
SRE #3-SRE의 주요 지표 SLI/SLO (Service Level Indicatior, Service Level Objectives)
SRE #3-SRE 주요 지표 (SLI/SLO)
SLI (Service Level Indicator)
SLI는 서비스에 대한 수준을 측정하여, 정량적으로 정의한 지표이다.
"REST API의 응답시간 = 300ms"와 같이 절대 값을 사용하기도 하지만, (측정값/이상적인 값)과 같은 상대적인 지표를 사용하는 것도 이해하기가 쉽다. 예를 들어 한달동안 30분 장애가 났다고 하면 장애에 대한 SLI를 30분이 아니라 가용성으로 SLI를 정의해서 (30일-30분)/(30일) * 100 = 99.9305 %와 같은 식으로 표현하는게 좋다.
SLI로 사용할 수 있는 지표는 여러가지가 있지만 일반적으로 다음과 같은 지표들을 많이 사용한다.
응답 시간 (Request latency) : 시스템의 응답시간
에러율 (Error rate%) : 전체 요청에서 실패한 요청의 비율
처리량(Throughput) : 일반적으로 초당 처리량으로 측정하고 TPS (Thoughput per second) 또는 QPS (Query per second)라는 단위를 사용한다.
가용성(availability) : 시스템의 업타임 비율로, 앞에서 예를 들어 설명하였다.
내구성(Durability-스토리지 시스템만 해당) : 스토리지 시스템에만 해당하는데, 장애에도 데이타가 유실되지 않을 확률이다.
어떤 지표를 SLI로 사용해야 하는가?
SLI로 정의할 수 있는 지표들이 많은데, 그러면 나의 서비스에서는 어떤 지표를 SLI로 정의해서 사용해야 할까? 특별히 정해진 정답은 없지만 시스템의 특성에 따라서 다음과 같이 정의한다.
사용자에게 서비스를 제공하는 서비스 시스템 (웹,모바일등) : 가용성, 응답시간, 처리량
스토리지 시스템(백업,저장 시스템): 가용성, 응답시간, 내구성
빅데이터 분석 시스템 : 처리량, 전체 End-to-End 처리 시간
머신러닝 시스템 : 서빙 응답시간, 학습 시간, 처리량, 가용성, 서빙 정확도
SLI 수집 및 표현
SLI 지표는 각종 모니터링 도구를 통해서 측정할 수 있고, 또는 로그 데이터에서 지표를 추출해 낼 수 있다. 예를 들어 정상 응답과 비정상 응답의 수를 카운트 하거나 또는 로그 메시지내에 있는 필드에서 값을 추출할 수 있다. 이렇게 추출된 값을 합하거나 평균 값을 내서 SLI를 정할 수 있는데, 평균값 보다는 값의 분포를 퍼센타일에 따른 분포를 사용하는것이 좋다. 아래 예제를 보자. 아래 예제는 웹 시스템의 응답 시간을 표현한 그래프이다.
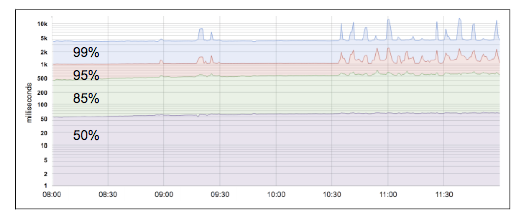
(참고 소스 : https://medium.com/@jerub/service-level-indicators-in-practice-6a1125e24bee)
50%,85%,95%,99% 응답 시간의 분포를 본것이다. 50%를 중간값이 이라고 생각하면 이 값이 일반적인 대표 값이 된다. 위의 그래프 값을 보면 20 ms 정도로 볼 수 있다. 느린 응답 시간, 즉 99%에 해당하는 응답 시간을 보면 5000ms (5초)가 나오는 것을 볼 수 있고 그래프 우측을 보면 응답 시간의 변화의 폭도 훨씬 큰것을 볼 수 있다.
실제 시스템에 문제가 되는 것은 느린값들 즉 99% 와 같은 구간에 속하는 응답시간이 문제가 되는데, 평균 값을 사용하게 되면, 느린 응답 시간이 희석화 되서 시스템의 안정성을 제대로 평가하기가 어렵다. 그래서 SRE에서는 퍼센트타일 기반의 SLI 분포도를 보고 90%,99%와 같이 문제가 되는 구간의 지표를 주요 SLI로 정해서 사용하는 것이 좋다.
SLI 지표의 표준화
SLI로 응답 시간이나 가용성 같은 지표를 사용하기로 정하면, 응답시간과 같은 SLI 지표는 여러 컴포넌트에 걸쳐서 측정해야 한다. 그런데 이러한 지표의 측정 단위가 표준화 되어 있지 않으면 혼선을 야기 하기 때문에, 표준을 정할 필요가 있다.
