
ALM 이후로 가지고 놀 수 있는 장남감을 찾던중에 발견한 장난감.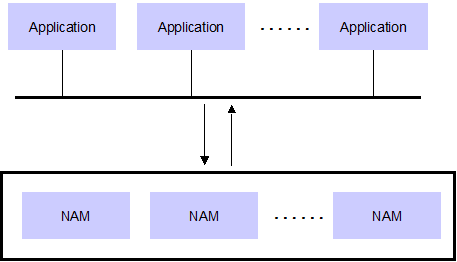 자바 애플리케이션을 개발하면 문제중에 하나가 JVM Instance끼리 데이타 공유가 불가능하다는 것이다. 이런 경우는 DB나 FILE을 이용하는데 성능상의 문제도 많고 DB로 공유하기에는 어려운 데이타들이 있는 것이 사실인데.
자바 애플리케이션을 개발하면 문제중에 하나가 JVM Instance끼리 데이타 공유가 불가능하다는 것이다. 이런 경우는 DB나 FILE을 이용하는데 성능상의 문제도 많고 DB로 공유하기에는 어려운 데이타들이 있는 것이 사실인데.
요즘 Vitualization과 cloud computing 이야기가 많은데.
Cloud computing중에서 data grid에 해당 하는 부분
이런것을 커버해주는 것이 NAM (Network Attached Memory)라는 개념이다.
애플리케이션 입장에서는 일반적인 메모리를 ACCESS하는 것처럼 사용하지만, NAM 서버들이 서로 클러스터링 되어서 대용량의 데이타를 애플리케이션 입장에서 하나처럼 보여주는 것이다.
예를 들어 애플리케이션에서 HashMap을 이용하여 데이타를 Put/get을 했을때 이 Hash map이 모든 Instance간에 공유가 되고 있고, 메모리 용량이 필요할때 마다 수평적으로 NAM 서버만 증가하면 된다. 또한 NAM 서버간에는 서로 데이타가 클러스터링에 의해서 복제되고 있기 때문에 서버 장애로 인한 유실 염려도 매우 낮다.
이 NAM 관련 제품으로는 여러가지가 있는데
* Coherence
상용제품으로는 오라클이 인수한 제품중에서 마음에드는 Coherence라는 제품이 있다. Tangosol이라는 회사를 작년에 인수 한것인데, Jive Soft나 Atlassian JIRA나 Confluence와 같은 패키지에도 이미 널리 쓰이고 있는 제품.
사용법도 정말 쉽다.. -_-
서버 띄우는 것은 java -jar coherence.jar 하면 뜬다. 인스턴스 더 띄우고 싶으면 또 그냥 띄우면 된다.
물론 구체적인 설정을 하자면 configuration이 필요하지만 기본 테스트정도는 충분한듯..
단순하게 캐쉬나 메모리 쉐어링만 되는 것이 아니고 별별짓들을 다 지원하는데.
예를 들어서 Coherence 내부의 메모리를 JMS 처럼 사용할 수 있는 Coherence의 설정을 JMS extension을 이용해서 한후 Weblogic 서버와 같은 WAS에 JMS로 등록해주면 개발자는 WebLogic의 JMS를 사용하는것과 같이 똑같이 사용할 수 있지만, 내부적으로는 Memory base의 대용량 JMS Q를 확보하게 되는것이다.
JMS 사용할때, 항상 메모리 Q의 경우 메모리 크기 한계가 있었고, Persistence 사용시에는 성능 문제가 있었는데 한번에 날려주는 깔끔함..
OR Mapper의(하이버네이트)등의 캐쉬로도 쉽게 맵핑이 되기 때문에 정말 편리하다.
대용량 데이타를 DB에 적재할 필요없이 메모리로 유지하면 되니까는 이 또한 성능에 얼마만큼이나 영향을 줄지 생각만해도 즐겁다.
그외에도 WAS의 세션 복제에도 사용이 될 수 있다. Message exchange pattern (Pub&Sub)등에도 사용할 수 있는 패턴들을 제공하고 있다. 단순히 Hashtable 프로그래밍 하듯이 하면 되기 때문에 매우매우 사용이 편하고...
* Terracotta
http://www.terracotta.org
오픈소스로는 테라코타라는 제품이 있는데. 이놈은 약간 골때린다.
예를 들어 static 으로 지정한 변수가 있다면 이 변수를 cluster를 통해 공유할 수 있다.
config 파일에서 어늘 클래스의 어느 변수를 공유하겠다고 정의만 하면 공유가 가능하다는 것이다. 프로그램에 영향을 주지 않고 공유가 가능하다는 점은 높이 살만하지만
기본적으로 instrumentation을 이용한 기법이기 때문에, 애플리케이션 실행시
% java main
이 아니라
% dso-java main
식으로 jvm을 wrapping한 terracotta용 jvm을 사용해야 하기 때문에 장애에 대해서 얼마나 튼튼한지는 모르겠다.
다행히도 주요 WAS에 대해서는 certi를 하는 것 같고, enterprise 사용시 상용으로 support를 살 수 있기도 한것 같아서 마음이 약간 놓이기도 하지만 글쎄?? 써봐야 하지 않을까???
hadoop을 찝쩍 거리다가 어찌하다가 이쪽을 보게 되었는데 흥미 진진한 분야 인것 같다.
시간이 나면 테스트와 아키텍쳐 잡아보고 포스팅 하겠습니다.!!!
'클라우드 컴퓨팅 & NoSQL > Data Grid (IMDG)' 카테고리의 다른 글
| JBoss Infinispan 온라인 웨비나 내용 노트 (0) | 2014.03.19 |
|---|---|
| HazelCast 공부 노트 (0) | 2014.02.11 |
| 간단한 HazelCast 테스트 (1) | 2014.02.11 |
| Oracle Coherence 문서 Link (0) | 2009.08.18 |
| Coherence를 이용한 차세대 JEE 아키텍쳐 (확장성과 유연성이 높은 애플리케이션 그리드) (11) | 2009.06.10 |