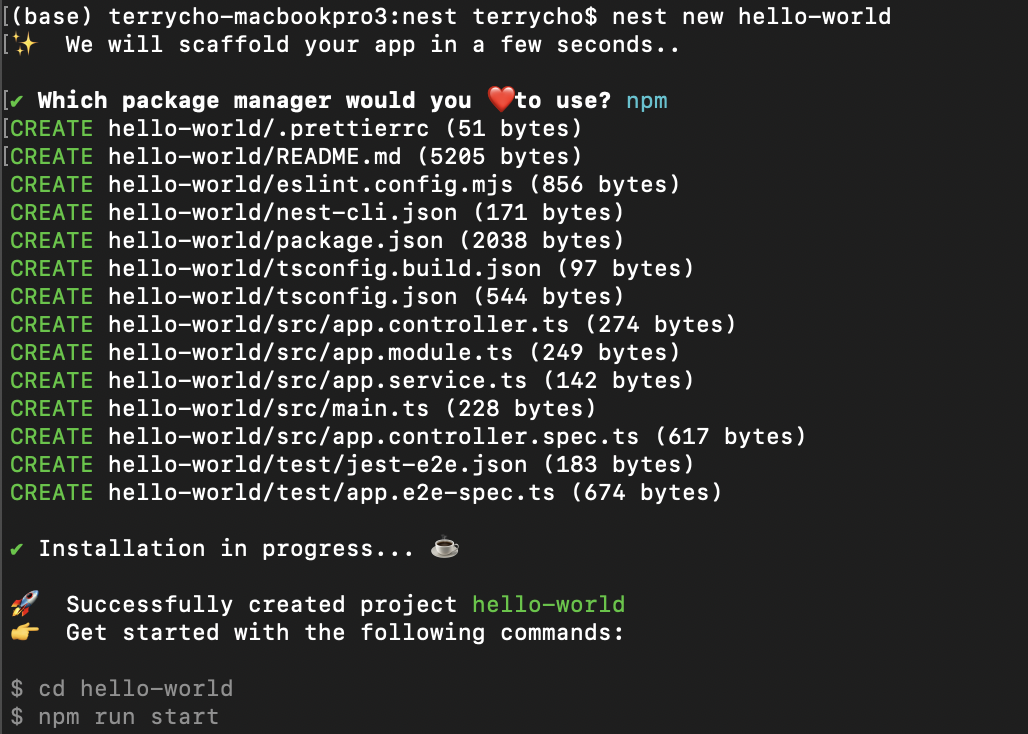
Nest.JS 살펴보기 - 2. Hello World조대협 (http://bcho.tistory.com)1. 프로젝트 생성:터미널을 열고 다음 명령어를 실행하여 hello-world라는 이름의 Nest.js 프로젝트를 생성한다.nest new hello-world프로젝트 생성 과정에서 패키지 매니저를 선택하라는 메시지가 나타나면 npm을 선택한다. 프로젝트 생성이 완료되면 hello-world 디렉토리로 이동한다. cd hello-world2. 주요 파일 설명:생성된 프로젝트에는 다음과 같은 주요 파일들이 있다.src/app.controller.ts: 애플리케이션의 컨트롤러를 정의하는 파일이다. 컨트롤러는 클라이언트로부터 들어오는 요청을 처리하고, 그에 대한 응답을 반환하는 역할을 수행한다. 라우팅 로직..