Langchain을 이용한 LLM 애플리케이션 개발 #9 - RAG를 이용한 문서 참조. 문서 저장하기
LLM은 학습 당시의 데이터만 기억하고 있기 때문에 학습 이후에 데이터에 대한 질의에 답변할 수 없고, LLM의 고질적인 문제인 환상(Halluciation)효과를 방지하기 위해서는 Ground Truth(진실)에 해당하는 외부 문서를 참조해서 답변하도록 하는것이 좋다. 이러한 구조를 RAG (Retrieval Agumentated Generation) 이라고 하는데, 이번글에서는 Langchain을 이용하여 RAG를 구현하는 방법에 대해서 알아보자.
이 구조를 이해하기 위해서는 벡터 임베딩, 유사도 검색, 벡터데이터 베이스에 대한 선수 지식이 필요한데, 아래 글을 참고하기 바란다.
2. 임베딩과 유사도 검색
4. 텍스트 임베딩하기
5. chatgpt에서 pinecone 에 저장된 문서 기반으로 답변하기
이제 임베딩의 개념과 API의 사용법 그리고 벡터데이터 베이스에 대해서 이해하였으면, RAG 아키텍처를 구현해보자. 먼저 텍스트를 임베딩해서 pinecone에 메타 정보와 함께 저장하겠다.
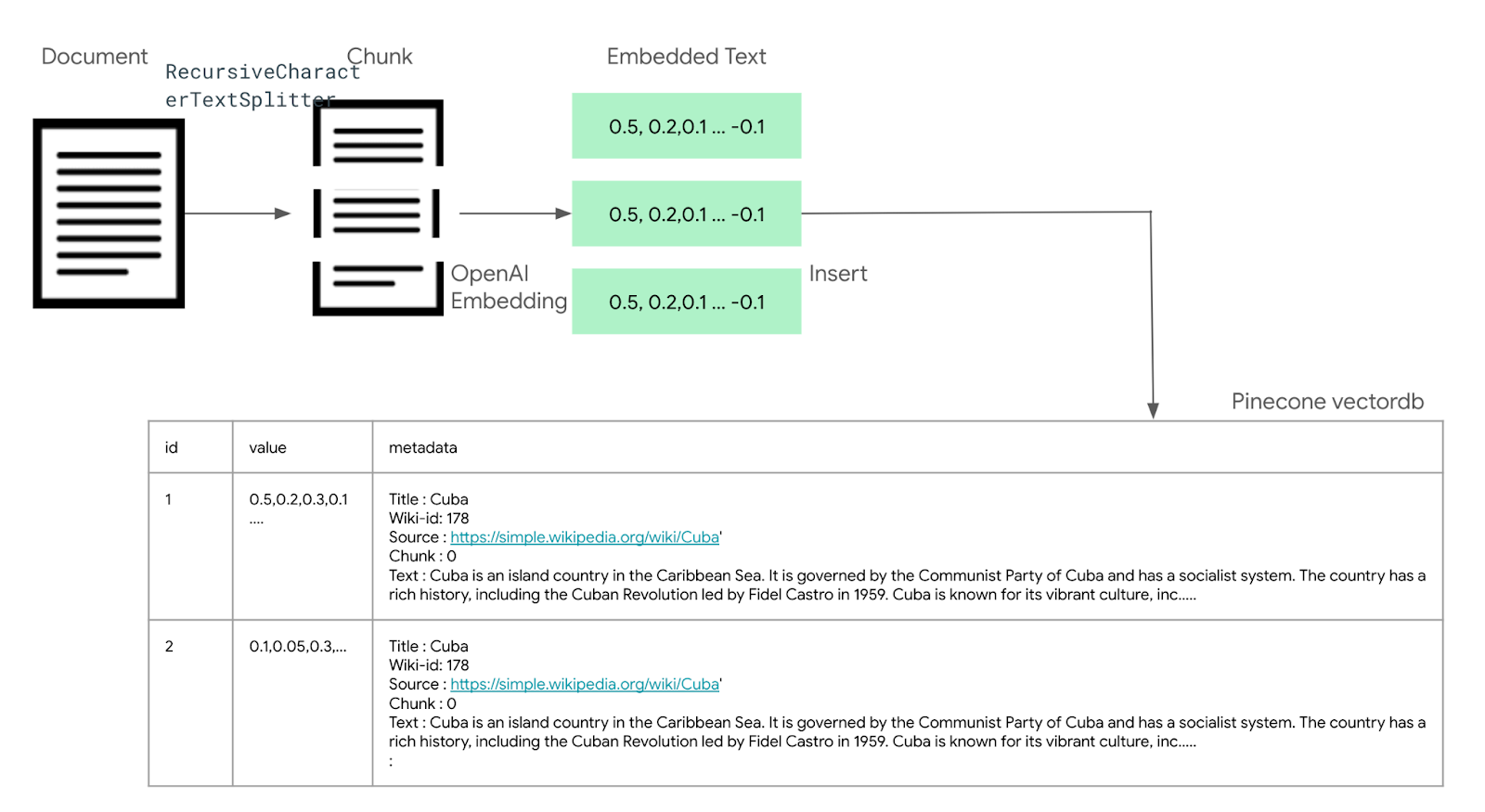
예제는 위키피디아 문서 중 100개의 초반 문서를 로딩한 후에, 각 문서를 Recursive CharacterTextSpilitter를 이용하여 400 자 단위로 분할 한 후, 분할된 Chunk를 OpenAI Embedding 모델을 이용하여, 임베딩한 후에, pinecone에 저장하는 예제이다.
pinecone에 저장되는 스키마의 형태는 다음과 같다.
| id | Values | metadata |
| 저장된 Embedding의 unique id (Primary Key) | 1536 차원으로 임베딩된 값 | chunk source text title wiki-id |
metadata는
- chunk : 하나의 문서를 여러개의 chunk로 분할하였을때, 이 임베딩이 몇번째 chunk를 임베딩한것인지에 대한 인덱스를 저장한다.
- Source : wikipedia의 정보로 wikipedia 원본 URL을 나타낸다.
- Title : wikipeida의 문서 제목
- Wiki-id : Wikipedia에서 이 문서의 ID
- Text : 이 부분이 제일 중요한데, 원본 문서 내용 전체를 저장한다. 예를 들어 Cuba에 대한 문서가 있을때, 이 문서는 여러개의 chunk로 나누어져서 임베딩 된 값이 pinecone에 저장이 되는데, 이 임베딩된 값은 벡터 값으로, 프롬프트에서 참고할 수 없다. 임베딩된 값으로 문서를 검색한 후, 그 문서를 프롬프트에 컨택스트로 삽입해서 사용해야 한다. 이를 위해서 텍스트 정보를 저장한 후 불러와야 하는데, Text 필드는 이 chunk 가 포함된 전체 문서를 저장하게 된다. 만약에 한 문서가 여러 chunk로 분리된다면, 각 chunk는 동일한 원본 문서를 중복해서 가지게 된다. (아래 그림의 개념도 참고)
먼저 pinecone.io 에서 데이터 베이스를 생성한다.아래 그림과 같이 데이터 베이스는 “terry-wiki”라는 인덱스로, 1536 차원에 Cosine 기반 검색을 하도록 설정하고 환경은 gcp-starter 환경을 사용하였다.

