Apache Spark의 개념 이해
#1 기본 동작 원리 및 아키텍처
조대협 (http://bcho.tistory.com)
아파치 스파크는 빅데이터 분석 프레임웍으로, 하둡의 단점을 보완하기 위해서 탄생하였다. 하둡을 대체하기 보다는 하둡 생태계를 보완하는 기술로 보면 되는데 실제로 기동할때 하둡의 기능들을 사용하게 된다.
하둡이 맵리듀스 방식으로 디스크(HDFS)에 저장된 파일 데이터를 기반으로 배치 분석을 진행한다면, 스파크는 디스크나 기타 다른 저장소(데이터 베이스등)에 저장된 데이터를 메모리로 올려서 분석하는 방식으로 배치 분석 뿐만 아니라, 스트리밍 데이터 양쪽 분석을 모두 지원한다.
기본 동작 원리 및 아키텍쳐
기본적인 동작 원리를 살펴 보면 다음과 같다.
스파크 클러스터의 구조는 크게 Master node 와 worker 노드로 구성된다. Master node는 전체 클러스터를 관리하고 분석 프로그램을 수행하는 역할을 한다. (사용자가 만든 분석 프로그램을 Driver Program 이라고 한다.) 이 분석 프로그램을 스파크 클러스터에 실행하게 되면 하나의 JOB이 생성된다. J
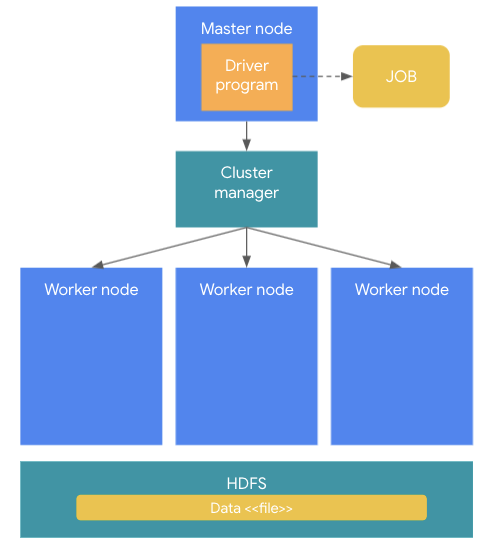
이렇게 생성된 JOB이 외부 저장소 (HDFS와 같은 파일 시스템이나 외부 데이터 베이스)로 부터 데이터를 로딩하는 경우, 이 데이터는 스파크 클러스터 Worker node로 로딩이 되는데, 로딩된 데이터는 여러 서버의 메모리에 분산되어 로딩이 된다. 이렇게 스파크 메모리에 저장된 데이터 객체를 RDD라고 한다.

이렇게 로딩된 데이터는 애플리케이션 로직에 의해서 처리되는데, 하나의 JOB이 여러 worker node에 분산된 데이터를 이용해서 분산되어 실행되기 때문에, 하나의 JOB은 여러개의 Task로 분리되어 실행이 된다. 이렇게 나눠진 Task를 실행하는 것을 Executor 라고 한다.
클러스터 매니저(Cluster Manager)
스파크는 데이터를 분산 처리하기 위해서 하나의 클러스터 내에 여러대의 머신, 즉 워커(Worker)들로 구성된다. 하나의 JOB이 여러대의 워커에 분산되서 처리되기 위해서는 하나의 JOB을 여러개의 TASK로 나눈 후에, 적절하게 이 TASK들을 여러 서버에 분산해서 배치 해야 한다. 또한 클러스터내의 워크 들도 관리를 해줘야 하는데, 이렇게 클러스터내의 워커 리소스를 관리하고 TASK를 배치 하는 역할을 하는 것이 클러스터 매니저이다.
워크들을 관리할 수 있는 클러스터 매니저는 일종의 스파크 런타임이라고 생각하면 되는데, 아래 그림과 같이 Standalone , Yarn, SIMR 등의 타입이 있다.

