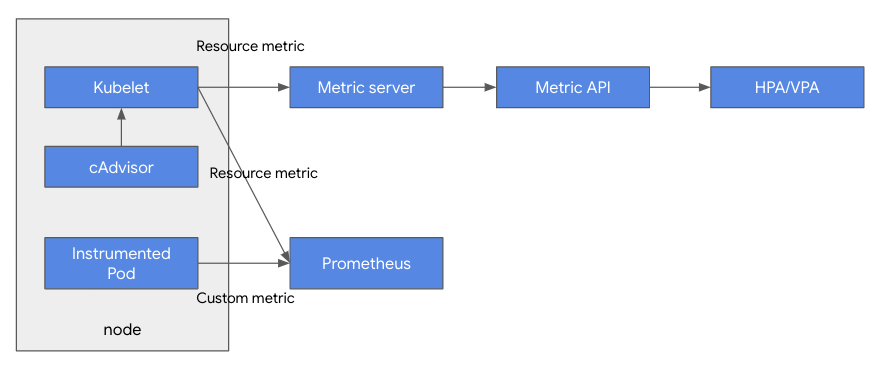
쿠버네티스의 HPA/VPA 오토스케일링을 위한 모니터링 아키텍처 조대협 (http://bcho.tistory.com) 쿠버네티스에서 HPA/VPA는 내부 메트릭을 이용하여 오토스케일링을 판단하는데, 이를 위해서 내부 메트릭을 수집하고 서빙하기 위한 모니터링 아키텍쳐가 어떻게 구현되었는지에 대해서 알아본다. 각 노드에서 동작하는 컨테이너에 대한 리소스 정보 (CPU,메모리, 네트워크 사용량)은 cAdvisor를 통하여 수집되어 Kubelet을 통해서, 컨트롤 플레인에 전달된다. cAdvisot는 컨테이너에 대한 리소스 정보만 수집하지만, Kubelet은 컨테이너 이외의 노드나 애플리케이션에 대한 정보를 수집한다. 이렇게 Kubelet에 저장된 정보는 metric server로 전달되고, metric api..