
빅데이터 분석을 위한 메달리온 아키텍처
조대협 (http://bcho.tistory.com)
메달리온 아키텍처는 데이터를 품질에 따라서 계층별로 나눠서 저장하는 데이터 분석 아키텍처이다. Databricks에서 데이터 엔지니어링과 분석 워크플로우를 단순화하기 위해서 소개된 개념으로 데이터 레이크 기반 시스템에서 데이터의 품질과 정제 수준을 체계적으로 관리하기 위해서 등장했다.
데이타를 품질에 따라서, 올림픽 메달처럼 Bronze ⇒ Silver ⇒ Gold 등급으로 나눠서 저장한다.
특히 데이터 레이크 (하둡과 같은 파일 시스템 기반)과 데이터 웨어하우스(빅쿼리,오라클,스노우플레이크와 같은 SQL 기반)을 통합하여, 데이터 정제 단계를 계층화 하였다.
이해를 돕기 위해서 아래 그림을 보자.
먼저 데이터 계층을 Bronze , Silver , Gold로 나눠놨다.
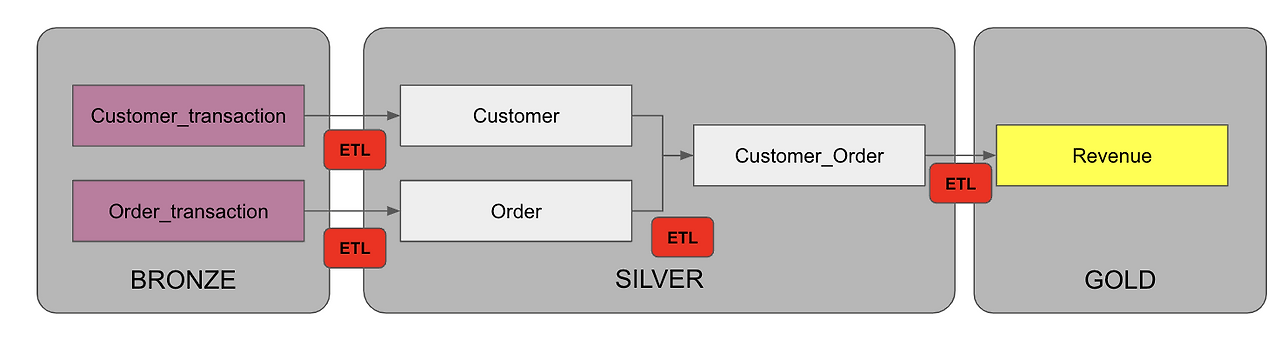
Bronze에는 Customer_transaction과 Order_transaction 테이블이 있는데, 이는 외부에서 수집한 원본 데이터이다. 예를 들어 Customer_transaction은 사용자 데이터로 MySQL에서 수집했다고 하고, Order_transaction은 주문 데이터로 Kafka를 통해서 수집되었다고 하자. 이렇게 수집된 원본 데이터는 Bronze 계층에 저장된다.
그런데, 이렇게 저장된 원본 데이터는 종종 포맷이 맞지 않거나, Order_transaction에 중복된 내용이 있거나 또는 일부 필드가 NULL로 잘못저장되어 있다. 이러한 데이터는 분석에 사용할 수 없으니, 이 데이터를 ETL을 이용하여 정제해서 Customer와 Order 테이블에 저장한다. 그리고 사용자당 주문 내역을 추적할 수 있게, Order와 Customer 테이블을 조인하여 Customer Order 테이블을 생성한다.
이 계층이 Silver 계층으로, 각 원본데이터를 정제된 형태로 저장한 데이터이다.
Silver 계층의 데이터는 정제만 되었을뿐, 비즈니스적인 의미를 가지지 않는다. 이 테이블을 정제해서 사용자당 매출이나, 년 매출, 상품당 매출과 같은 비즈니스적으로 의미있는 형태로 가공한 테이블이 Gold 계층이 된다.
이렇게 품질에 따라서 데이터를 분류하여 저장하는 이유는 크게 다음과 같다.
- 품질별 데이터 분류 : 품질에 문제가 있는 데이터를 저 계층에 격리하여, 데이터 분석시에 일어날 수 있는 오류를 미연에 방지한다. 예를 들어 원본 데이터와, 완벽하게 가공된 데이터 테이블이 같은 공간에 있을 경우, 데이터 테이블을 잘 모르는 사용자가 정제 전의 데이터에 접근하여 그 데이터를 사용하여 의사 결정을 내릴 수 있고, 이는 비즈니스에 치명적인 문제를 야기할 수 있다.
