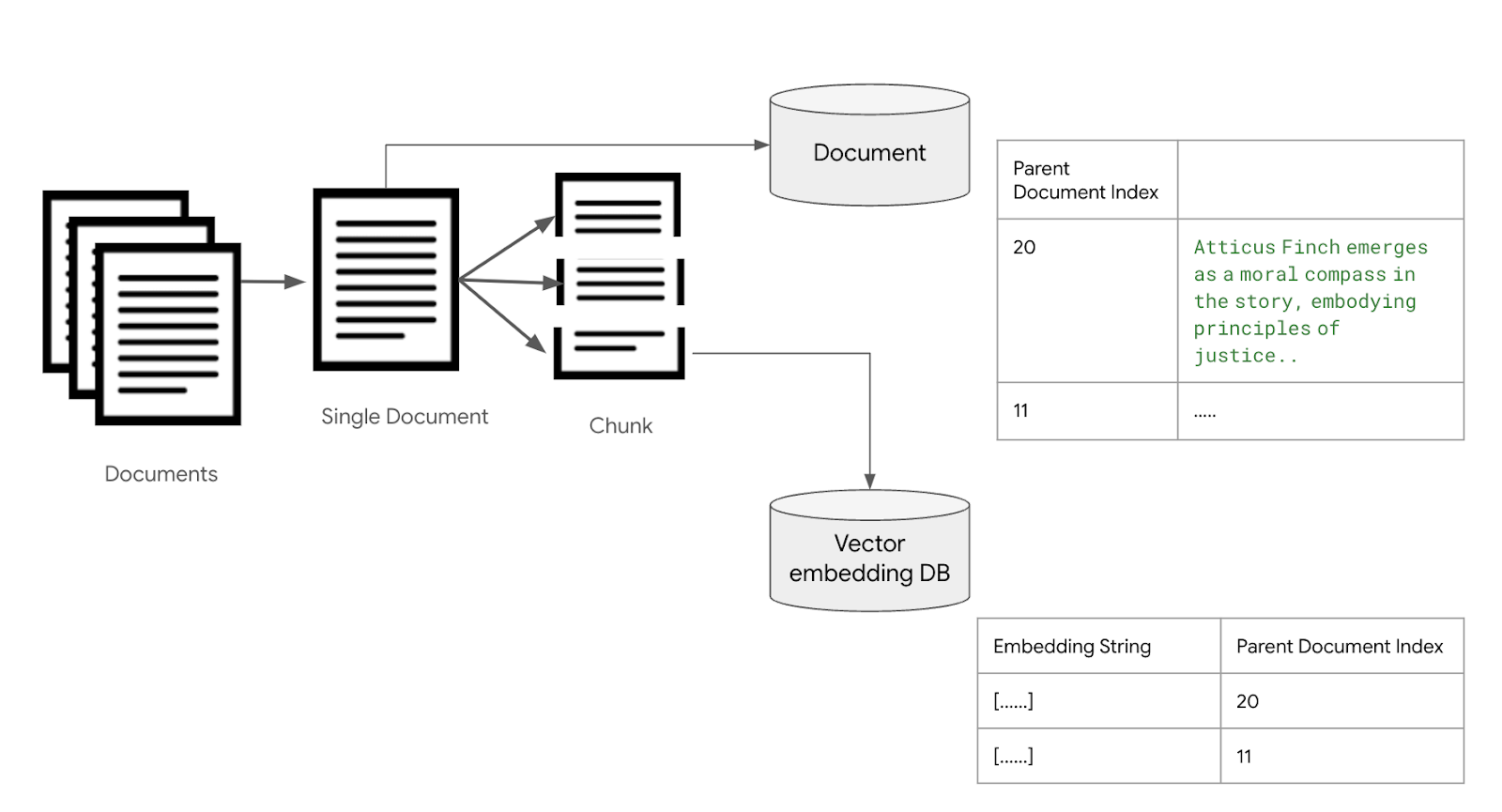
지금까지 살펴본 Retriever 들은, chunk 의 원본 문서 또는 문장을 저장할때 벡터 데이터 베이스에 text 필드에 저장하였다. 보통 한 문서 또는 한 문장은 여러개의 chunk로 분할되어 각각 저장되기 때문에 원본 Text가 중복되서 저장되는 문제점이 있고 이로 인하여 데이터 베이스 용량이 커지는 문제가 있다. 또는 원본 문서의 크기가 클때는 데이터 베이스 싱글 컬럼에 저장이 안될 수 도 있다. 이러한 문제를 해결하기 위한 구조를 parent-child chunking 이라고 하는데, langchain에서는 ParentDocumentRetriever 를 통해서 이 구조를 지원한다. 기본 원리는 chunk를 저장할때 chunk에 대한 원본 텍스트를 저장하지 않고, 원본 문서는 별도의 문서 저장소..