머신러닝 모델 학습에서 일어나는 오버피팅 문제를 해결하기 위한 방법으로 여러가지 방안이 있는데, 뉴럴 네트워크에서 drop out , Early stopping (모델이 오버피팅 되기전에 학습을 멈추는 방법) 등이 있다. 여기서 살펴볼 내용은 오버피팅을 해결하기 위한 기법중의 하나인 L2 Regularization이다.
일반적으로 loss 함수는 아래 그림과 같이 (y-y':원본데이타 - 예측데이타) 의 차이를 최소화하는 값을 구하는 식으로 되어 있다.

L2 Regularazation 기법은 이 Loss 함수의 값 뿐만 아니라, 모델의 복잡도를 최소화하는 weight 값을 차는 방식으로 식을 변형한다.

모델의 복잡도에 대한 계산은 weight 값의 최소값을 구하는 방식을 사용하는데, L1 Regularzation의 경우 weight의 절대값의 최소값을 L2 Regularization에서는 weight^2값의 합에 대한 최소값을 구한다. (이 글에서는 알고리즘에 대한 대략적인 개념만을 설명하기 때문에, 상세한 수학적인 수식과 배경에 대한 설명은 생략한다. ) 즉 L2 regularization term은 아래와 같은 공식이 된다.
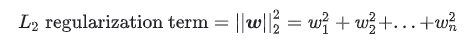
여기에 L2 regularzation의 식의 적용 강도를 조정하기 위해서 Complexity (L2 regularization term)의 값앞에 람다 값을 곱하여 식의 강도를 조정한다.
그래서 완성된 식이 다음의 형태가 된다.

L2 Regularzation을 적용하면 어떻게 모델이 변하는지를 실험해보면
아래 그림은 람다 값이 0일때이다. (L2 Regularization이 적용되지 않은 상태) 심하게 오버피팅이 발생함을 확인할 수 있다.

이 상태에서 L2 regulrization 의 람다 값을 0.03으로 적용하였을 경우 아래 그림과 같이 오버피팅이 완화 됨을 볼 수 있다
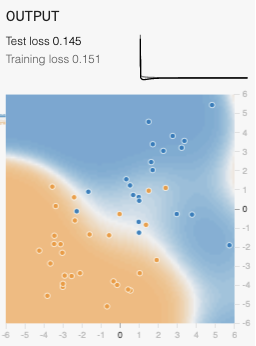
아래는 람다값을 0.3을 적용한 결과로 거의 오버피팅이 발생하지 않고 정상적인 모델이 형성 되었음을 확인할 수 있다.

이 알고리즘은 궁극적으로 Weight의 값을 조정하게 되는데,
- 예를 들어 Label과 관련이 없는 피쳐에 대한 weight 값을 0 과 가깝게 수렴하게 만들어서, 관련이 없는 피쳐가 적용되는 강도를 낮춘다.
- 만약에 두개의 피쳐의 데이터가 거의 유사할 경우 (한쪽의 피쳐에 약간의 노이즈가 있지만 거의 동일할때), 이 경우 두개의 피쳐에 대한 weight 값은 거의 동일하게 된다.
'아키텍쳐 > 머신러닝' 카테고리의 다른 글
| Feature Crossing (0) | 2021.09.29 |
|---|---|
| Vertex AI : 모델 학습 및 하이퍼 패러미터 튜닝 (0) | 2021.09.10 |
| 구글 클라우드 Vertex.AI Model 학습 및 모델 배포&서빙 (0) | 2021.09.08 |
| 피쳐 크로싱 (Feature crossing) (1) | 2019.05.21 |
| Deep learning VM (2) | 2018.12.05 |