지금까지 살펴본 Retriever 들은, chunk 의 원본 문서 또는 문장을 저장할때 벡터 데이터 베이스에 text 필드에 저장하였다. 보통 한 문서 또는 한 문장은 여러개의 chunk로 분할되어 각각 저장되기 때문에 원본 Text가 중복되서 저장되는 문제점이 있고 이로 인하여 데이터 베이스 용량이 커지는 문제가 있다.
또는 원본 문서의 크기가 클때는 데이터 베이스 싱글 컬럼에 저장이 안될 수 도 있다.
이러한 문제를 해결하기 위한 구조를 parent-child chunking 이라고 하는데, langchain에서는 ParentDocumentRetriever 를 통해서 이 구조를 지원한다.
기본 원리는 chunk를 저장할때 chunk에 대한 원본 텍스트를 저장하지 않고, 원본 문서는 별도의 문서 저장소에 저장한 후에, 검색된 chunk의 원본 문서에 대한 포인트를 가지고 문서 저장소에서 원본 문서를 찾아오는 방식이다.
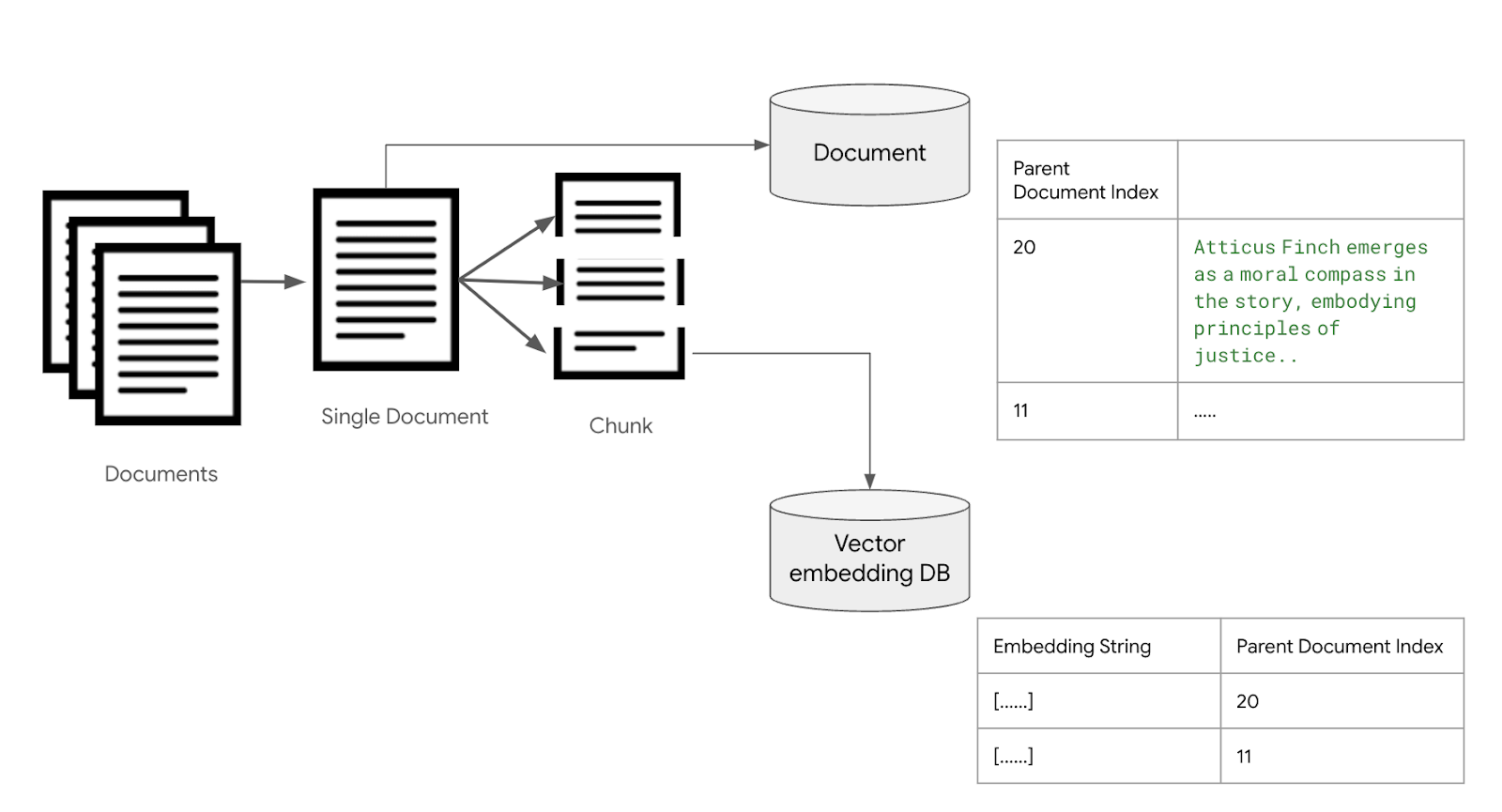
<그림 Parent-Child Chunking 구조>
ParentChildRetreiver를 사용하려면 문서를 벡터데이터 베이스에 저장하는 것 부터 Retriever를 사용해야 한다.
