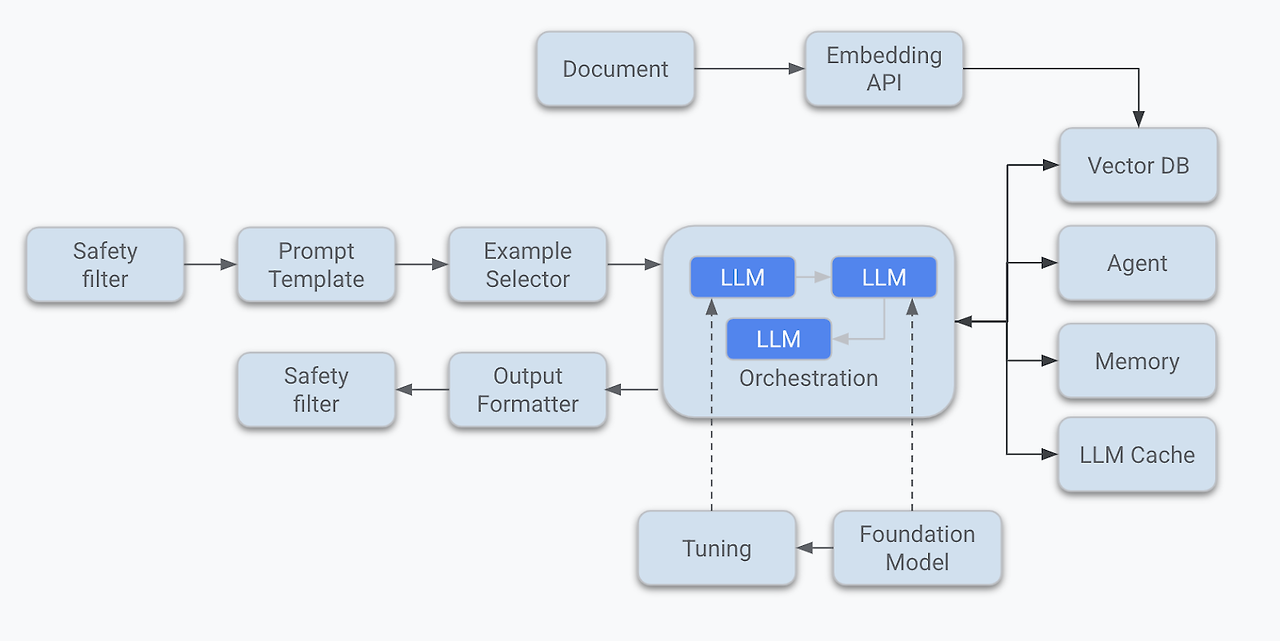
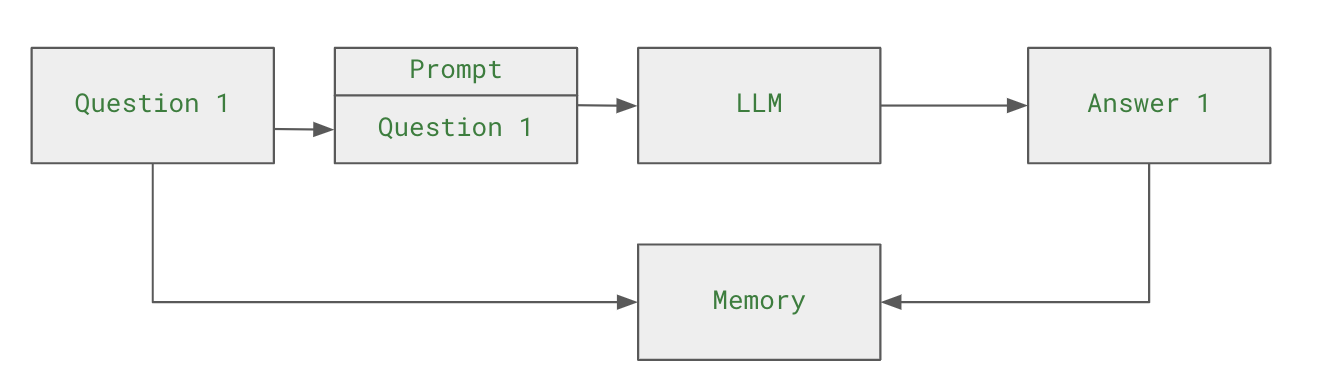
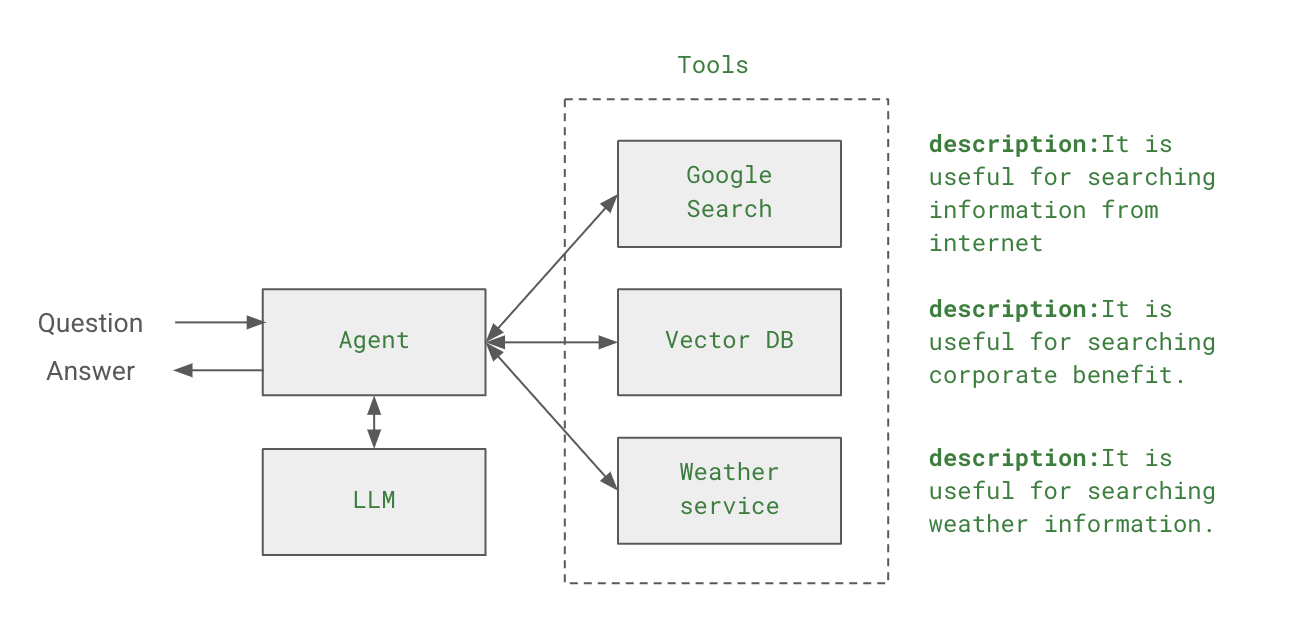