다음은 예제 코드이다.
from tqdm.auto import tqdm
from uuid import uuid4
from datasets import load_dataset
import pinecone
import openai
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
# Load dataset
data = load_dataset("wikipedia", "20220301.simple", split='train[:100]')
#Connect database
pinecone.init(api_key="{YOUR_PINECONE_APIKEY}", environment="gcp-starter")
#pinecone.create_index("terry-wiki",dimension=1536,metric="cosine")
index = pinecone.Index("terry-wiki")
#create embedding API
os.environ["OPENAI_API_KEY"] = "{YOUR_OPENAI_APIKEY}"
embedding = OpenAIEmbeddings()
# create text splitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=400,
chunk_overlap=20,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
# Upsert records
batch_size = 100
texts = []
metadatas = []
count = 0
for i, record in enumerate(tqdm(data)):
# first get metadata fields for this record
metadata = {
'wiki-id': str(record['id']),
'source': record['url'],
'title': record['title']
}
# create text chunk and metadata
full_text = record['text']
text_chunks = text_splitter.split_text(full_text)
for i,text in enumerate(text_chunks): # max medatada size is 40K
record = {
"chunk":i,
"text":full_text,
**metadata
}
metadatas.append(record)
texts.append(text)
count = count + 1
if count > batch_size: # flush batch insert
ids = [str(uuid4()) for _ in range(len(texts))]
embeds = embedding.embed_documents(texts)
try:
index.upsert(vectors=zip(ids,embeds,metadatas))
#flush buffers
texts = []
metadatas = []
count = 0
except Exception as e:
print(e) # ignore exception
print("retry")
time.sleep(1) # wait 1 sec for retry
코드를 하나씩 살펴보도록 하자.
