LLM 애플리케이션 아키텍처 (1/2)
LLM 애플리케이션 아키텍처 (1/2)
조대협 (http://bcho.tistory.com)
ChatGPT나, Gemini 모델과 같은 LLM 을 이용한 애플리케이션을 개발하는 형태를 보면, 보통 LLM에 프롬프트 엔지니어링을 사용한 프롬프트를 입력으로 사용하고, 리턴을 받아서 사용한다. 그리고 약간 발전된 형태의 경우에는 파인 튜닝을 사용하거나, 아주 발전된 형태는 외부 문서 저장소를 사용하는 형태 정도의 수준으로 개발한다.
즉 LLM을 한번 정도 호출하는 정도의 구조를 가지고 있다. 그러나 운영환경에 올라가는 LLM 기반의 애플리케이션의 구조는 이것보다 훨씬 복잡하다. 아래 그림은 LLM 애플리케이션의 아키텍처 예시이다.
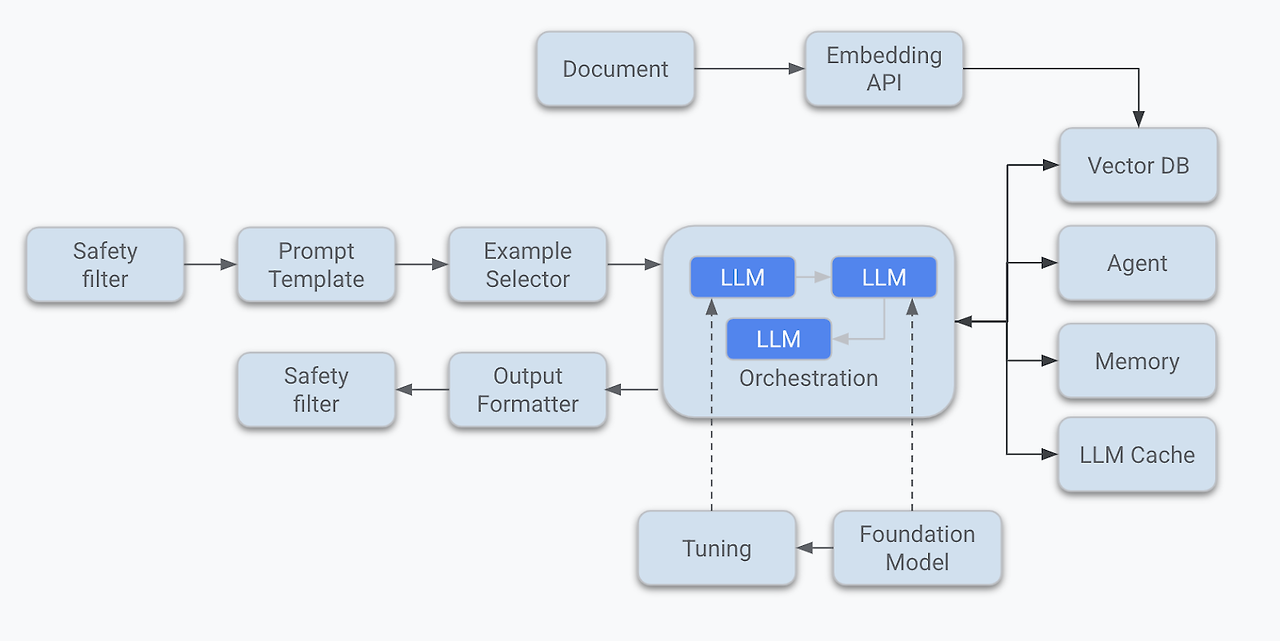
<그림. LLM 애플리케이션 아키텍처 >
단순하게 프롬프트를 작성해서 LLM을 한번만 호출하는 것이 아니라, 여러 예제를 만들어놓고 질문의 종류에 따라서 알맞은 예제를 동적으로 선택하게 한다거나, 같은 질의를 여러 다른 LLM 모델에 질의 한후, 그중에서 가장 알맞은 답변을 고르게 해서 최종 답변을 선택한다던가 또는 LLM이 학습되지 않은 데이터를 구글 검색 엔진과 같은 외부 데이터 소스에서 검색해와서 LLM이 사용하는 등의 구조로 구현이 가능하다.
이를 LLM 애플리케이션 아키텍처라고 한다.
LLM 애플리케이션을 구성하는 컴포넌트들을 보면 다음과 같다.
Safety filter
특히 쳇봇과 같은 경우 LLM으로 들어온 질의와 응답에 대해서 부적절한 내용인지를 판단을 해야하는데, 예를 들어 성적인 내용이나, 폭력적인 내용이나, 상호 비방 컨텐츠 등에 대해서는 입력 단계에서 필터링을 해야 하고, 마찬가지로 LLM의 출력에서도 이를 필터링해서 부적절한 컨텐츠가 입력되거나 서빙되는 일을 방지 해야 한다.
