파이토치의 모델 코드 구조를 이해해보자.
먼저 가장 간단한 선형 회귀 모델 코드를 살펴보자. 아래는 전체 코드 블럭이다.
아래 코드는 "모두를 위한 딥러닝 시즌 2 파이토치 편"을 참고하였다. https://deeplearningzerotoall.github.io/season2/lec_pytorch.html
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[1], [2], [3]])
# 모델 초기화
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=0.01)
nb_epochs = 1000
cost_list = []
for epoch in range(nb_epochs + 1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
cost_list.append(cost.item()) # cost 값을 리스트에 추가
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
params = list(model.parameters())
W = params[0].item()
b = params[1].item()
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'
.format(epoch, nb_epochs, W, b, cost.item()
))
x_train과 y_train은 학습용 데이터이고, 모델을 정의하는 부분은 nn.Module을 상속받은 LinearRegression 클래스를 통하여 아래와 같이 구현한다.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)nn.Linear(1,1)로 하나의 퍼셉트론 (W*X + Y)를 생성한다. 입력 차원은 1, 출력 차원은 1로 한다.
그리고, 모델을 forward에서 정의한다. self.linear(x)를 통하여 하나의 퍼셉트론으로된 모델을 정의하였다. 향후에 딥러닝 모델을 만들때는 각 레이어를 __init__ 부분에서 정의하고, forward 부분에서 이 레이어들을 쌓아올려서 모델을 정의하게 된다.
다음으로 생성된 모델 클래스로 부터, 모델 (model)을 정의하고, 사용한 옵티마이저를 정의하고 러닝레이트를 인자로 넘긴다.
여기서는 SGD (그라디엔트 옵티마이저)를 사용하였다.
model = LinearRegressionModel()
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=0.01)
다음, 모델 학습 코드를 구현한다.
for epoch in range(nb_epochs + 1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
cost_list.append(cost.item()) # cost 값을 리스트에 추가
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
prediction에 모델에 학습 데이터를 넣어서 예측된 값을 리턴받고
이 prediction 결과와, 학습 라벨 데이터(y_train)을 이용하여 loss(cost) 함수를 이용하여 코스트를 계산한다. 이 예제에서는 MSE (Mean Square Error)를 코스트 함수로 사용하였다.
다음 Optimizer.zero_grad()로 옵티마이저의 기존의 기울기 값을 초기화 한후에, cost.backward()를 이용하여, 계산된 값을 역전파 한후에, optimizer.step()을 이용하여, optimizer의 기울기 값을 업데이트 한다.
이 3 함수는 패키지 처럼 붙어 다니기 때문에 일반적인 경우에는 이 3개의 함수를 같이 사용하면 된다.
학습이 제대로 되는지를 확인하기 위하여, Cost 함수를 그래프로 나타내보면 다음과 같다.
import matplotlib.pyplot as plt # matplotlib 임포트
epochs = range(nb_epochs + 1) # epoch 값을 리스트로 저장
plt.plot(epochs, cost_list) # 그래프 그리기
plt.xlabel('Epoch') # X축 레이블 설정
plt.ylabel('Cost') # Y축 레이블 설정
plt.show() # 그래프 출력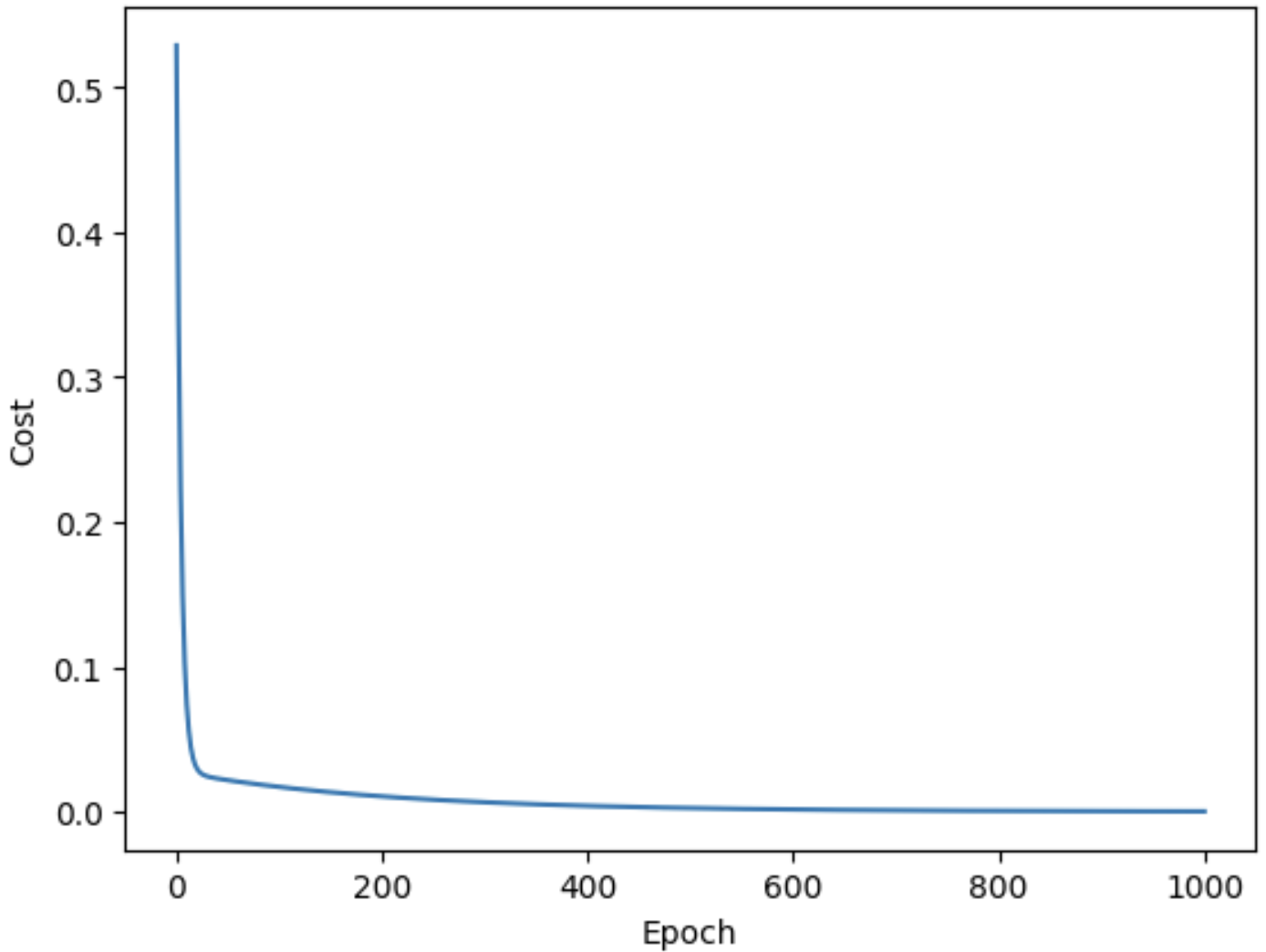
'빅데이타 & 머신러닝 > Pytorch' 카테고리의 다른 글
| 5. 파이토치 - 분산 학습의 개념과 하드웨어 (1) | 2024.09.03 |
|---|---|
| 파이토치 분산 학습 도구 비교 (0) | 2024.08.20 |
| 파이토치 4 - 쿠버네티스에서 학습하기 (0) | 2024.08.19 |
| 파이토치 3. 파이토치라이트닝 (0) | 2024.08.16 |
| 파이토치 1. 기본 자료형 텐서 (0) | 2024.08.05 |