먼저 테스트 데이터를 로딩한다. 테스트 데이터는 wikipedia 데이터로, 이중에 일부인 100개의 글만 로딩하였다.
# Load dataset
data = load_dataset("wikipedia", "20220301.simple", split='train[:100]')
다음으로, pinecone 데이터 베이스를 연결하고, 임베딩을 위해서 OpenAIEmbedding 객체를 생성한다.
#Connect database
pinecone.init(api_key="{YOUR_PINECONE_APIKEY}", environment="gcp-starter")
#pinecone.create_index("terry-wiki",dimension=1536,metric="cosine")
index = pinecone.Index("terry-wiki")
#create embedding API
os.environ["OPENAI_API_KEY"] = "{YOUR_OPENAI_APIKEY}"
embedding = OpenAIEmbeddings()
임베딩 전에, 위키 문서를 여러개의 chunk로 분할하기 위해서 langchain의 RecursiveCharacterTextSpiltter를 선언한다. chunk의 길이는 400자로 하고, overlap 중첩은 20글자로 한다.
# create text splitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=400,
chunk_overlap=20,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
임베딩 API, 데이터, 데이터베이스가 준비가 되었으면 각 문서별로 텍스트를 분리하여 데이터베이스에 입력할 준비를 한다.
먼저 for loop에서 각 문서를 record로 가져온 후에, metadata 필드를 채운다. Metadata 필드는 단일 문서에 대해서는 wiki-id와, source,title이 같기 때문에, 하나의 단일 레코드를 생성하여, DB의 레코드별로 채워 넣는다. 그리고 해당 문서의 전체 텍스트를 full_text에 저장해놓는다.
for i, record in enumerate(tqdm(data)):
# first get metadata fields for this record
metadata = {
'wiki-id': str(record['id']),
'source': record['url'],
'title': record['title']
}
# create text chunk and metadata
full_text = record['text']
해당 위키글을 TextSpillter를 이용하여 chunk 단위로 분할한후에, 각 chunk를 pinecone에 insert하기 위해서 record를 생성한다. 여기에는 앞서 만든 metadata를 추가하고,몇번째 chunk 인지를 나타내는 chunk 번호 필드인 chunk 를 추가하고, 그리고 text 필드에 전체 텍스트를 저장한다.
이렇게 레코드가 생성되었으면 이를 바로 pinecone에 insert하지 않고 성능향상을 위해서 여러개의 레코드를 한꺼번에 insert하기 위해서 batch 로 insert를 한다. 이를 위해서 metadatas에 생성한 metadata들을 저장해놓고 batch시에 한꺼번에 insert 할 예정이다. 그리고 아직 임베딩도 하지 않았는데, 임베딩도 batch insert시에 한꺼번에 임베딩을 수행하기 위해서 texts 버퍼에 append를 내놓는다.
text_chunks = text_splitter.split_text(full_text)
for i,text in enumerate(text_chunks): # max medatada size is 40K
record = {
"chunk":i,
"text":full_text,
**metadata
}
metadatas.append(record)
texts.append(text)
count = count + 1
Chunk 를 하나씩 처리할때 마다 count를 증가시킨후에, count가 batch 사이즈를 넘어서면 한꺼번에 아래 코드와 같이 pinecone에 insert를 한다.
이때 각 레코드의 Primary key를 지정하기 위해서 id를 uuid를 이용해서 유니크한 id들을 만들어내고, 앞서 texts 버퍼에 저장했던 텍스트 Chunk들을 embedding.embed_documents를 이용하여 한꺼번에 임베딩을 한다.