단순히 부적절한 콘텐츠 뿐만 아니라, 사용자의 연령대나 종교 등 특성에 따라서 입력과 출력을 조정해야 하며, 경우에 따라서는 응답 내용이 지적 재산권을 침해하는지도 체크해야 한다. 예를 들어 마케팅 문구를 만들어주는 LLM 애플리케이션의 경우에는 기존의 마케팅 슬로건들과 겹치지 않도록 하여, 지적 재산권 충돌 여부등을 방지해야 한다.
간단한 구현은 프롬프트 엔지니어링을 통해서 가이드를 할 수 있지만, 지적 재산권 검색이나 패턴등을 이용한 부적절한 컨텐츠 구축은 추후에 설명할 (RAG구조)를 이용하여, 특정 패턴들을 문서 데이터 베이스에 저장해놓고 비슷한 패턴일 경우에 필터링 하는 구조를 사용한다.
필터링에는 경우에 따라서 강도를 조정할 수 있는 기능도 가져야 하는데, 고객의 성향이나 유스케이스에 따라서 강하게 필터링을 하거나 약하게 필터링을 할 수 있도록 조정해 한다.
특히 사용자와 직접 상호 작용을 하는 쳇봇의 경우에는 이러한 세이프티 필터 기능들이 대단히 중요한데, 초보적인 많은 애플리케이션들이 이러한 기능을 생략한한체 구현되는 경우가 많다.
Prompt Template
LLM에서 프롬프트는 시나리오 따라서 재사용하는 경우가 많다. 예를 들어 여행 가이드 쳇봇의 경우 특정 여행 장소에 대해서 설명을 부탁하는 경우에,. “경복궁에 대한 여행 정보를 알려줘.”, “명동에 대한 여행 정보를 알려줘" 와 같이 장소 이름만 바꿔 주면 된다. 이렇게 프롬프트에서 변경되는 부분을 변수 처리화하여 사용하는 방법을 프롬프트 템플릿이라고 한다.
아래 그림은 프롬프트에서 형용사와 토픽, 그리고 도시이름을 변수 처리한후에, 값을 각각 “famous”, “place”,”seoul”로 입력하여 템플릿을 이용하여 프롬프트를 생성한 개념이다.

<그림 프롬프트 템플릿의 개념 >
Example Selector
LLM 프롬프트를 작성할때 질문과 답변에 대한 예제를 첨부하면 LLM의 응답 정확도를 높일 수 있다.
이를 N-Shot prompting(엔샷 프롬프팅) 이라고 하는데, 예제를 기계적으로 같은 예제를 첨부하는 것이 아니라, 질문의 종류에 따라서 최대한 좋은 답을 낼 수 있는 예제를 선택하게 할 수 도 있고, 프롬프트의 길이는 LLM의 입력 토큰 길이에 영향을 받기 때문에, 예제가 길면 요약을 하거나 중간에 잘라서 예제를 프롬프트에 포함해야 하는 경우가 있다. 이러한 문제를 해결하기 위한 것이 Example Selector인데, 질문에 따라서 적절한 프롬프트를 선택하는 기능을 할 수 있다.
예를 들어 아래과 같이 입력글을 요약하도록 하는 프롬프트 예제가 있다고 하자.
{"input":"Please summarize the weather news.\n"
,"summary":"Today's weather: Sunny skies, mild temperatures,"\
" and a gentle breeze. Enjoy the pleasant conditions throughout the day!"},
{"input":"Please summarize the economy news.\n","summary":"Global stocks rise on positive economic data;"\
"inflation concerns persist. Tech sector outperforms; central banks closely monitor."},
{"input":"Please summarize retail news.\n","summary":"Major retailer announces record-breaking sales during holiday shopping season"},
{"input":"What is stock market trend?\n","summary":"Investor optimism grows amid easing global trade tensions"},
LLM 애플리케이션에 대한 질문이 이번주의 경제 트랜드와 날씨에 대해서 알고 싶다고 하면,
I want to know the economy trends and weather this week.
Example Selector는 프롬프트 예제 중에서 경제와 날씨 요약에 대한 예제를 골라서, 프롬프트에 아래와 같이 예제로 삽입하게 된다.
Input:Please summarize the weather news.
Summary:Today's weather: Sunny skies, mild temperatures, and a gentle breeze. Enjoy the pleasant conditions throughout the day!
Input:What is stock market trend? Summary:Investor optimism grows amid easing global trade tensions
input: I want to know the economy trends and weather this week.
Summary:
<그림. 선택된 예제가 삽입되어 생성된 프롬프트 >
LLM 모델
Safety filter, Prompt Template 그리고 Example Selector 를 이용해서 프롬프트가 준비되었으면, LLM을 호출할 수 있다.
ChatGPT, 미스트랄, 제미나이, 앤트로픽의 Claude 등 다양한 모델들이 있는데, 이 모델들은 정확도나 응답 시간이 모두 다르고, 입출력 토큰의 길이나 특히 가격이 많이 다르다.
그래서 하나의 LLM만을 사용할 수 도 있겠지만 경우에 따라서는 여러개의 LLM 모델을 혼용하여 사용할 수 도 있다.
