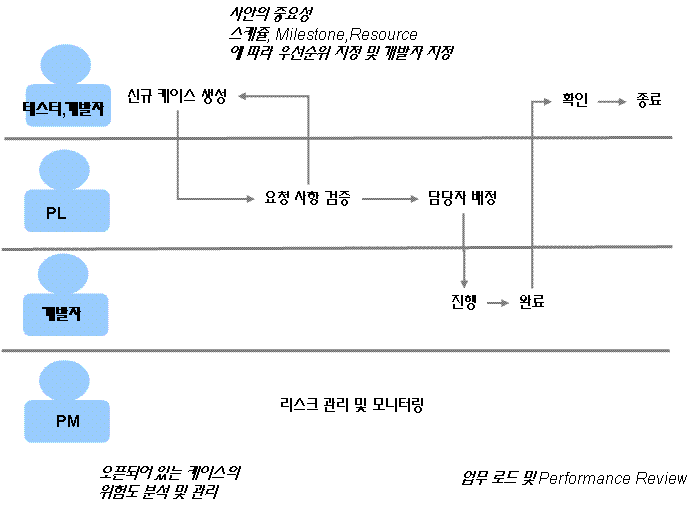
쿠버네티스 패키지 매니저 Helm #2-3. Charts (디렉토리 구조)조대협 (http://bcho.tistory.com)디렉토리 구조Helm 차트의 디렉토리 구조는 다음과 같다. 직접 아래와 같은 디렉토리 구조에 파일을 각각 생성해도 되지만, 기본 템플릿을 helm create [차트명] 으로 생성할 수 있다.아래는 %helm create mychart 명령으로 생성한 디렉토리의 구조이다. mychart/ Chart.yaml # A YAML file containing information about the chart LICENSE # OPTIONAL: A plain text file containing the license for the chart README.md # OPTIONAL: A hum..