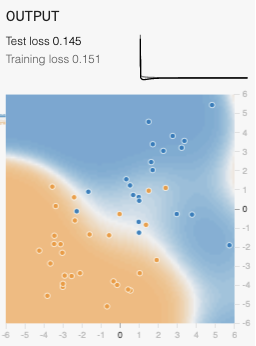
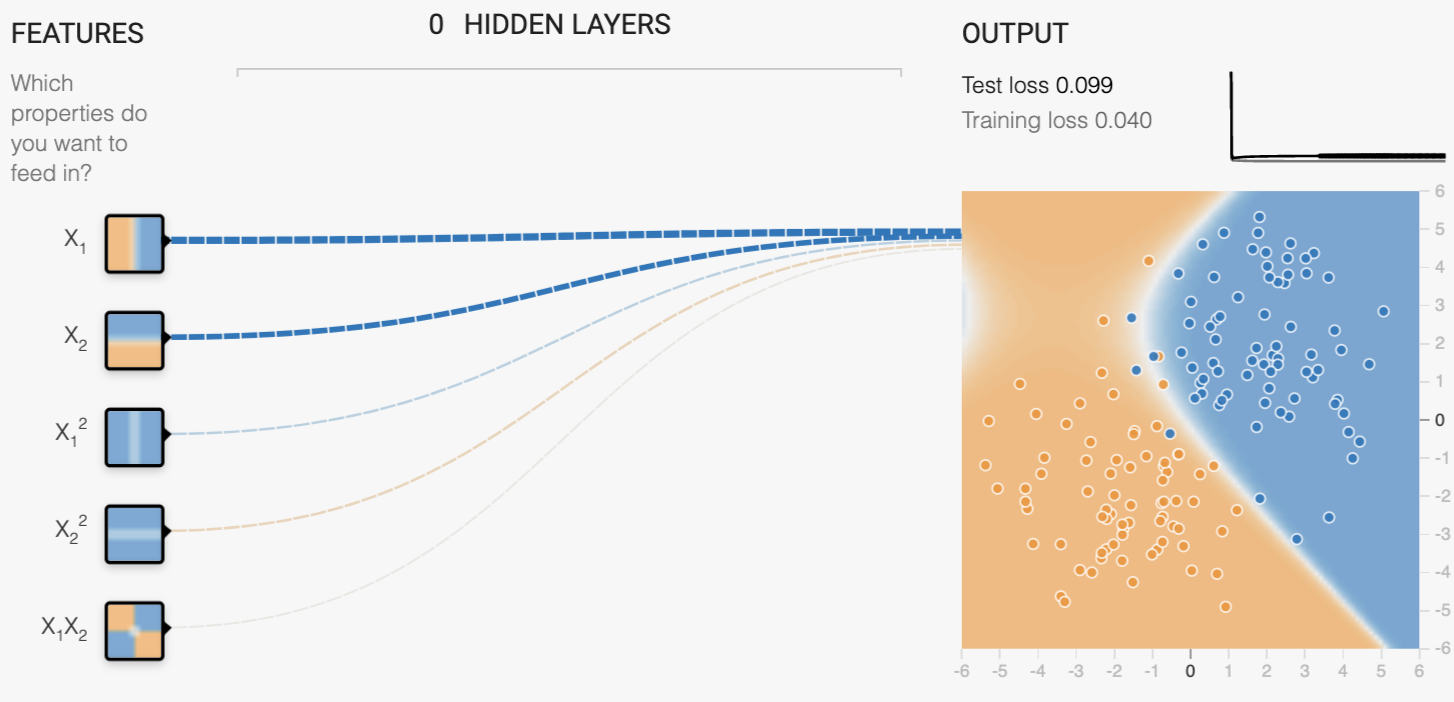
머신러닝 모델 학습에서 일어나는 오버피팅 문제를 해결하기 위한 방법으로 여러가지 방안이 있는데, 뉴럴 네트워크에서 drop out , Early stopping (모델이 오버피팅 되기전에 학습을 멈추는 방법) 등이 있다. 여기서 살펴볼 내용은 오버피팅을 해결하기 위한 기법중의 하나인 L2 Regularization이다. 일반적으로 loss 함수는 아래 그림과 같이 (y-y':원본데이타 - 예측데이타) 의 차이를 최소화하는 값을 구하는 식으로 되어 있다. L2 Regularazation 기법은 이 Loss 함수의 값 뿐만 아니라, 모델의 복잡도를 최소화하는 weight 값을 차는 방식으로 식을 변형한다. 모델의 복잡도에 대한 계산은 weight 값의 최소값을 구하는 방식을 사용하는데, L1 Regularz..