Id, metadata, embedding이 준비 되었으면 index.upsert를 이용하여 upsert로 배치 insert를 한다.
배치 사이즈는 100으로 하였는데, pinecone에서는 batch upsert에 대해서 100개의 limit을 권장하고 있다. 그리고 한번에 전송될 수 있는 upsert request size는 2MB이다. (출처 : https://docs.pinecone.io/docs/limits ) 만약 문장이 많이 길다면 100개가 아니라 숫자를 줄여야 한다.
if count > batch_size: # flush batch insert
ids = [str(uuid4()) for _ in range(len(texts))]
embeds = embedding.embed_documents(texts)
try:
index.upsert(vectors=zip(ids,embeds,metadatas))
#flush buffers
texts = []
metadatas = []
count = 0
except Exception as e:
print(e) # ignore exception
print("retry")
time.sleep(1) # wait 1 sec for retry
배치 upsert가 끝났으면 count=0으로 초기화하고 texts,metadatas 버퍼도 초기화를 한다.
위의 코드를 보면 try,except Exception으로 에러를 처리하는 구간이 있는데, pinecone 데이터베이스와 네트워크 연결이 좋지 않거나 일시적인 장애시 upsert가 안되는 경우가 종종있기 때문에 이를 위해서 1초 대기후 다시 retry하는 로직을 추가하였다.
코드를 작성한후에, 실행을 하면 아래와 같이 pinecone.io 콘솔에서 데이터가 저장된것을 확인할 수 있다.
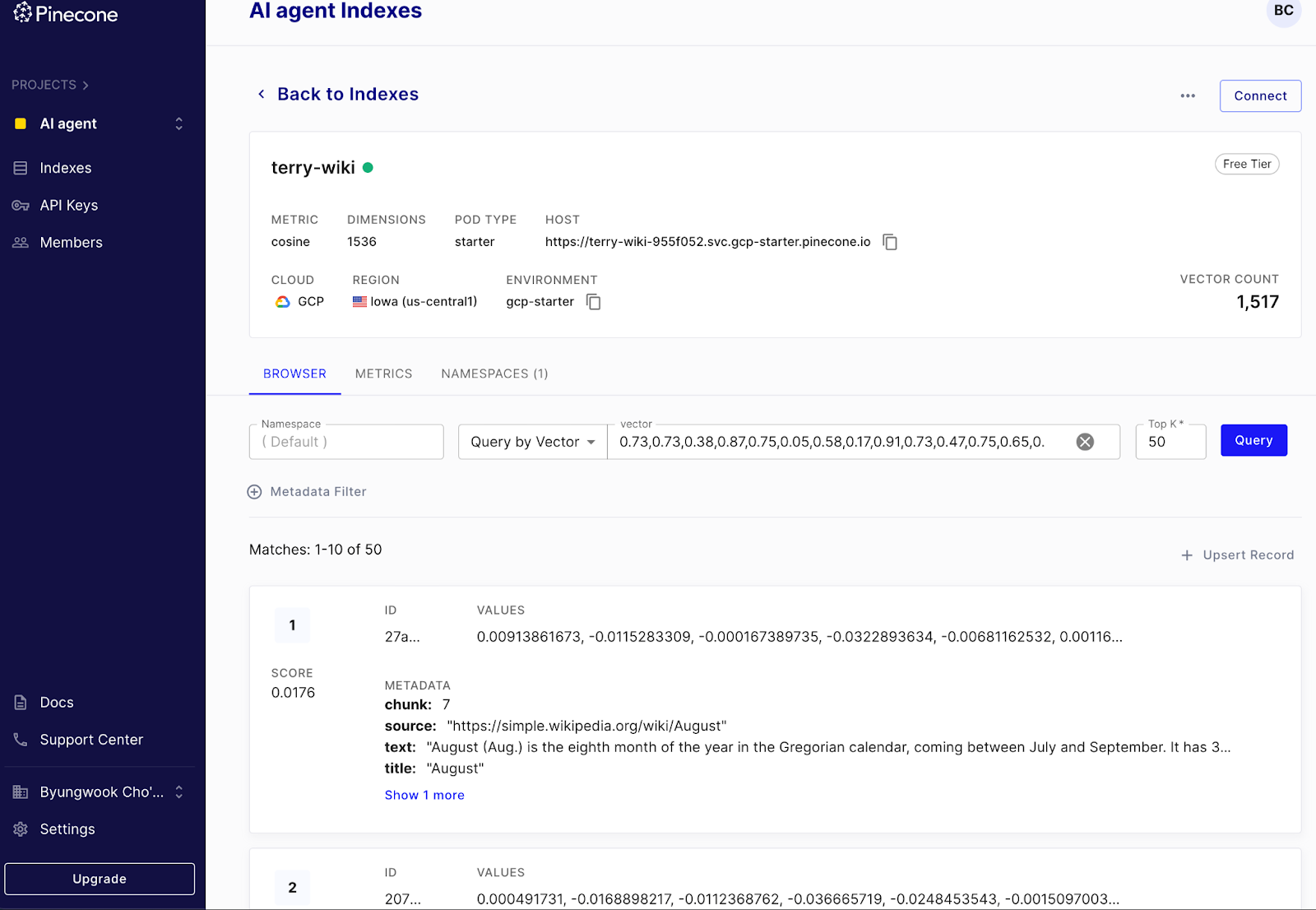
<그림. pinecone에 입력된 데이터를 조회하는 화면 >
Langchain 기반으로 구현하기 위해서 위의 코드에서는 pinecone의 metadata 컬럼에 원본 문서 전체를 text 필드에 저장하였지만 , 운영환경에서는 그다지 좋은 방법이라고 할 수 없다. 