아래 에제는 ./Korea_info 라는 디렉토리에 들어있는 한국에 관련된 정보 파일 Korea Transport.txt,Korea things todo.txt,Korean food.txt,Korean tourist destination.txt 파일 4개를 각각 작은 chunk로 분할한 후에 pinecone 벡터 데이터 베이스에 임베딩된 형태로 저장하고, 원본 문서의 내용은 Memory에 저장해서, chunk 단위로 검색을 한후, chunk가 포함된 원본 문서 전체를 리턴하는 코드이다.
[예제 파일]
문서를 저장하는 예제를 먼저 살펴보자
import os
from langchain_community.document_loaders import TextLoader
from langchain.storage import InMemoryStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.retrievers import ParentDocumentRetriever
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
import pinecone
# load docs
text_dir = "./Korea info"
files = os.listdir(text_dir)
txt_files = [file for file in files if file.endswith(".txt")]
docs = []
print(files)
for file in txt_files:
docs.extend(TextLoader(text_dir+"/"+file).load())
#create embedding API and llm
os.environ["OPENAI_API_KEY"] = "{YOUR_OPENAI_KEY}"
embedding = OpenAIEmbeddings()
#Connect database
pinecone.init(api_key="{YOUR_PINECONE_APIKEY}")
index = pinecone.Index("terry-korea")
text_field = "text"
vectordb = Pinecone(
index, embedding.embed_query, text_field
)
# create text splitter
child_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=400,
chunk_overlap=20,
length_function=len,
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectordb,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
코드를 각 단계로 나눠서 설명하면, 첫번째로 ./Korea info 디렉토리에 있는 파일명을 docs 리스트에 저장한다.
# load docs
text_dir = "./Korea info"
files = os.listdir(text_dir)
txt_files = [file for file in files if file.endswith(".txt")]
docs = []
print(files)
for file in txt_files:
docs.extend(TextLoader(text_dir+"/"+file).load())
다음 임베딩에 사용할 OpenAIEmbedding API 객체를 생성하고, pinecone 벡터데이터 베이스를 연결한다.
#create embedding API and llm
os.environ["OPENAI_API_KEY"] = "{YOUR_OPENAI_KEY}"
embedding = OpenAIEmbeddings()
#Connect database
pinecone.init(api_key="{YOUR_PINECONE_APIKEY}")
index = pinecone.Index("terry-korea")
text_field = "text"
vectordb = Pinecone(
index, embedding.embed_query, text_field
)
문서를 여러 Chunk로 나누기 위해서 TextSplitter를 선언한다. 400자 단위로 Chunk를 나누도록 하고, 앞의 Chunk와 20자를 중첩하도록 한다.
# create text splitter
child_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=400,
chunk_overlap=20,
length_function=len,
)
준비가 끝났으면, ParentDocumentRetriever와 원본 문서를 저장할 InMemoryStore를 생성하고, reteriver.add_documents를 이용하여, 문서들을 지정하면, 문서를 자동으로 chunk 로 나눠서 벡터데이터베이스에 저장하고, 원본 문서는 메모리에 저장하게 된다.
