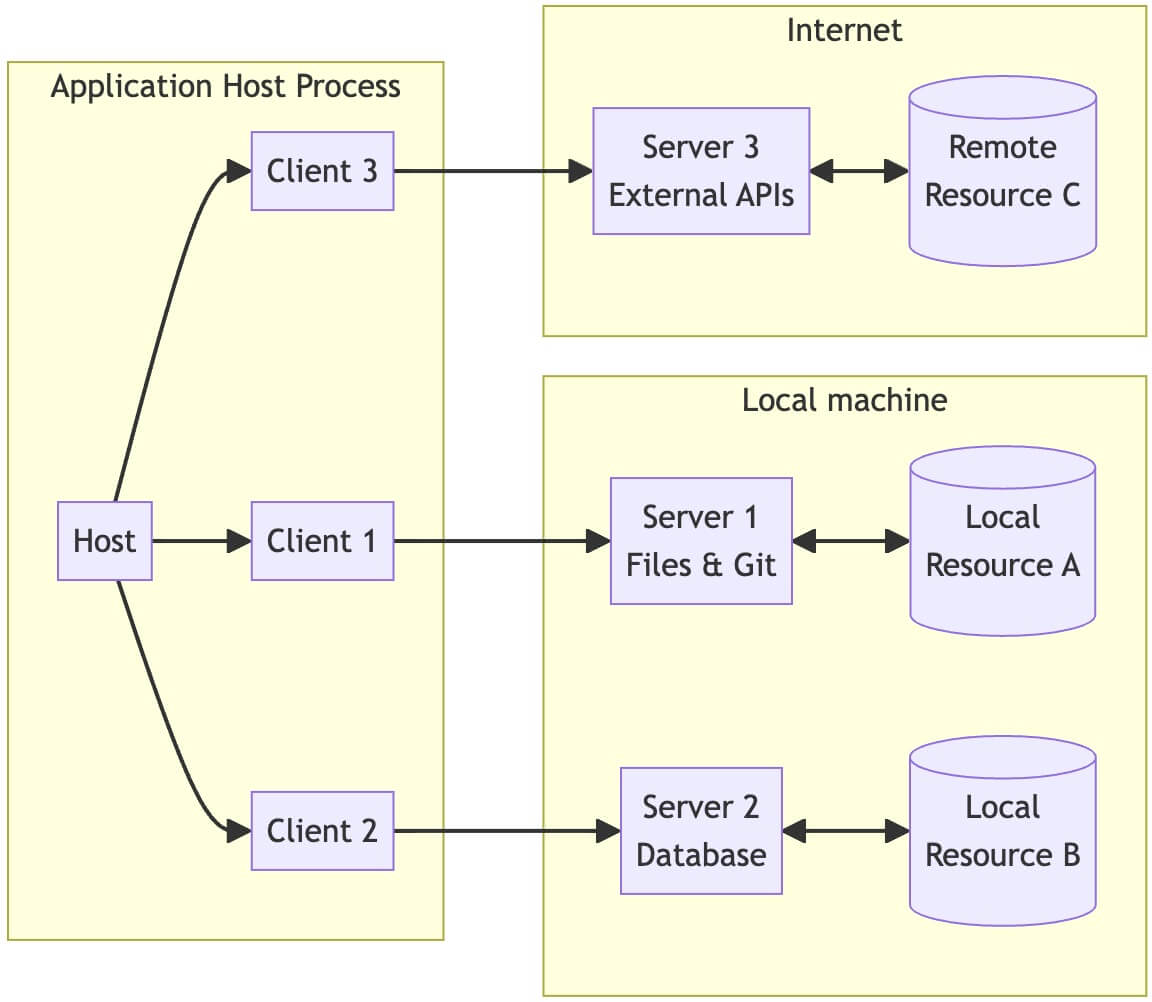
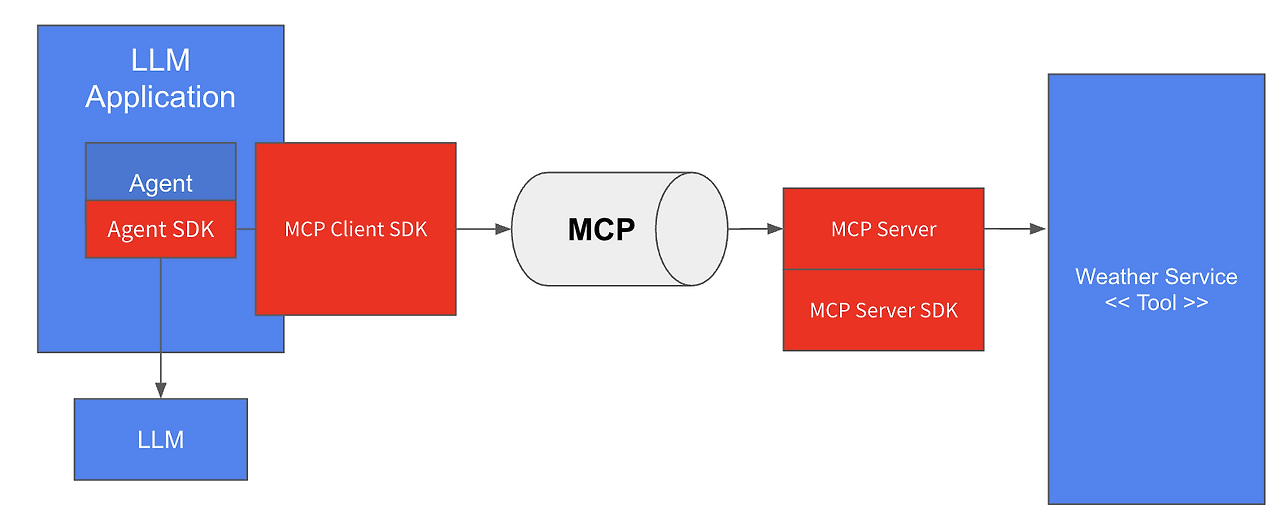
조대협 (http://bcho.tistory.com)지난 글을 통해서 MCP의 개념에 대해서 간략하게 이해해봤다. 이번글에서는 그러면 어떻게 MCP 서버를 실제로 구현하는지에 대해서 알아보도록 한다. MCP Local server & remote serverMCP server 는 구동 위치에 따라서, 로컬 서버와 리모트 서버로 분리된다. 아래는 Anthropic 의 아키텍처 다이어그램이다. 로컬 서버의 경우, MCP 애플리케이션 호스트 프로세스가 기동되는 로컬 데스크탑에서 실행되는 서버이고, 리모트 서버는 클라우드나 기타 네트워크로 접속될 수 있는 환경에서 기동되는 서버이다. 로컬 서버의 경우에는 같은 데스크탑에서 실행되기 때문에, 로컬 자원, 즉 데스크탑의 파일 등에 접근할 수 있다.(노트 : 이는..