- 활용 목적에 따른 최적화 : 데이터의 활용목적에 따라서 데이타를 분류한다. 예를들어, 비즈니스 의사 결정의 경우에는 원본 데이터 보다, 정재되고 비즈니스 의미에 맞는 매출, 손익 분석과 같은 고급 데이터가 필요하다. 만약에 머신러닝 모델을 만든다면, 이렇게 함축된 의미의 데이터 보다는 1차 정제된 (NULL이나, Outlier가 없는) 데이터가 필요하게 된다. 이렇게 계층별로 데이터를 분류 저장함으로써, 용도에 맞는 사람이 보다 손쉽게 데이터에 접근하도록 한다.
- 데이터 흐름 추적 : 각 계층을 거치면서 데이터가 어떻게 정재되고 변환되는지에 대한 추적이 가능하다. 또한 원본 데이터를 저장함으로써 데이터가 어떻게 변환 과정에 대한 감사를 수행하여 데이터에 대한 신뢰성을 확보할 수 있다.
- 데이터 복구 및 재처리 : 원본 데이터를 항상 저장하고 있기 때문에, 상위 레이어에서 문제가 발생하여 데이터가 유실 되었더라도, 원본 데이터 재처리를 통해서 상위 레이어의 데이터를 복구할 수 있다.
메달리온 아키텍처의 구현
메달리온 아키텍처는 데이터를 계층적으로 나눈다는 개념만 가지고 있을뿐 데이터를 계층별로 분류하는 기술이나, 저장소에 대한 개념을 구체적으로 정의하지 않는 개념적 아키텍처이다.
즉 Bronze, Silver, Gold 데이터를 S3에 파일 형태로 저장할 수 도 있고, Bronze는 S3에 파일로, Silver는 Snowflake에 테이블형태로, 최정 분석 데이터는 Postgres에 저장하는 구조를 가질 수 도 있고, 또는 Bronze, Silver, Gold 데이터를 모두 테이블형태로 BigQuery에 저장할 수 있다.
계층에 대한 명확한 구분만 따른다면, 구현 방식에 대한 제약은 없다는 것이다.
또한 계층간의 데이터 정제 및 이동은 위의 그림에서는 ETL을 사용하는 것으로 했지만 데이터를 Bronze데이터를 빅쿼리에 저장한 후에, ELT 방식으로 SQL을 이용하여 정재한 후에, Silver 계층의 테이블에 저장하는 것과 같이 계층간의 데이터 이동에 대해서도 제약사항을 가지고 있지 않다.
계층별 설명
브론즈 계층
처음 수집된 원본 데이터가 저장되는 곳으로, 삭제나 변형 없이 수집된 그대로를 저장한다. 주로 append 방식으로 기존에 있는 데이터에 쌓는 방식으로 저장한다.
브론즈 계층에 저장된 데이터는 데이터의 품질을 분석하거나 데이터 수집 파이프라인에 대해서 운영 관점에서 검증을 하는 용도로 사용되거나 또는 감사(Audit)목적으로 사용된다.
실버 계층
실버 계층은 브론즈 계층에 저장된 원본 데이터에 대한 정제 작업을 한 데이터가 저장된다. 중복제거나 NULL 값을 제거하거나 아웃라이어(OutLier) 제거, 포맷이나 데이터 범주등을 맞추는 작업을 해서, 사용가능한 형태의 데이터가 되는 단계이다.
정재 작업만 끝난 데이터이기 때문에, 데이터의 특성을 분석하기 위한 데이터로 사용하기 좋다. 데이터 사이언티스트등이 이 데이터를 통해서 인사이트를 추출할 수 있다. 또는 이 데이터를 활용하여 머신러닝 학습 데이터로 사용될 수 있다.
골드 계층
골드 계층은 정제가 끝난 데이터를 이용하여, 비즈니스적인 의미를 갖는 테이블을 만들어내는 것으로, KPI, 대시보드, 데이터 리포팅등에 사용된다. 주로 데이터 웨어하우스에 저장된다. 매출 테이블, 수익 테이블과 같이 비즈니스 의사 결정을 위한 테이블이 저장되며, 바로 BI 리포팅 도구에 연결되어 시각화를 통하여 의사결정에 사용될 수 있다.
'빅데이타 & 머신러닝' 카테고리의 다른 글
| 빅데이터 분석을 위한 ELT 플랫폼 BQ Workflow vs Dataform (0) | 2025.02.27 |
|---|---|
| 분산형 데이터 분석 아키텍처-데이터 매쉬 (3) | 2021.01.04 |
| 파이썬을 이용한 데이타 시각화 #1 - Matplotlib 기본 그래프 그리기 (3) | 2017.09.23 |
| 데이타 워크플로우 관리를 위한 Apache Airflow #1 - 소개 (2) | 2017.07.15 |
| BI 툴 태블로(Tableau) (0) | 2016.03.14 |