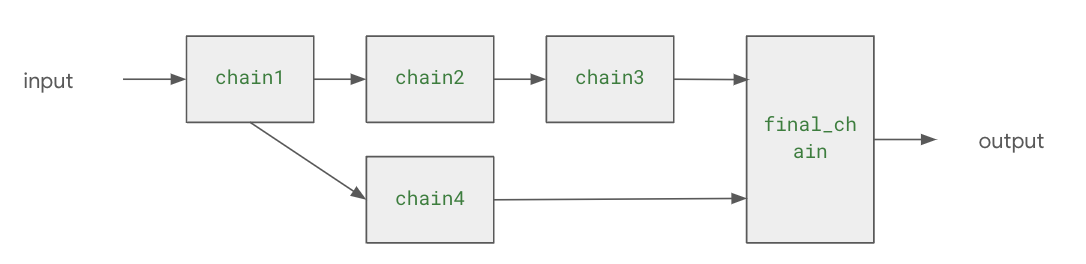
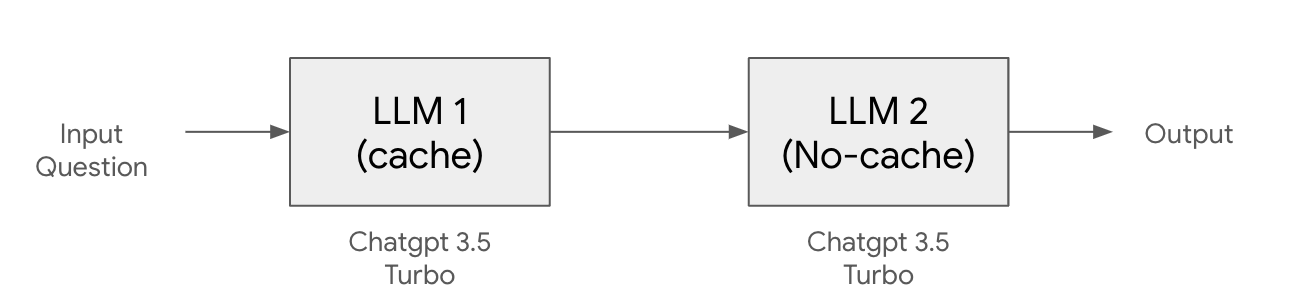
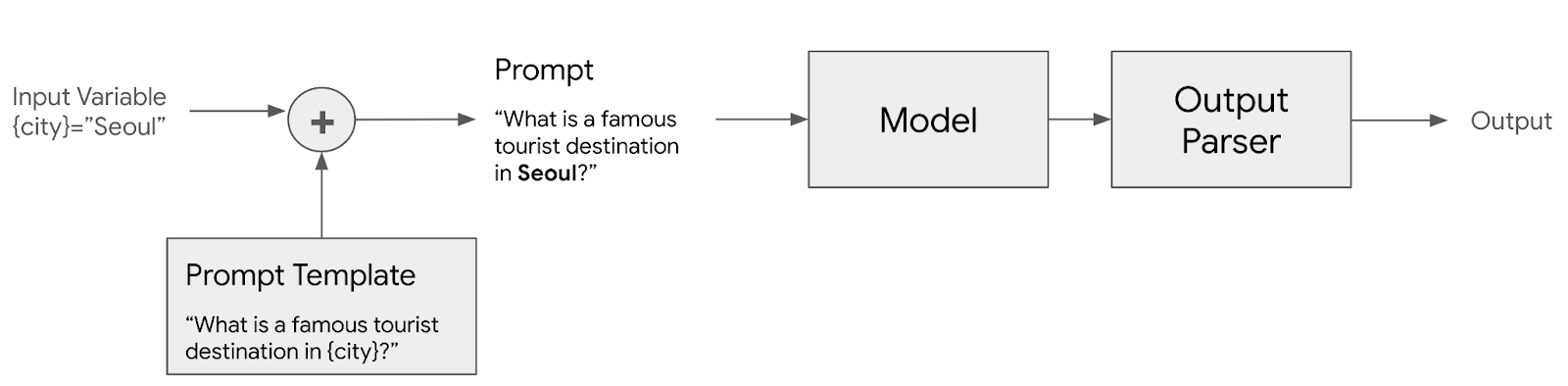
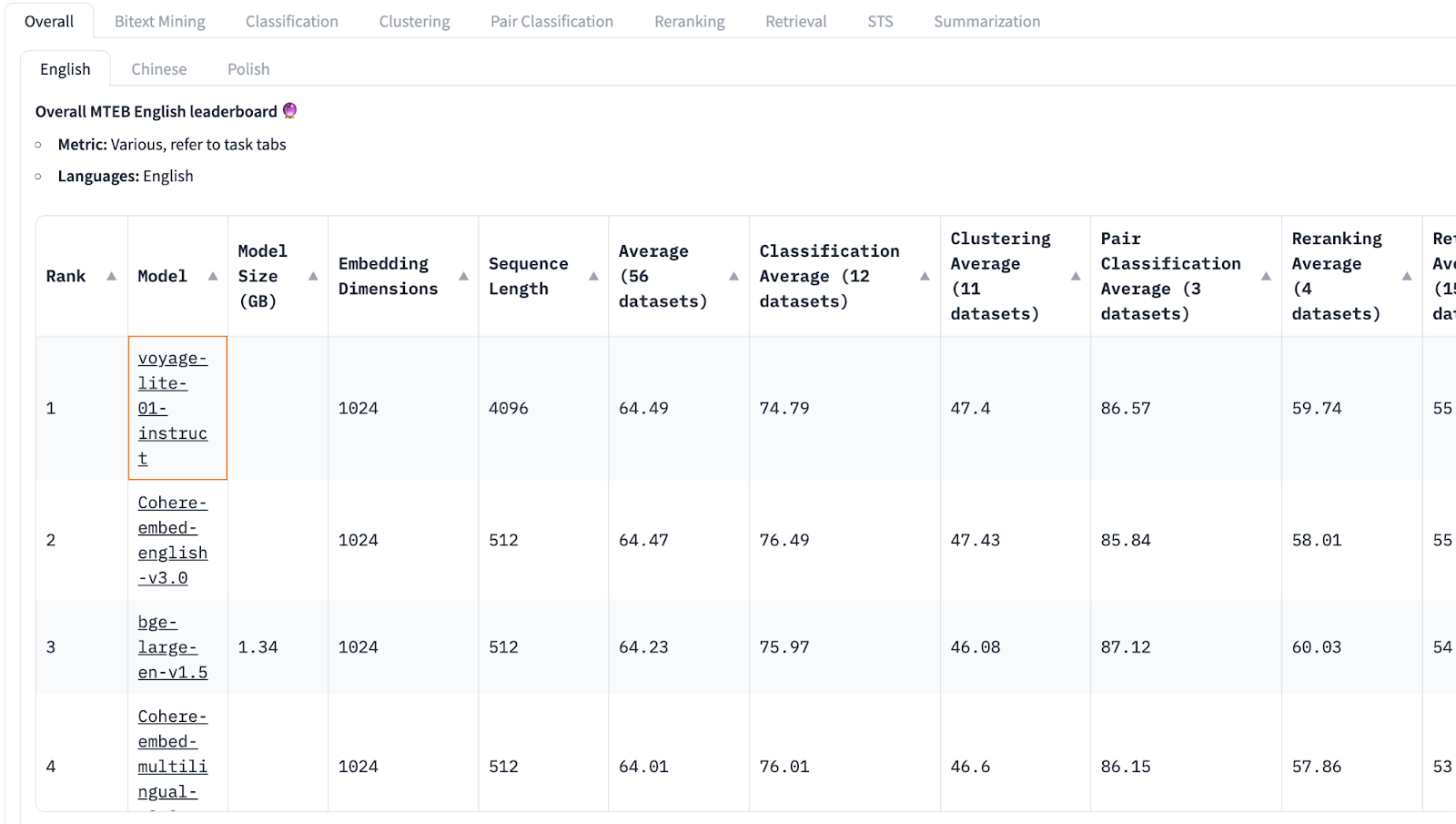
안녕하세요?조대협입니다. 그동안 실시간으로만 진행해왔던 대용량 아키텍처 설계 강의를 온라인으로 패스트 캠퍼스에서 오픈합니다.생성형 AI 시대가 되면서, 코딩은 이제 AI가 하게 되고, 그러면 엔지니어로써 살아남기 위해서는 무엇을 준비해야 할까 고민을 해보면, 실리콘 밸리에서는 자바나 안드로이드 엔지니어가 아니라 General Software engineer라는 역할을 뽑습니다.특정 언어나 기술에 대한 종속성이 있는 것이 아니라, 비즈니스 문제를 기술로써 해결하는 사람으로, 이런 엔지니어의 특징은 문제 해결능력, 비즈니스에 대한 이해, 설계 능력과 좋은 커뮤니케이션 능력을 가지고 있습니다. 그래서 이번 대용량 아키텍처 강의는 그동안의 노하우를 다시 정리해서 리부트 하였습니다1. GTM 기반의 비즈니스 전..