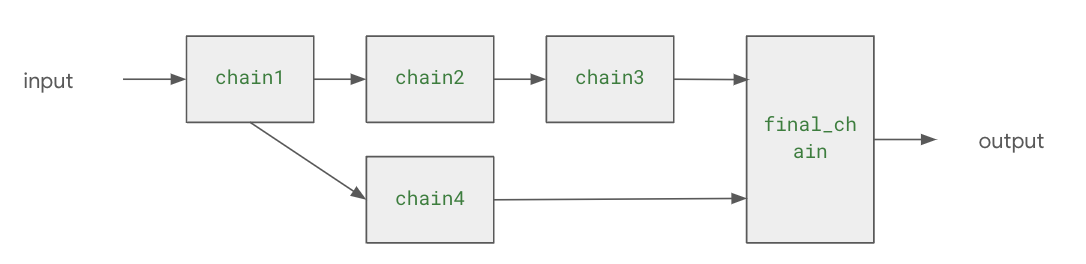
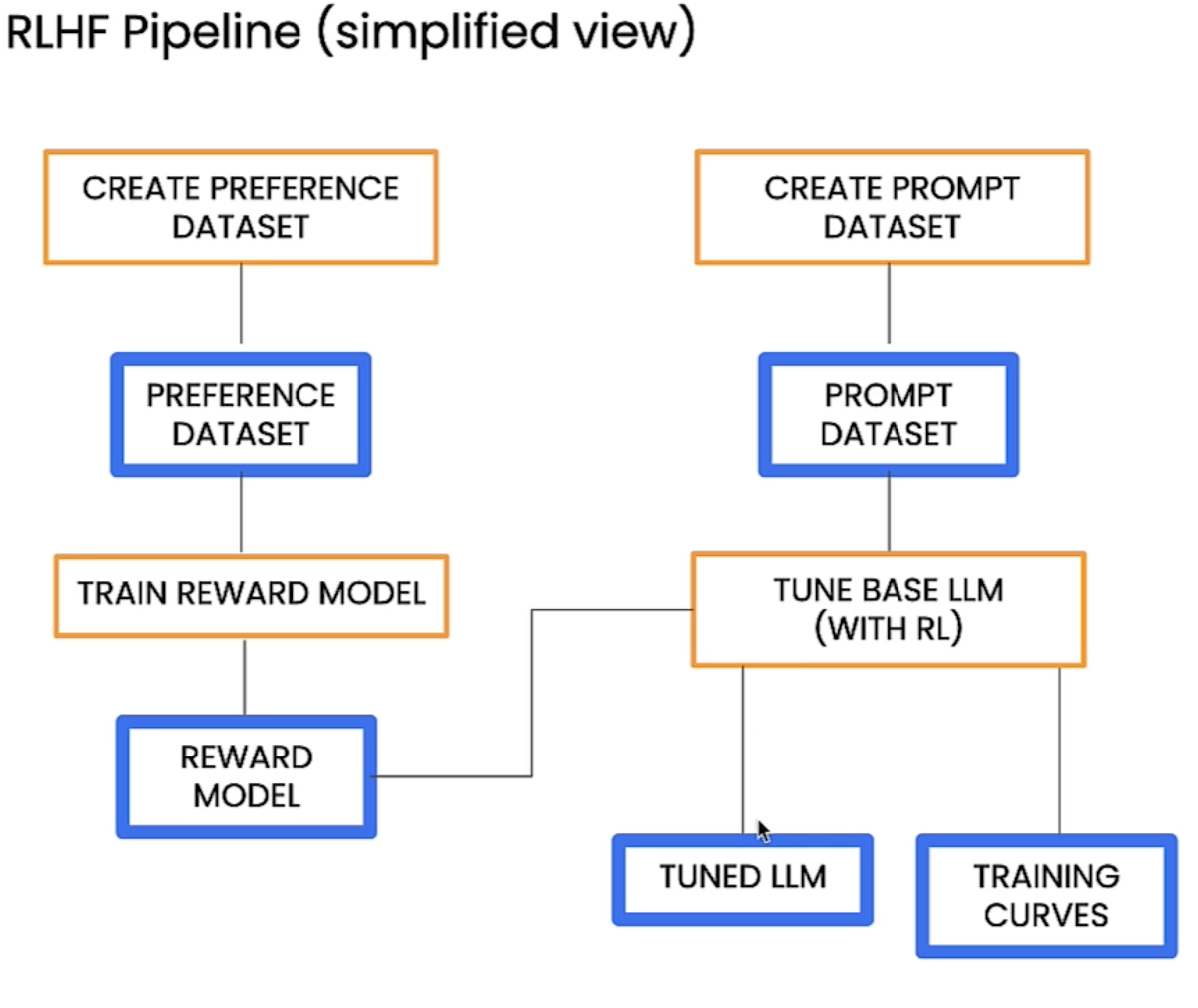
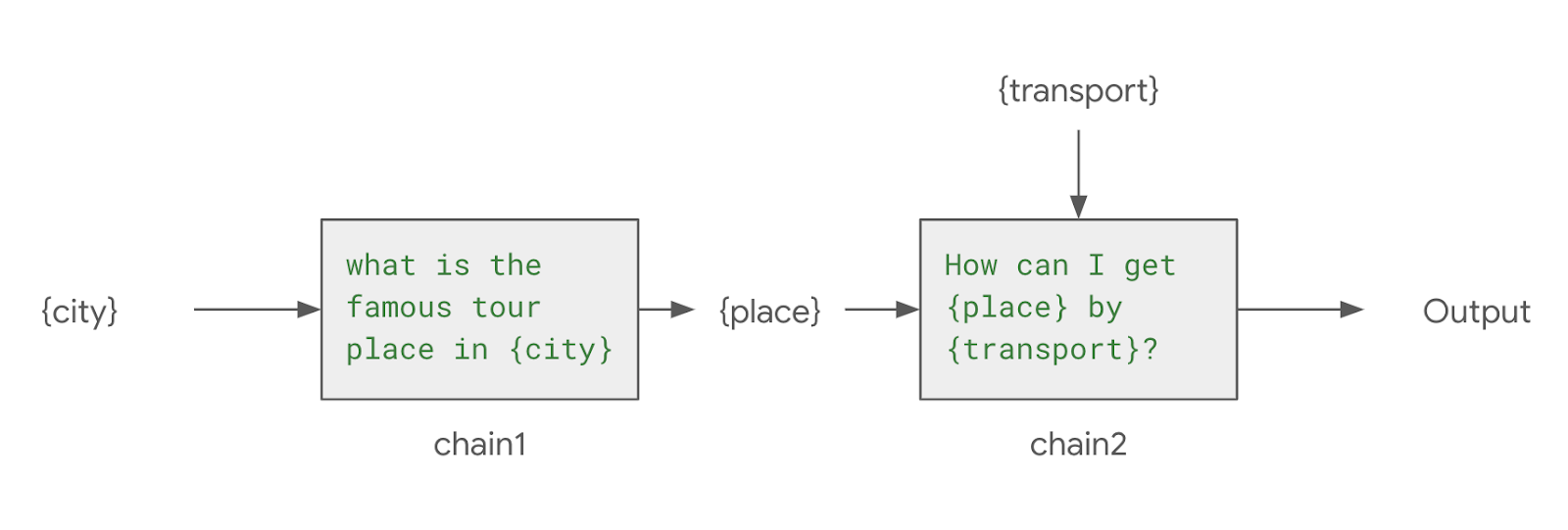