수집 주기 : 지표를 뽑아내는 수집 주기를 10초 단위로 한다.
수집 범위 : 수집 범위는 서비스 클러스터 단위로 한다.
지표화 주기 : 수집은 10초 단위로 했지만, 지표화는 1분 단위로 해서 시각화 한다.
어떤 호출들을 포함 할것인가? : HTTP GET 응답 시간만을 측정하고, 내부 호출은 측정하지 않는다.
어떻게 데이터를 수집할것인가? : 모니터링 시스템을 통해서 수집한다.
이러한 SLI 표준은 여러 시스템에 적용될 수 있기 때문에 재 사용을 위해서 템플릿으로 만들어서 사용하는 것도 좋다.
SLO (Service Level Objective)
앞서 SLI를 통해서 시스템의 지표를 정의하는 방법을 이야기 하였다. 그러면 각 지표에 대한 목표 값은 어떻게 정의할까? 이를 SLO (Service Level Objective)라고 한다.
SLO = SLI + 목표값(Goal)
예를 들어 REST API의 응답시간을 SLI로 정했다면, SLO는 다음과 같이 정의할 수 있다.
“매주, 99% of REST API호출의 응답 시간은 100ms 이하여야한다.”
여기서 "매주,99% REST API 호출 응답시간"이 SLI가 되고, 응답시간 100ms가 목표값이 되서 위의 전체 문장이 SLO가 된다.
What user cares?
SLO를 정의할때 잘못하면, 서비스 제공자 관점에서 생각해서 SLO를 정의하기 쉬운데, SLO는 사용자 관점에서 서비스에 얼마나 영향을 주는 가의 관점에서 결정해야 한다.
시스템 관점에서 API 호출 응답시간이 80% 퍼센타일 구간에서 1초면 꽤 높은 것으로 느껴질 수 있지만, 모바일 서비스를 가정한다면, 모바일 서비스의 경우 지하철이나 차량 이동등으로 인해서, 모바일 네트워크 통신 속도 자체가 느리기 때문에, 80% 퍼센타일 구간에서 1초의 지연이면 사용자에게 체감되는 속도는 그렇게 느린편은 아니다. 이를 무리하게 맞추기 위해서 API호출 응답시간을 1초 이하로 내리는 행위는 적절하지 않다. (오버엔지니어링의 사례로 그 시간에 자동화나 다른 개발을 하는데 시간을 투자하는 것이 났다.)
또는 모바일 앱의 경우 통신망의 가용성이 99.99% 인데, 시스템의 가용성을 99.999%로 만든다 하더라도 통신망에서 더 많은 에러가 나기 때문에 쓸모 없는 SLO가 된다.
물론 많은 경우 사용자가 어떤 지표에 대해서 얼마 만큼의 기대값을 가지는지 알기 어려운 경우가 많다. 이런 경우에는 사용자의 기대치에 대해서 가설을 세워서 시작하고 측정하기 쉬운 항목부터 측정해가면서 나중에 실제로 유용한 SLO로 발전 시켜가는 접근 방법을 사용하도록 한다.
SLO는 반드시 사용자 관점에서 정의해야한다. SLO 관점에서 시스템에 문제가 없다 하더라도, Customer Support Team으로, 불만(성능/안정성)이 들어온다면, SLO 설정을 잘못했을 가능성에 대해서도 생각해봐야 한다. 이런 지표를 효과적으로 수집하기 위해서 Customer Support 항목에 성능/안정성 등에 대한 항목을 넣고 이를 모니터링 하는 것도 좋은 방법중의 하나이다.
좋은 SLO 란?
그러면 좋은 SLO의 정의란 무엇인가? SLO에서 설정하는 목표는 단순히 기술적인 목표가 아니라 그 비지니스가 추구하고자 하는 가치를 반영한 목표여야 한다. 그러면 좋은 SLO를 만들기 위한 조건을 보자
단순할것
좋은 SLO를 복잡하지 않고 단순해서 이해하기 쉬워야한다. SLO는 개발/운영 조직뿐만 아니라 영업 조직 및 고위 임원까지 모두 동의하고 사용하는 지표이기 때문에, 어려운 정의는 서로 이해하기가 어렵다.완벽한 값을 사용하지 말것
완벽한 시스템을 존재할 수 없고 현실성이 없다. 예를 들어 100% 업타임인 무장애 시스템은 존재하지 않는다. 상식적으로 타당한 선에서 SLO를 정의하자되도록이면 적은 수의 SLO만 정의할것
보통 시스템에는 하나의 SLO만을 사용하지 않는다. 여러개의 SLO 값을 지정해서 사용하는데, 많은 수의 SLO는 관리가 어렵고 실제로 제대로 사용되지도 않는다. 적은 수의 SLO를 사용하되, 사용되는 SLO는 비지니스 의사결정의 기준으로 사용될 수 있는 SLO만 사용하도록 한다. 의사결정에 사용되지 않는 SLO는 쓸모가 없는 SLO이다.지속적이고 점진적으로 SLO값을 발전 시킬것
SLO의 값은 조직의 능력이나 비지니스의 상황에 따라서 지속적으로 조정해야 한다. SLO를 낮은 값에서 시작해서 점점 높은 수준의 값으로 발전 시키는 방법이 있고, 그 반대 방향도 있다.