왜냐하면 하나의 문서가 50개의 chunk로 분할된다고 했을때, 이 50개의 레코드에 전체 문서가 50번 중복적으로 저장되기 때문에, 저장 용량이 늘어나고, 비용도 많이 들게 된다. 또한 Pinecone의 metadata 필드의 사이즈 제약도 있기 때문에 큰 문서는 저장이 불가능하다. 이런 문제를 보완하기 위한 기법이 여러가지가 있다.
Parent Child Chunking
문서들을 작은 Chunk 단위로 나눠서 벡터 임베딩 데이터베이스 (Vector Embedding DB)에 저장하는 과정은 같다. 이때, 필드에 임베딩과 문장의 내용을 저장하는 것이 아니라, 이 문장이 속해 있는 문서의 인덱스를 저장한다. 각 문서는 redis나 DB, 파일 시스템등에 저장해놓는다.
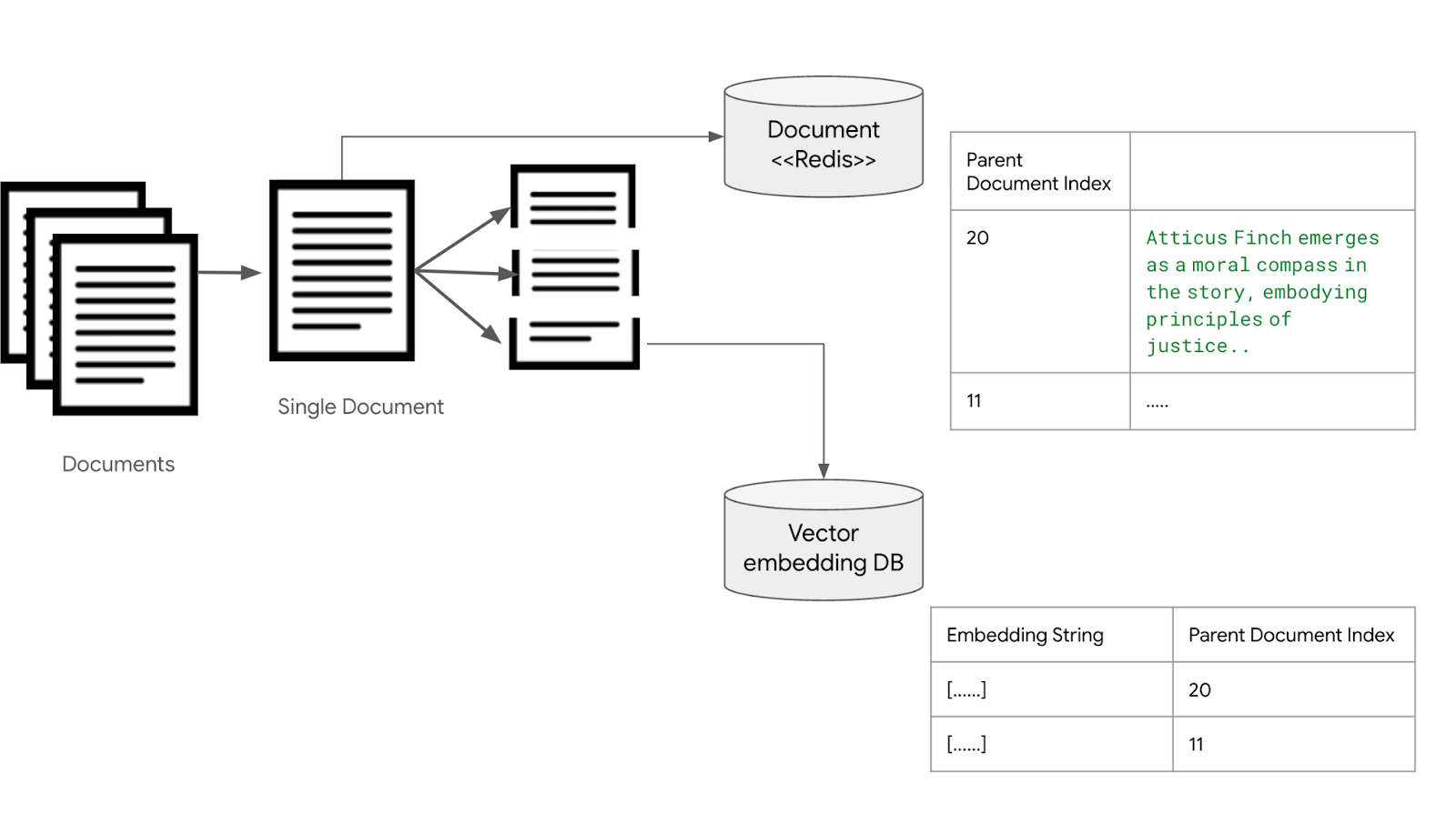
<그림. 부모/자식 검색 구조를 위해서 임베딩과 원본 문서를 분리 저장하는 구조>
다음으로 문서를 검색할때는 벡터 임베딩 데이터 베이스에서 해당 문장과 유사한 문장을 찾은 후에, 저장된 문서의 인덱스 값을 이용하여, redis에서 문서 전체를 추출한 후, 이 문서 전체 내용을 LLM 프롬프트에 컨텍스트로 사용하여 질의하는 방식이다.