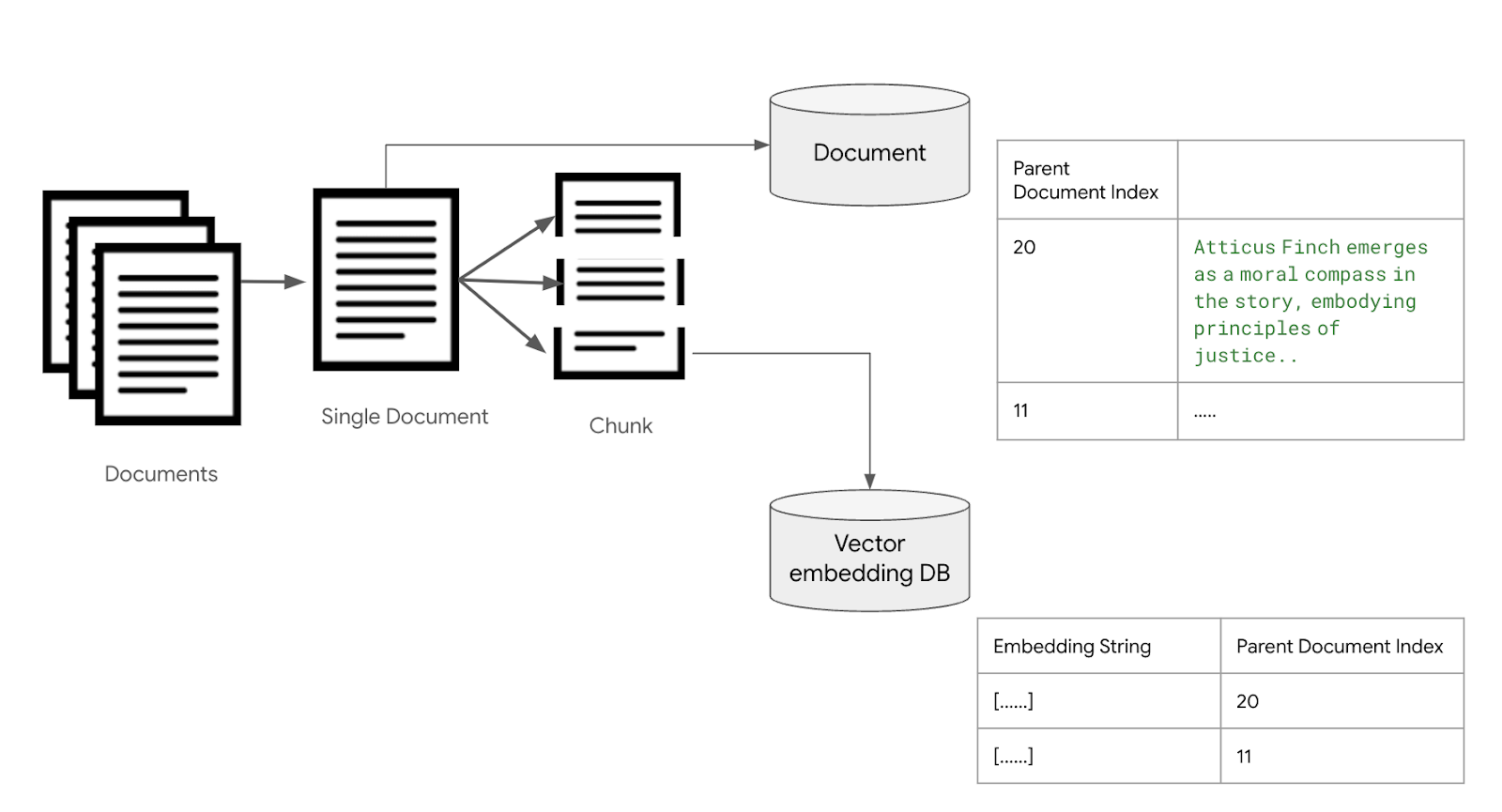
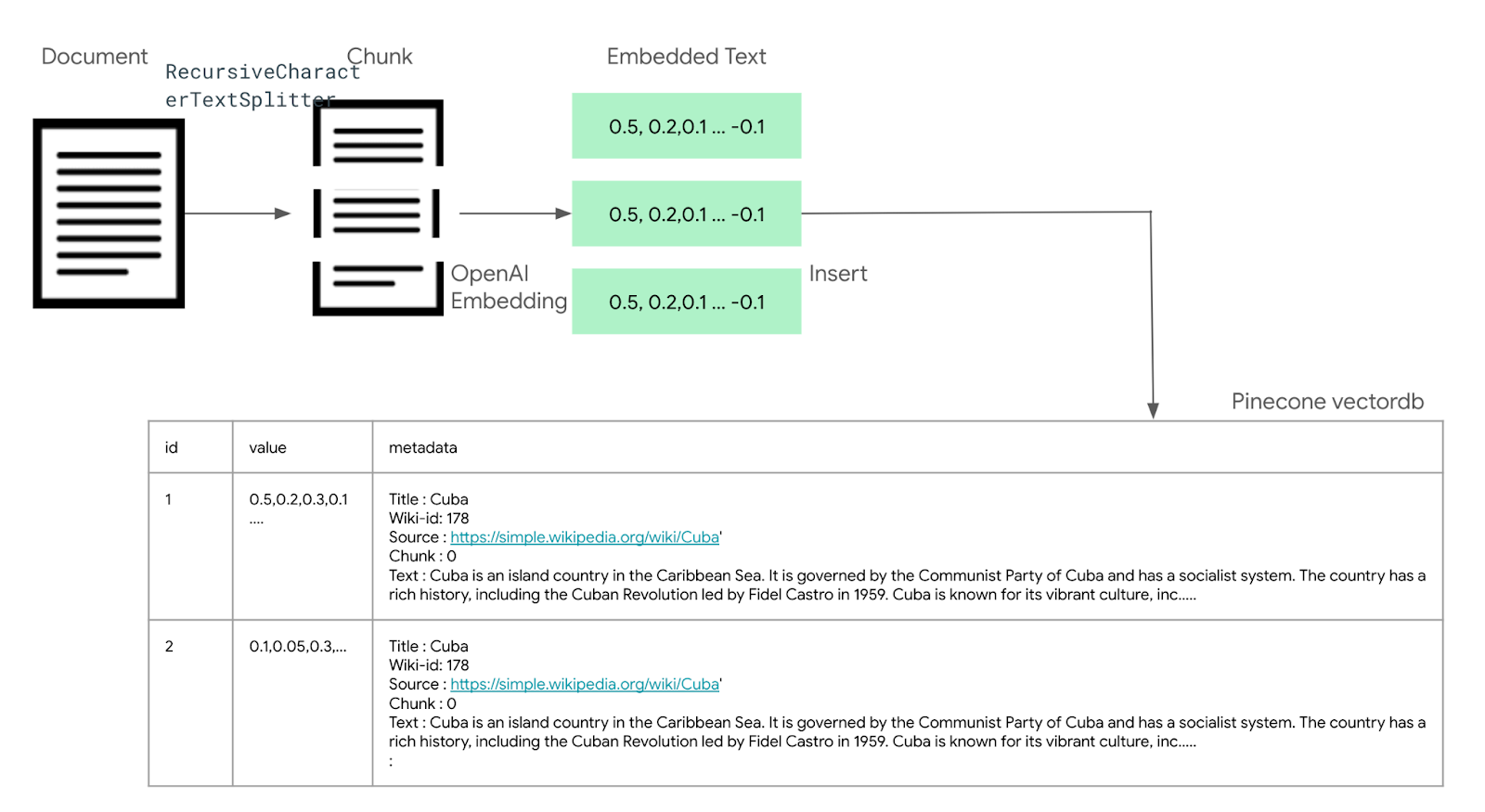
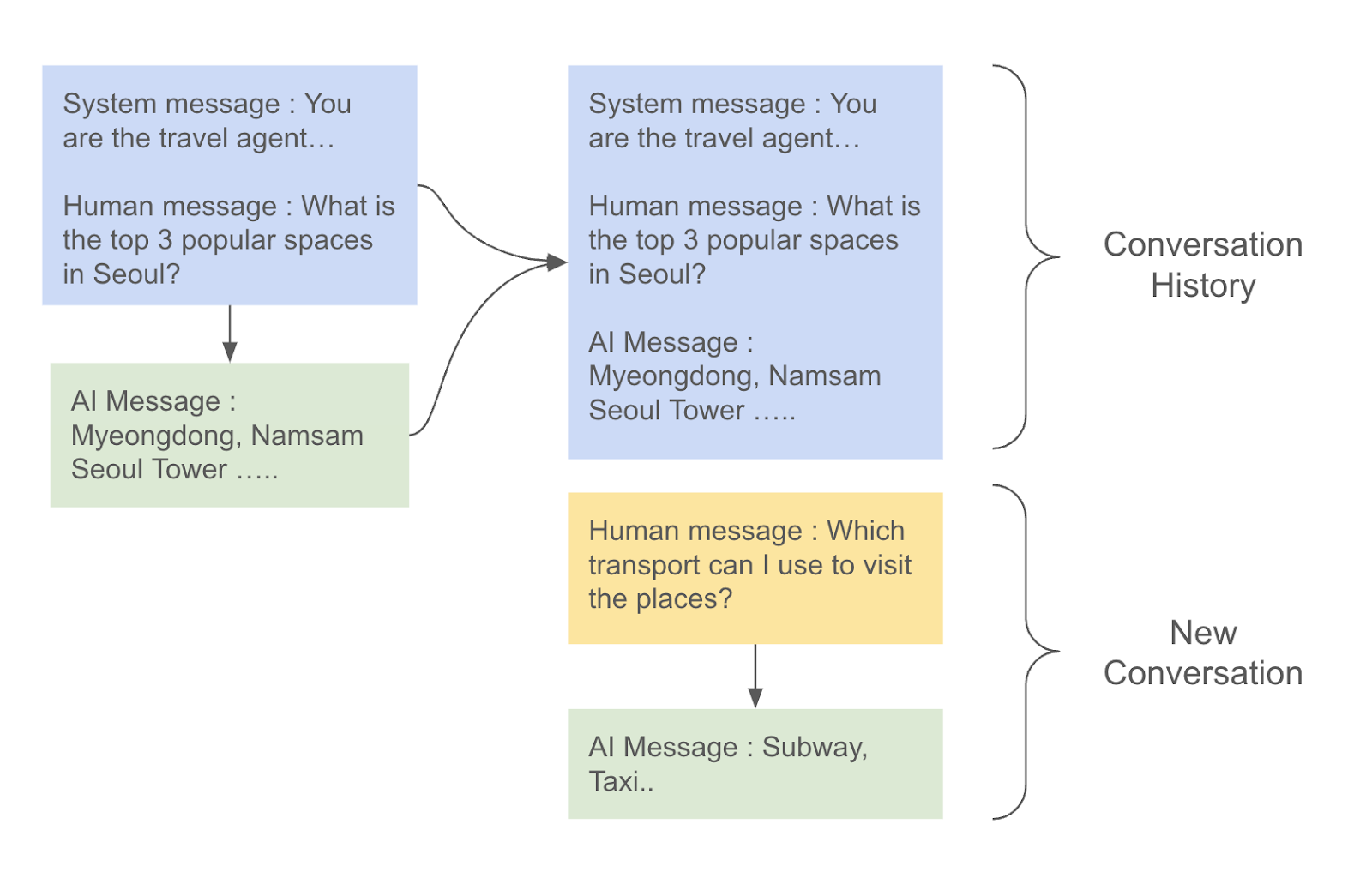