만약에 높은 값의 SLO를 목표값으로 시작했다가 개발/운영 조직이 이 목표를 맞추지 못했으니 SLO를 낮추자는 접근 방법은 그다지 좋지 못하다. SLO를 맞추지 못했을때 SLO를 계속해서 낮춰가는 나쁜 습관을 만들 수 있기 때문에 습관적으로 SLO 목표값을 점점 낮추게 되는 나쁜 결과를 나을 수 있다.
그래서 SLO의 목표값은 낮은 값에서 시작해서 점차적으로 높은 값으로 바꿔 나가는 것이 바람직하다.
SLO에 대한 기대치 관리
SLO는 의사 결정의 기준이 되는 지표로 사용되기 때문에, SLO를 잘 이해하고 활용하는 것이 중요한데, 그중에서도 SLO에 관련된 이해 당사자들의 SLO에 대한 기대치를 잘 관리하는 것이 중요하다. 엄격하게 지켜야할 SLO이기는 하지만 너무 타이트하게 SLO를 잡으면, 반대로 다른 부작용이 발생할 수 있다.
SLO의 최소/최대 범위 지정
일반적으로 SLO는 "SLO<=목표값" 식으로 최대값만 설정하거나 또는 "최소값 <==SLO ⇐ 목표값" 형태로 설정을 한다." REST API 의 응답시간 ⇐ 300ms” 는 SLO로 크게 이상하지 않지만 “100ms <= REST API 응답시간 <==300ms”라고 정하는 것과 같이 최소값을 정하는 이유는 무엇일까?
100ms 이상의 지연을 허용한다는 점을 명시적으로 SLO에 적어놓게 되면, 개발자에게는 성능 향상의 목표가 생긴다. 300ms 이하를 유지 하면 되지만, 경우에 따라서 과하게 성능을 끌어 올리려고 몰두 하는 바람에, 정작 개발해야 하는 기능 개발을 하지 못할 수 있기 때문에, 오버 엔지니어링을 막는 차원에 SLO의 최소/최대 범위를 정하는 것도 좋은 방법이라고 할 수 있다.
여유 값을 둘것
SLO를 정의할때, SLO를 외부에 공유해야 하는 경우 (예를 들어, 클라우드 서비스와 같은 경우) 외부에 공유하는 SLO와 내부에서 사용하는 SLO 둘을 나눠서 관리하고 내부용 SLO에 여유치를 둬서 외부용 SLO를 정의하면, 문제 발생시 어느정도의 여유 폭을 가질 수 있다.
물론 외부용 SLO가 사용자의 기대치에 미치지 못하는 수준이면 안되지만, 사용자가 인정할 수 있는 범위라면 어느정도의 여유 폭을 두는게 좋다.
Don’t overachieve
만약에 서비스에서 제공되는 성능이나 가용성이 SLO에 정의된 것보다 높다면 사용자는 당연히 현재의 성능에 익숙해진다. 예를 들어 시스템의 REST API 응답시간을 500ms 로 정해놨는데, 실제 시스템의 응답시간이 300ms 라면, 사용자는 이 300ms 응답시간에 익숙해질 것이고, 오히려 500ms 의 정상적인 응답시간이 나오면 느려진다고 느낄 수 있다.
앞에 언급했던 SLO의 최소/최대 범위를 정하는 것도 이런 이유 중의 하나이다.
지금까지 SLO에 대해서 살펴보았다. SLO는 의사결정과 일의 우선 순위를 정하기 위한 매우 중요한 지표이다. 만약에 SLO가 의사 결정이나 우선 순위 결정에 사용되지 않는다면, 그 SLO와 넓게는 SRE 자체가 잘못된 것이다. SLO 는 SRE에서 그만큼 중요한 지표이기 때문에, 정의할 때 신중해야 하는데, SLO를 지정할때 너무 높은 수준의 SLO를 정하게 되면 SLO 수준에 맞는 성능과 안정성을 위해서 개발 자원을 투자해야 하고 그로 인해서 새로운 기능 개발이 늦어진다. 반대로 너무 낮은 수준의 SLO를 정하게 되면, 서비스 자체의 품질을 떨어 뜨린다.
앞에서도 계속 설명했듯이 SLO는 SRE에서 비즈니스 의사 결정과, 개발의 우선 순위를 결정하는등 아주 큰 의미를 가지는 중요한 지표이기 때문에, 현명하게 사용해야 한다.