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectordb,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
간단하게 구현하기 위해서 메모리 스토어를 사용하였지만, 운영환경에서는 적합하지 않다. 코드가 리스타트되게 되면, 메모리에 저장된 문서는 휘발성으로 지워지기 때문에, 운영환경에서는 파일시스템이나 Redis 스토어를 사용하기 바란다. 로컬 파일 시스템 스토어는 https://python.langchain.com/docs/integrations/stores/file_system 에 그리고 Redis 스토어는 https://python.langchain.com/docs/integrations/stores/redis 에서 찾을 수 있다.
이렇게 저장한 Chunk를 검색해보자.
# retrieve chunk
import json
from IPython.display import JSON
query = "What I can do in Korea ?"
sub_docs = vectordb.similarity_search(query)
print(sub_docs)
결과는 다음과 같다. 검색된 chunk 가 출력되었다.
Document(page_content='18. Learn Korean Culture - Dive into cultural immersion by learning age old handicrafts like pottery making or folk crafts like knotting fabric at camps designed to teach traditional practices at locales like Korean Folk Villages with talented elder masters imparting insightful customs through these time treasured arts.', metadata={'doc_id': '04673254-b6cb-40a3-b5f8-2f93bd5af4d1', 'source': './Korea info/Korea things todo.txt'}), .... 중략
만약에 이 chunk 가 포함된 parent 문서를 리턴 하려면 get_relevant_documents 메서드를 사용하면 된다.
# Retrieve full document
retrieved_docs = retriever.get_relevant_documents("query")
print(retrieved_doccs)
Parent Chunking 사용하기
Parent Retriever는 원본 문서를 리턴할 수 있기 때문에, 전체 컨택스트를 풍부하게 제공할 수 있는 장점은 있지만, 만약에 원본 문서 자체가 크게 되면, LLM Input 윈도우 사이즈 한계와 비용문제 때문에, 사용이 어렵다. 이런 문제를 해결하기 위한 방법으로 문서를 Large chunk로 나눠서 문서 저장소에 저장하고 이 Large chunk를 다시 small chunk로 나눠서 임베딩으로 인덱스 하는 방법이다.
즉 앞의 방법이 Parent Document → Small Chunk 두 단계로 나눈후에, 검색 결과로 Parent Document를 리턴했다면, 이 방식은 Parent Document → Large Chunk → Small Chunk 3단계로 나눈 후에, Large Chunk를 리턴하는 방식이다.
코드는 아래 변경되는 부분만 추가하였다.
먼저 Large Chunk 생성에 사용할 TextSpiltter를 선언한다. 여기서는 RecursiveCharacterTextSpiltter를 이용하여 2000자 단위로 LargeChunk를 사용하도록 하였다. 그리고 생성된 parent_spiltter를 ParentDocumentRetriever에 지정한다.
# create text splitter
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
child_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=400,
chunk_overlap=20,
length_function=len,
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectordb,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(docs, ids=None)
이렇게 문서를 저장한 후에, 아래 코드를 이용하여 검색을 한 결과를 보면, 검색된 문서의 길이가 2000자 내외로, 전체 문서가 아니라 2000자 내외로 나눠진 Large Chunk가 리턴되었음을 확인할 수 있다. J
retrieved_docs = retriever.get_relevant_documents("query")
print(len(retrieved_docs[0].page_content))
1915
'빅데이타 & 머신러닝 > 생성형 AI (ChatGPT etc)' 카테고리의 다른 글
| Langchain을 이용한 LLM 애플리케이션의 구현 #14 - Chain을 이용한 워크 플로우 구현 #2 (0) | 2024.01.25 |
|---|---|
| Langchain을 이용한 LLM 애플리케이션 개발 #13 - Chain을 이용한 워크 플로우 구현 #1 (0) | 2024.01.24 |
| Langchain Vector Store Record Delete (0) | 2024.01.13 |
| Langchain을 이용한 LLM 애플리케이션 개발 #11 - 벡터DB 검색 내용을 요약하기 (0) | 2024.01.12 |
| Langchain을 이용한 LLM 애플리케이션 개발 #10- 벡터 DB 검색하기 (0) | 2024.01.11 |