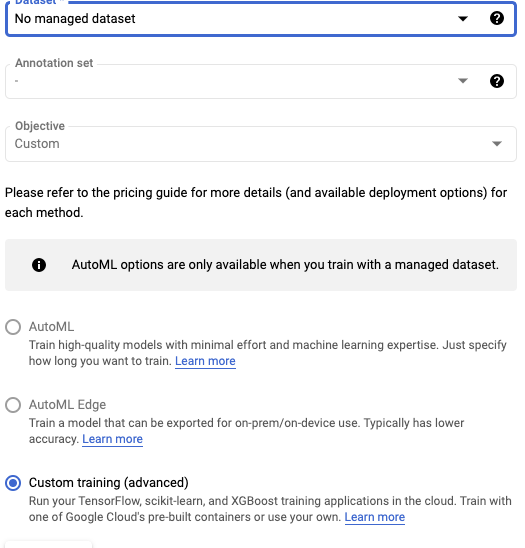
Vertex AI : 모델 학습 및 하이퍼 패러미터 튜닝 조대협 (http://bcho.tistory.com) 가장 기본적이지만 클라우드를 사용하면서 가장 효과적인 기능이 모델 학습과 하이퍼 패러미터 튜닝이다. 모델 학습을 위해서는 CPU/GPU 고사양의 컴퓨터가 필요하지만, 이 고사양의 컴퓨팅 파워가 항상 이용되는 것이 아니라. 학습때 많은 컴퓨팅 자원이 필요하기 때문에, 온프렘등에서 장비를 사놓고 학습때만 사용하고 평소에 장비를 사용하지 않는 것 보다는 학습때만 클라우드에서 컴퓨팅에서 컴퓨팅 자원을 사용하는 것이 오히려 비용 효율적이라고 볼 수 있다. 하이퍼 패러미터 모델을 학습함에 있어서 모델에는 여러가지 튜닝이 가능한 패러미터가 있다. 예를 들어 학습 속도 (Learning Rate)나, 또는 뉴..