Standalone은 하나의 머신 내에서 스파크를 운영하는 방식으로 로컬 개발 환경등에 적합한다. 다른 방식으로는 하둡 2.X의 리소스 매니저인 YARN을 사용하여, YARN으로 하여금 클러스터내에 TASK를 배치하도록 하는 방법이 있고, 하둡 1.X 이하를 사용할 경우 하둡의 맵리듀스안에 맵 작업으로 스파크 TASK를 맵핑하는 Spark In MR (SIMR)방식이 있다.
하둡 에코 시스템 외에도 다른 클러스터 매니저를 사용할 수 있는데, 대표적으로 Apache Mesos나, Kubernetes등을 클러스터 매니저로 사용이 가능하다.
스토리지
스파크는 메모리 베이스로 데이터를 처리하지만 외부 스토리지는 포함하고 있지 않기 때문에 별도의 외부 스토리지를 사용해야 한다. 가장 대표적으로 사용되는것이 하둡의 HDFS 분산 파일 시스템이고, 클라우드의 경우 AWS S3나 Google Cloud의 Google Cloud Storage(GCS)등을 사용한다.
데이터 베이스로는 분산 노드에서 데이터를 동시에 읽어드려야 하기 때문에, 분산 처리를 잘 지원할 수 있는 NoSQL인 HBase등이 널리 사용된다. 그외에도 목적에 따라서 Solr, Kudu 등의 데이터 스토어를 사용한다.
파일 포맷
만약에 스파크 데이터를 파일로 저장할 경우 여러가지 파일 포맷을 사용할 수 있는데, 대표적으로 사용되는 파일 포맷들은 다음과 같다.
- CSV,JSON : 우리가 일반적으로 사용하는 TEXT기반의 파일 포맷으로, 사람이 읽을 수 는 있지만 압축이 되지 않았기 때문에 용량이 크다
- Parquet (Columna) : 스파크와 함께 가장 널리함께 사용되는 파일 포맷으로 바이너리 포맷을 사용한다. 특히 데이터 뿐만 아니라 컬럼명, 데이터 타입, 기본적인 통계 데이타등의 메터 데이터를 포함한다.
CSV,JSON과는 다르게 기본적인 압축 알고리즘을 사용하고 특히 snappy와 같은 압축 방식을 사용했을때, 원본 데이터 대비 최대 75% 까지 압축이 가능하다.
Parquet 포맷의 특징은 WORM (Write Once Read Many)라는 특성을 가지고 있는데, 쓰는 속도는 느리지만, 읽는 속도가 빠르다는 장점이 있다. 그리고 컬럼 베이스의 스토리지로 컬럼 단위로 저장을 하기 때문에, 전체테이블에서 특정 컬럼 만 쿼리하는데 있어서 빠른 성능을 낼 수 있다.

만약 ROW에서 전체 컬럼을 리턴해야 하는 시나리오의 경우에는 Avro가 더 유리하다.
- Avro (Row) : Avro는 Paquet 과 더불어 스파크와 함께 널리 사용되는 바이너리 데이터 포맷으로 Parquet이 컬럼 베이스라면, Avro는 로우 베이스로 데이터를 저장한다. Avro는 바이너리로 데이터를 저장하고 스키마는 JSON 파일에 별도로 저장한다. 그래서 사용자가 바이너리 파일을 이해할 필요 없이 JSON 만으로도 전체적인 데이터 포맷에 대한 이해가 가능하다.
'클라우드 컴퓨팅 & NoSQL > Hadoop' 카테고리의 다른 글
| 클라우드에 최적화된 하둡 배포 아키텍쳐 생각하기 (0) | 2017.03.23 |
|---|---|
| Hadoop 사용 가능 시나리오 (0) | 2012.06.07 |
| 분산처리 프레임웍 Apache Hadoop 아키텍쳐 소개 - #1/2 (HDFS) (3) | 2012.06.07 |