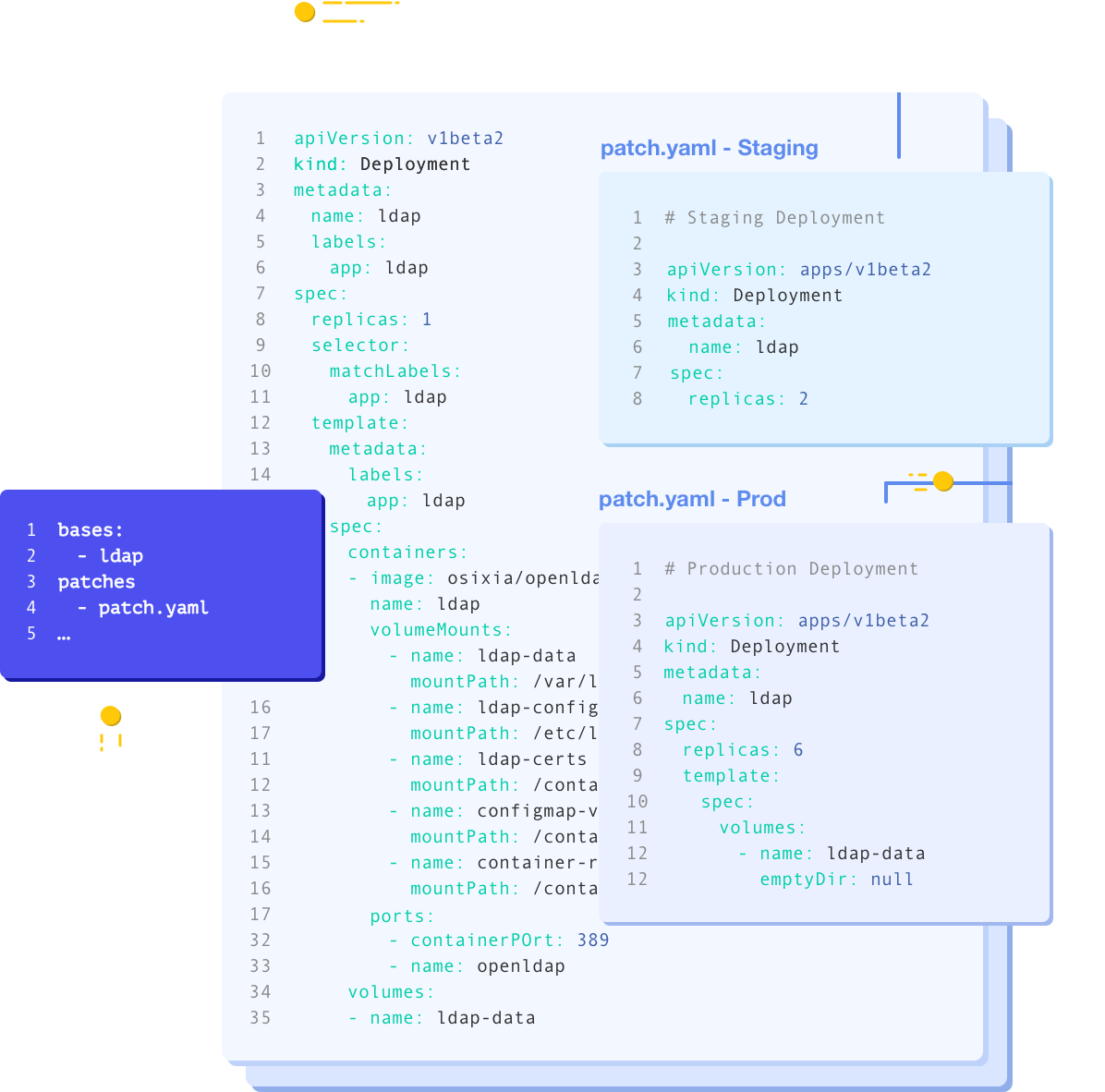
쿠버네티스 Config 변경을 위한 Kustomize 조대협 (http://bcho.tistory.com) 쿠버네티스 환경을 운영하면, 같은 설정을 다른 클러스터에 배포해야 하는 시나리오가 있다. 예를 들어서 애플리케이션을 개발/테스트/운영 (dev/stage/production)환경에 배포해야 하는데, 이 경우에 세부 설정이 조금씩 다를 수 있다. 이때 각 환경별로 파일을 만들면 관리가 어렵고 비효율적이기 때문에, 다른 세부 설정만 이러한 문제를 해결하기 위한 도구들이 Kubernetes 배포 도구이다. 대표적인 도구로 Kustomize, Helm, Ksonnet 예를 들어 아래 그림과 같이 deployment를 정의한 YAML 파일이 있을때 전체 설정을 수정하지 않고 replica 수만 개발/테스트/..