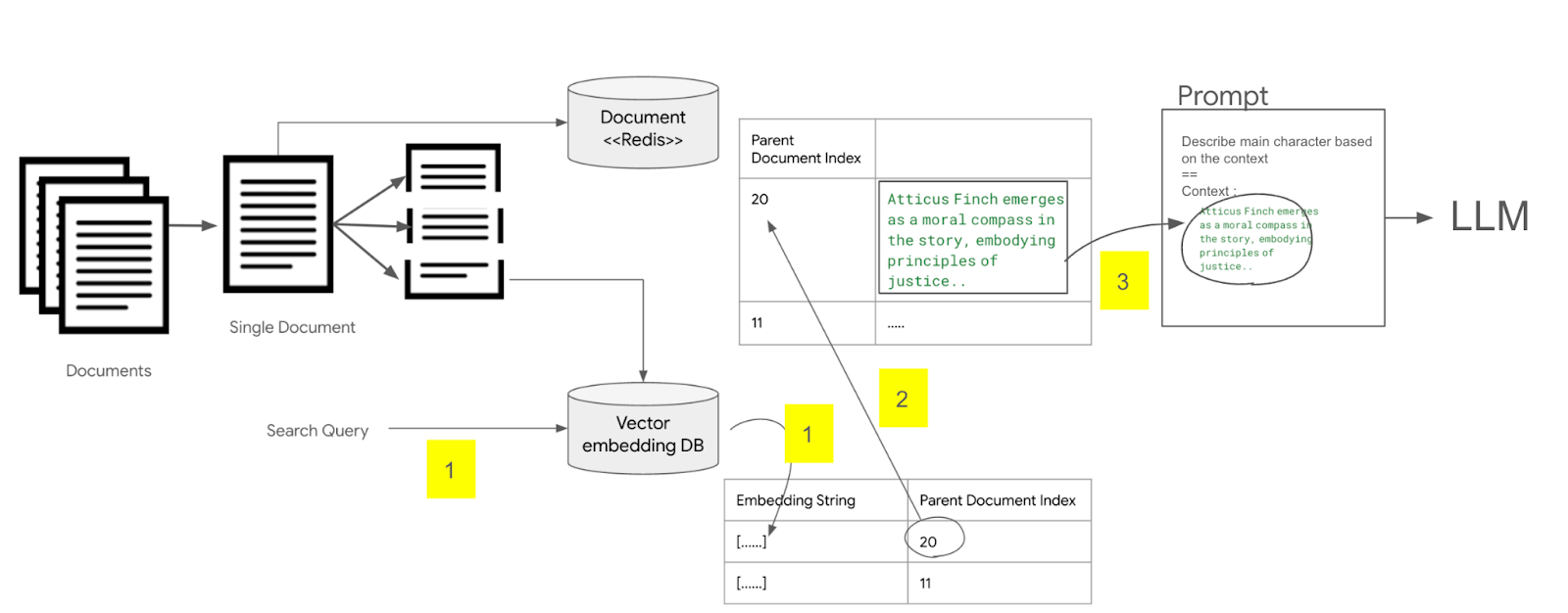
<그림. 부모 문서를 검색해서 LLM 프롬프트에 삽입하는 구조>
.
Chunk summarization
다른 방식으로는 문서를 문단 단위로 잘라낸 다음에, 일정 크기 이하로 요약하는 방법이다. 즉 Context-Aware Chunking을 이용하여, 문단을 추출한후, LLM을 통하여 OOO자 이하로 요약을 하게 한 후에, 이 요약된 문장으로 임베딩 인덱스를 만드는 방법이다.
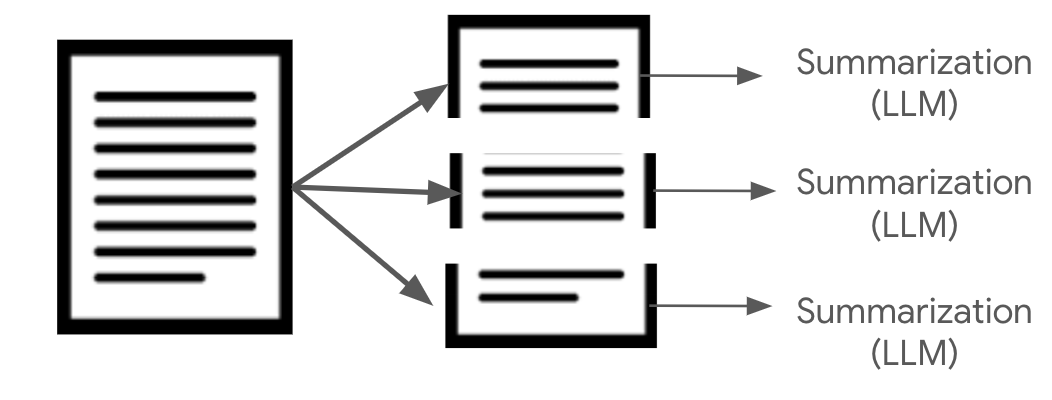
문장이 중간에 잘리지 않는 장점이 있지만 반대로 요약 과정에서 정보가 유실될 수 있는 단점이 있다.
Extract candidate question
요약과 유사하게 문서 (문장도 가능)를 LLM에 컨택스트로 제공한후, 해당 문서(또는 문장)에서 예상되는 질문 N개를 추출하도록 한후에, 이 질문으로 임베딩 인덱스를 생성하는 방법이다.
이 방법은 챗봇이나 Q&A 시스템등에 효율적으로 사용될 수 있다.