Orchestration
이러한 LLM 을 호출할때 하나의 LLM을 한번 호출 하고 끝나는 것이 아니라, LLM에서 나온 출력을 다시 LLM에 넣어서 질의할 수 도 있고, 출력 내용에 따라서, 질문을 바꿔서 다시 질문하는 라우팅등의 기법이나, 동시에 두개의 질문을 처리하는 병렬 처리등, 사실 LLM 애플리케이션을 운영환경 수준에서 구현하려면 다양한 LLM을 다양한 구조로 여러번 호출하는 워크 플로우 형태를 띄게 된다. 이렇게 복잡한 워크 플로우를 처리해주는 기능을 Orchestration이라고 한다.
아래는 설명을 돕기 위한 예제로, “대한민국에서 가장 유명한 관광지 정보”를 얻은후에, “그 관광지 근처의 유명한 레스토랑", “ 그 레스토랑의 유명한 메뉴"를 얻고, 병렬로 “그 관광지에 도착하기 위한 대중 교통 수단" 정보를 얻은 후에, 최종적으로 3개의 정보를 취합하는 워크 플로우 구조이다.
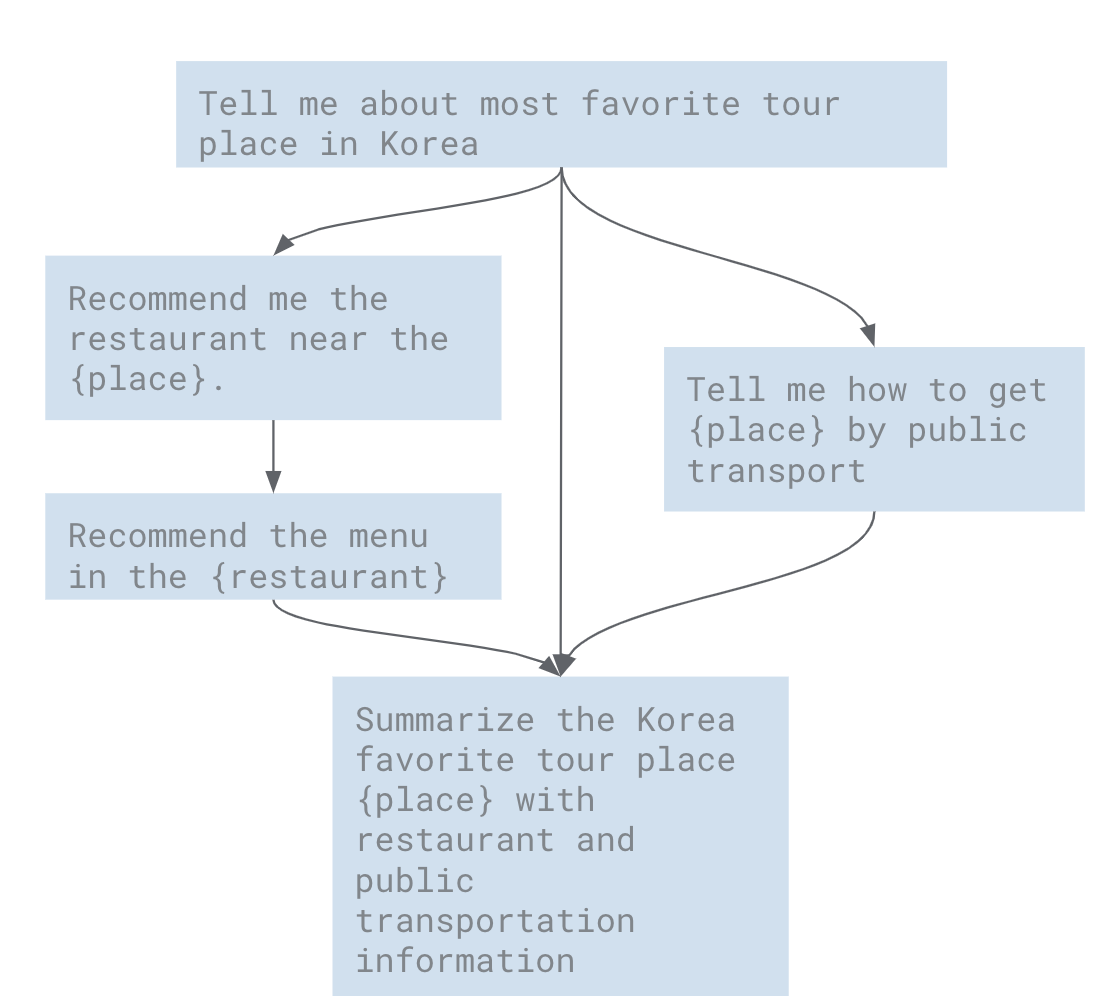
물론 하나의 프롬프트에 이 내용을 모두 질의할 수 도 있겠지만, 입출력 토큰의 크기가 한정이 되어 있기 때문에 각각 분리된 질의로 하면 상세한 질문과 상세한 답변을 얻을 수 있다.