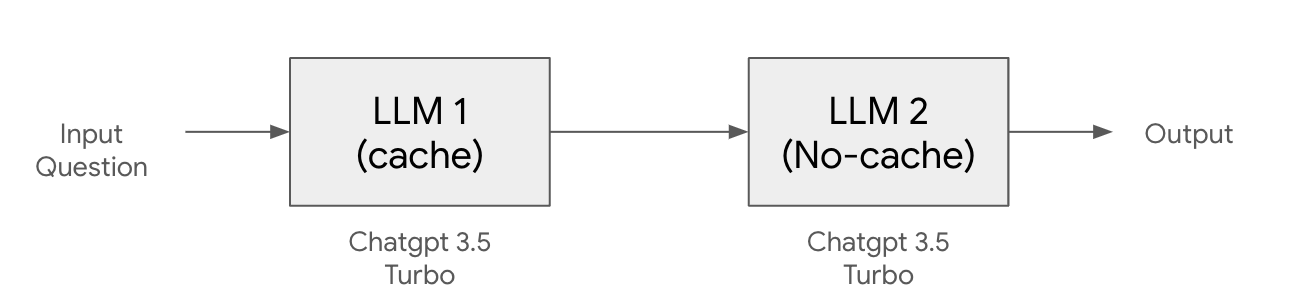
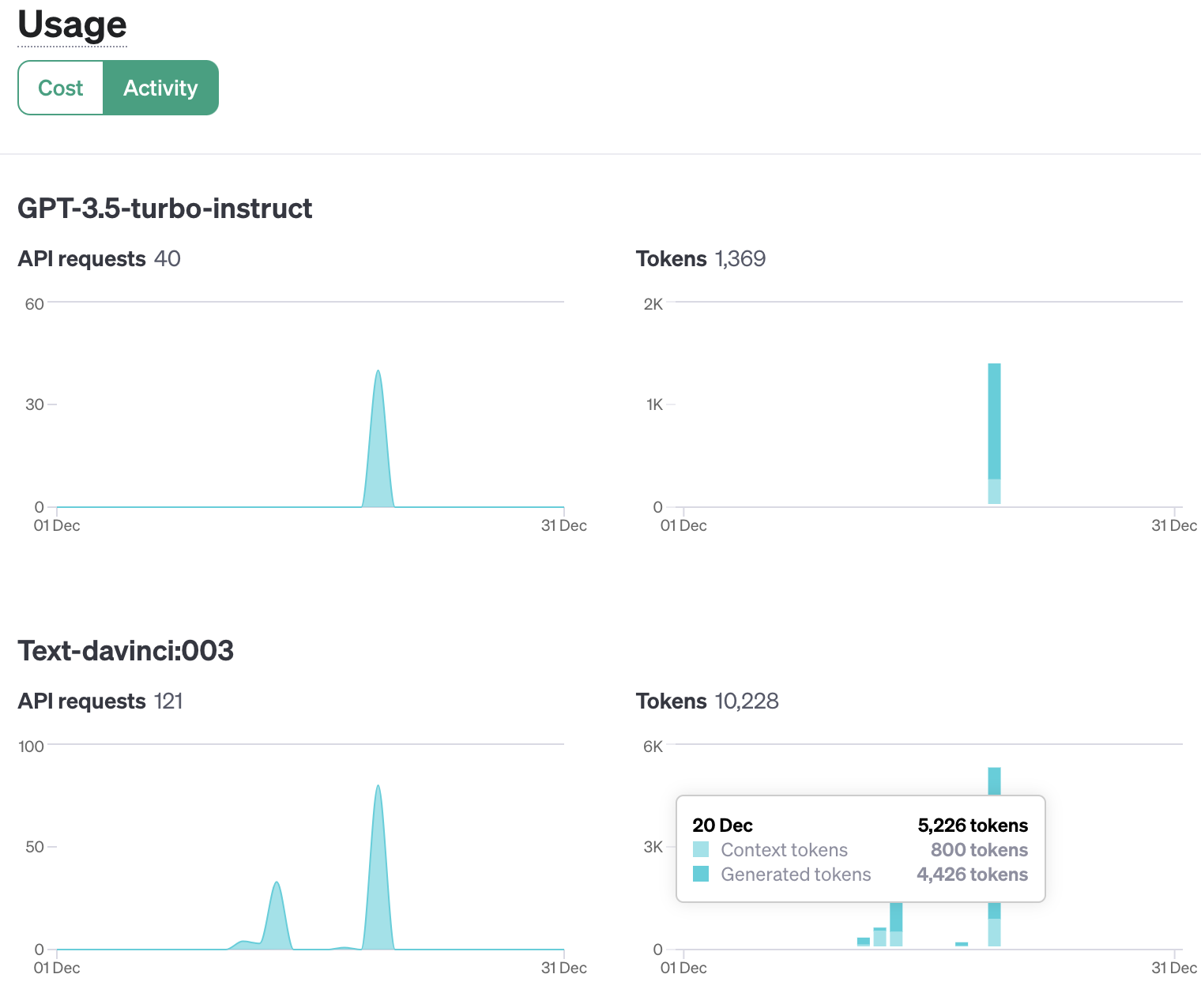
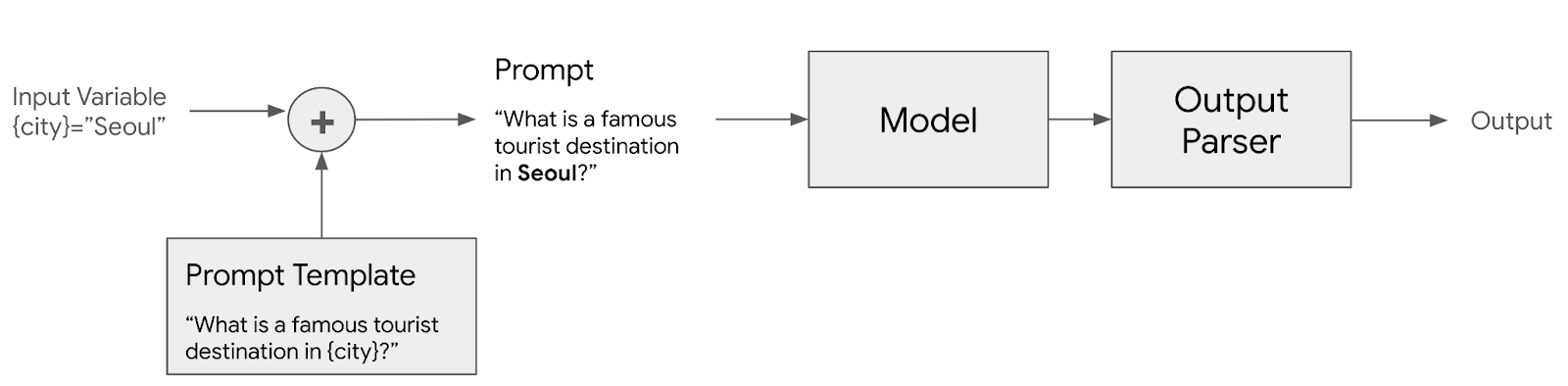
