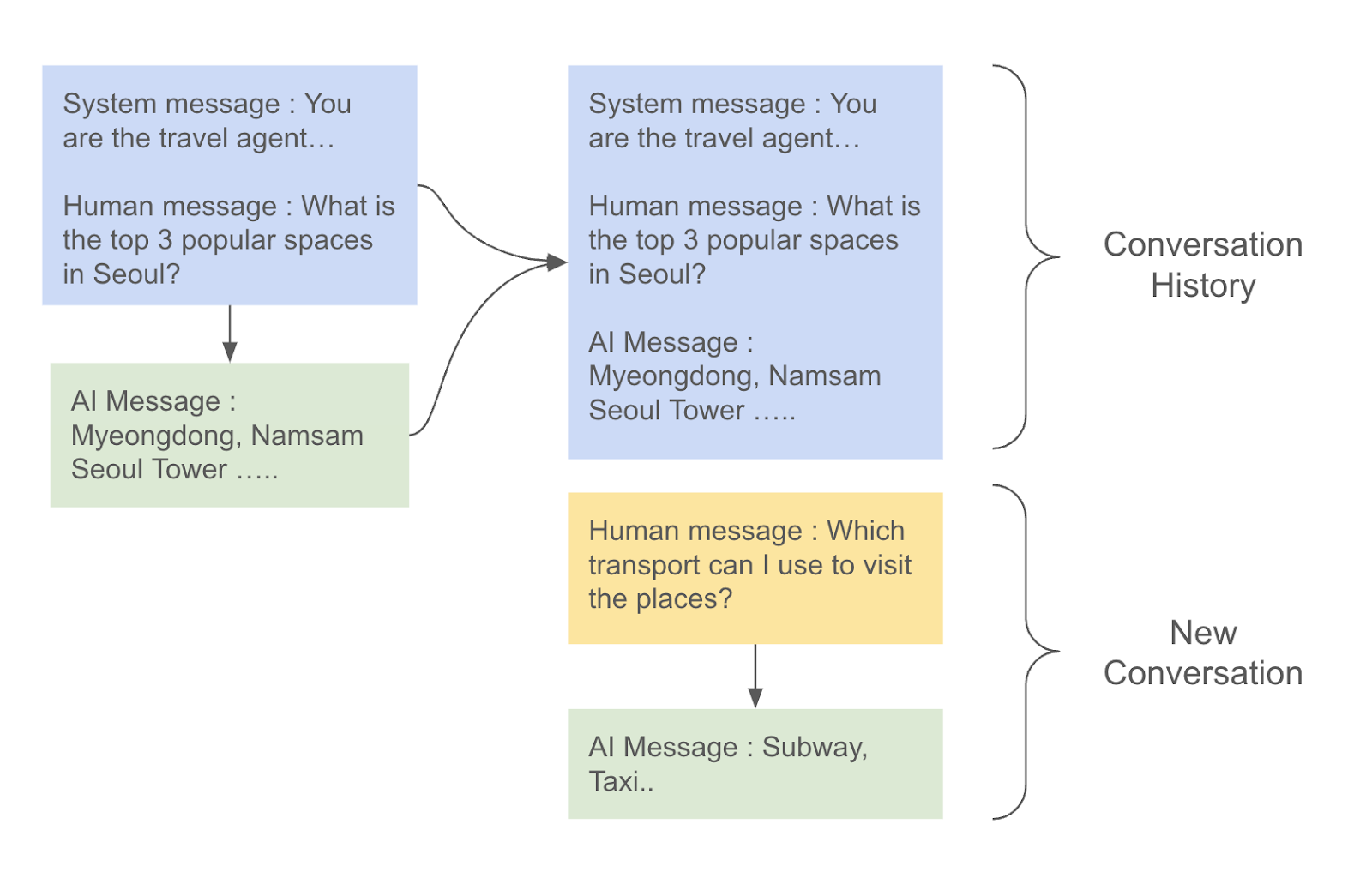
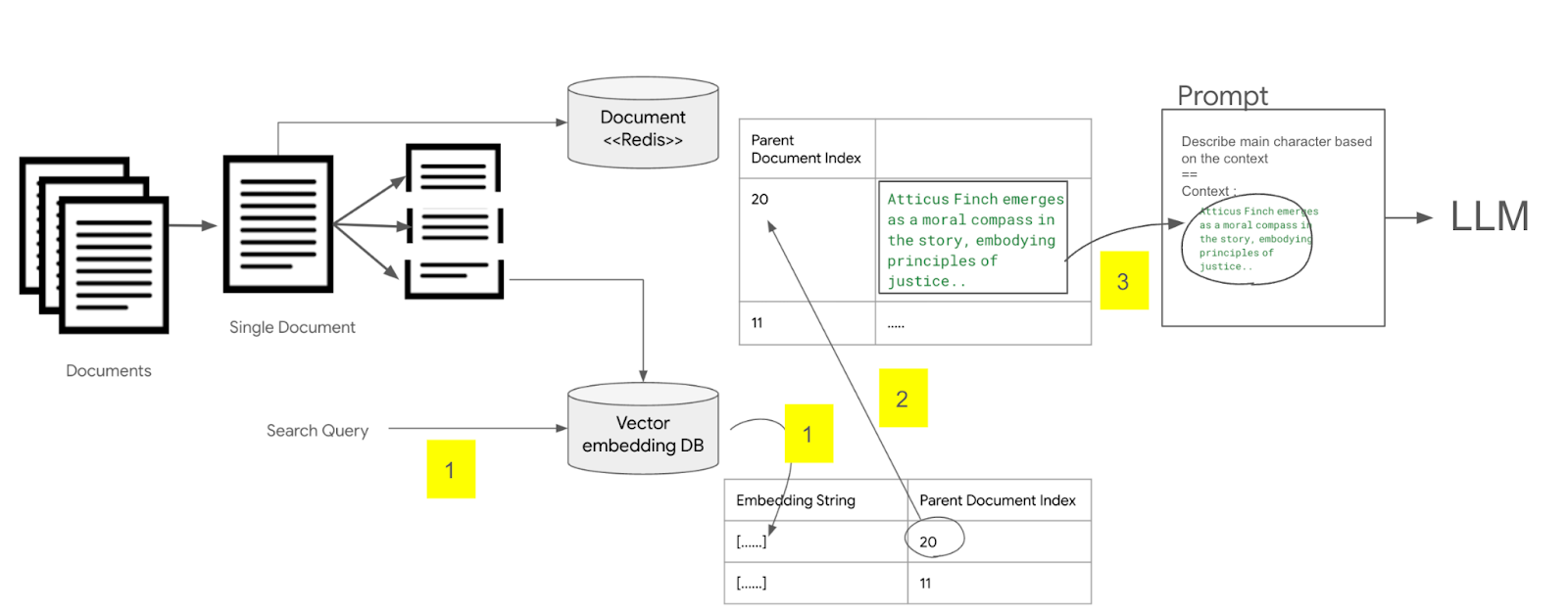
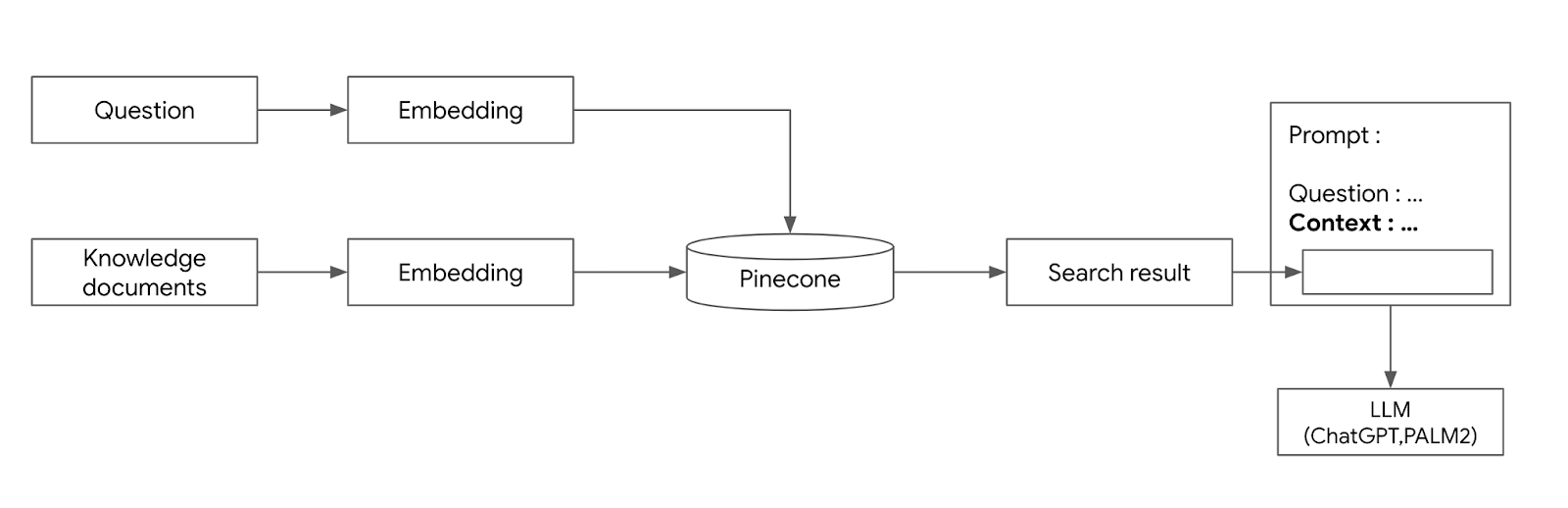
프롬프트 예제 선택기를 이용한 동적으로 프롬프트 삽입하기 조대협 (http://bcho.tistory.com) 프롬프트를 통한 정확도를 높이기 위한 기법인 프롬프트 튜닝에서 가장 큰 효과를 볼 수 있는 방식이 프롬프트에 질문과 답변에 대한 예제를 추가하는 방법이다. 이렇게 질문과 답변 예제를 추가 하는 방식을 N-Shot 프롬프팅이라고 한다. 예제가 없는 경우 Zero-Shot 프롬프팅, 2개의 예제가 있는 경우 2-Shot 프롬프팅이라고 한다. 보통 2~3개의 예제만 있어도 답변을 정확도를 크게 높일 수 있다. 프롬프트에 예제를 정적으로 미리 추가해놓을 수 도 있지만 질문의 내용이나 종류에 따라서 동적으로 질문에 대한 예시를 선택하여 프롬프트에 삽입하면 좀 더 좋은 결과를 얻을 수 있다. 특히 챗봇처럼..