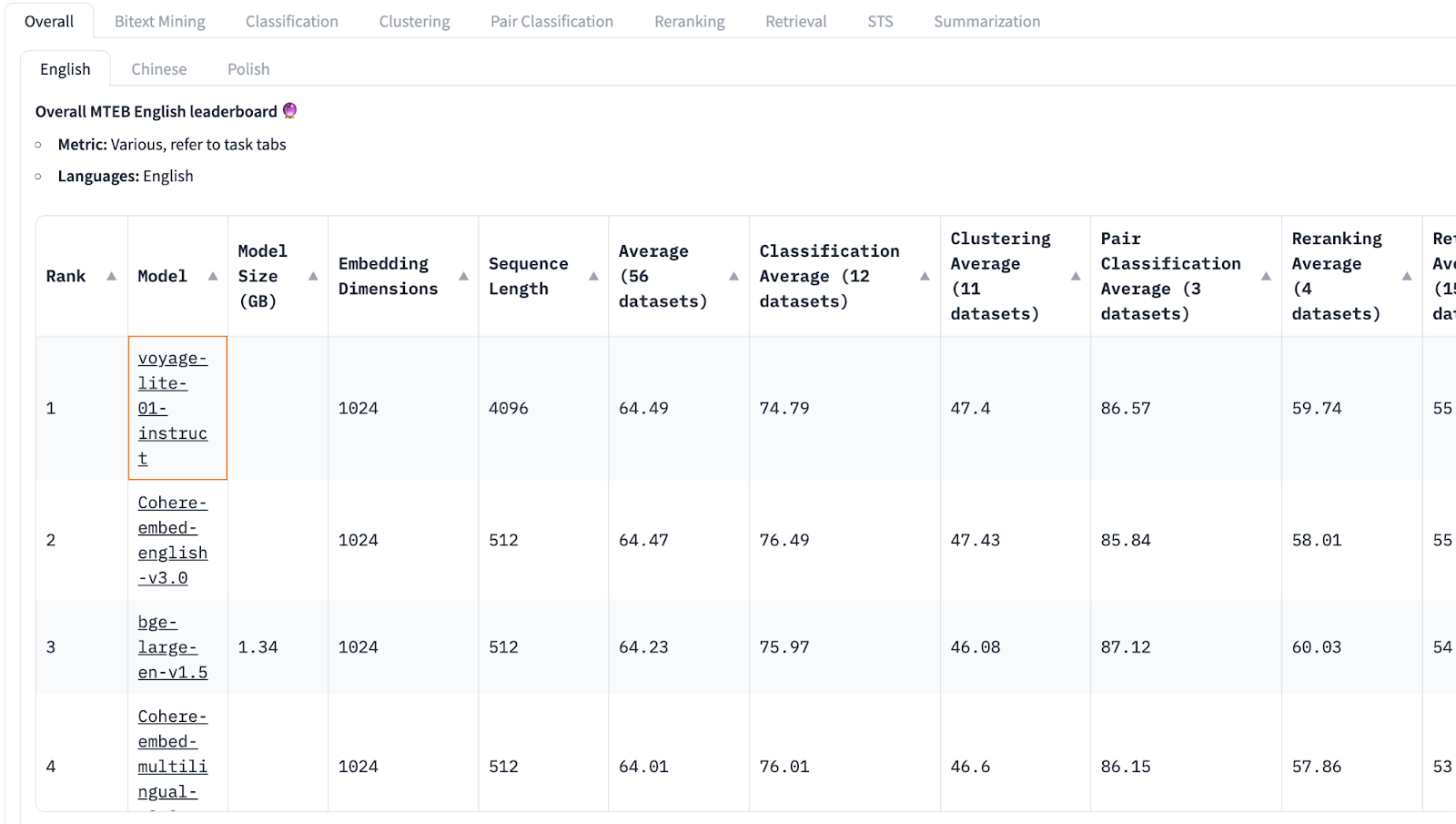
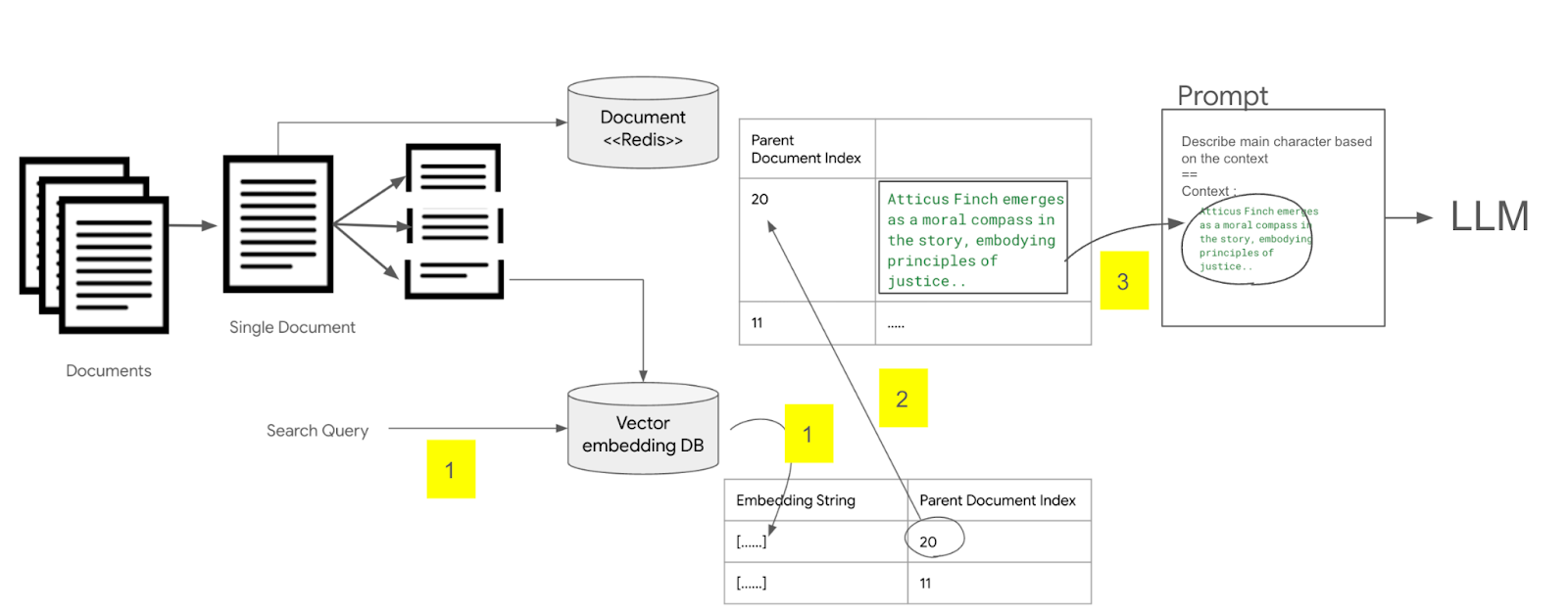
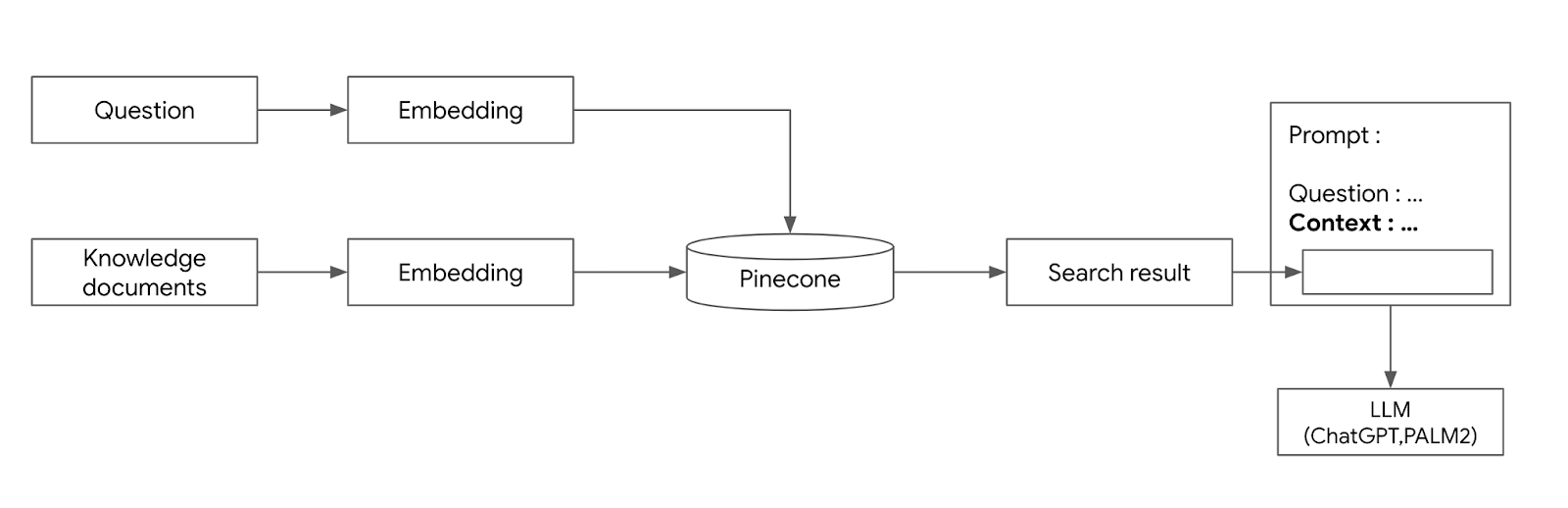
LLM 애플리케이션 아키텍처 (1/2) 조대협 (http://bcho.tistory.com) ChatGPT나, Gemini 모델과 같은 LLM 을 이용한 애플리케이션을 개발하는 형태를 보면, 보통 LLM에 프롬프트 엔지니어링을 사용한 프롬프트를 입력으로 사용하고, 리턴을 받아서 사용한다. 그리고 약간 발전된 형태의 경우에는 파인 튜닝을 사용하거나, 아주 발전된 형태는 외부 문서 저장소를 사용하는 형태 정도의 수준으로 개발한다. 즉 LLM을 한번 정도 호출하는 정도의 구조를 가지고 있다. 그러나 운영환경에 올라가는 LLM 기반의 애플리케이션의 구조는 이것보다 훨씬 복잡하다. 아래 그림은 LLM 애플리케이션의 아키텍처 예시이다. 단순하게 프롬프트를 작성해서 LLM을 한번만 호출하는 것이 아니라, 여러 예제를..