LLM 애플리케이션 개발을 위한 Langchain #5- 캐싱을 이용한 API 비용 절감
Langchain 캐싱을 이용한 비용 절감
조대협 (http://bcho.tistory.com)
LLM 애플리케이션을 개발하다보면 개발이나 테스트 단계에서 동일한 프롬프트로 반복해서 호출해야 하는 경우가 생긴다. 코딩을 하다가 에러가 나거나 아니면 테스트 결과를 보거나 할때는 동일 프롬프트로 동일 모델을 계속 호출하는데, 결과값은 거의 비슷하기 때문에, 계속해서 같은 질문을 호출하는 것은 비용이 낭비 된다. 같은 프롬프트라면 결과 값을 캐슁해놓고 개발에 사용해도 큰문제가 없다.
Langchain에서는 동일(또는 유사) 프롬프트에 대해서 결과를 캐슁하여 API 호출을 줄일 수 있는 기능을 제공한다.
메모리 캐싱
캐싱을 저장하는 장소에 따라서 여러가지 캐싱 모델을 지원하는데, 가장 간단한 캐싱 모델은 로컬 시스템의 메모리를 사용하는 방식이다. 아래 예제는 "What is famous street foods in Seoul Korea in 200 characters"
에 대한 프롬프트에 대해서 로컬 메모리에 캐싱을 하는 코드이다. 캐싱이 제대로 되었는지를 확인하기 위해서, 앞에서 배웠던 호출되는 토큰의 수를 카운트 하는 콜백을 사용하였다.
# Memory cache example
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
from langchain.globals import set_llm_cache
from langchain.cache import InMemoryCache
set_llm_cache(InMemoryCache())
llm = OpenAI(openai_api_key="{YOUR_API_KEY}")
prompt = "What is famous street foods in Seoul Korea in 200 characters"
with get_openai_callback() as callback:
response = llm.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
with get_openai_callback() as callback:
llm.invoke(prompt)
response = llm.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
아래 호출 결과를 보면 첫번째 호출은 API를 호출하였기 때문에, 토큰이 126개의 토큰을 사용한것을 확인할 수 있다. 그러나 두번째 호출은 캐싱이 되었기 때문에, 결과가 첫번째 호출과 정확하게 같고, 사용된 토큰의 수가 0개 인것을 확인할 수 있다.
1. Tteokbokki (spicy rice cakes)
2. Japchae (stir-fried glass noodles)
3. Kimbap (rice and vegetable rolls)
4. Hotteok (sweet filled pancake)
5. Odeng (fish cake on a stick)
6. Sundae (Korean blood sausage)
7. Twigim (deep-fried snacks)
8. Mandu (dumplings)
9. Eomuk (fish cake soup)
10. Gamjatang (spicy pork bone soup)
Total Tokens: 126
1. Tteokbokki (spicy rice cakes)
2. Japchae (stir-fried glass noodles)
3. Kimbap (rice and vegetable rolls)
4. Hotteok (sweet filled pancake)
5. Odeng (fish cake on a stick)
6. Sundae (Korean blood sausage)
7. Twigim (deep-fried snacks)
8. Mandu (dumplings)
9. Eomuk (fish cake soup)
10. Gamjatang (spicy pork bone soup)
Total Tokens: 0
No Cache
위의 예제는 하나의 LLM 모델을 이용하여 호출을 각각 한번씩 호출하는 시나리오지만, 하나의 애플리케이션에서 LLM을 여러 단계에 걸쳐서 호출을 하고, 경우에 따라서 특정 단계는 캐싱을 원하지 않을 수 있다.
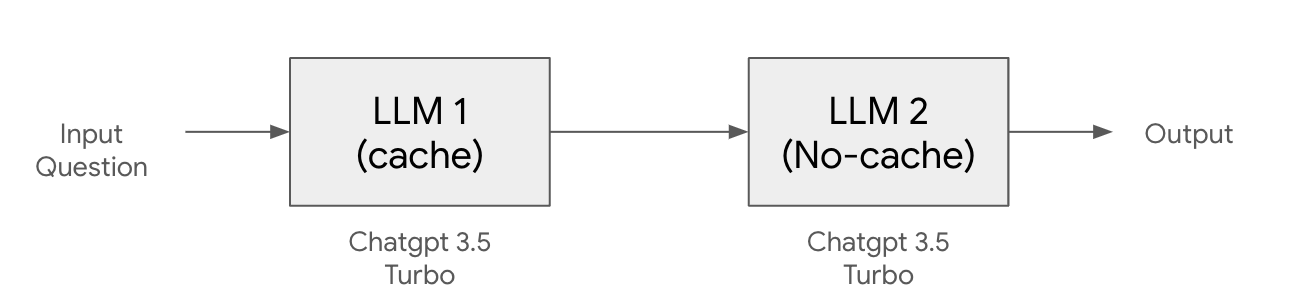
예를 들어 위의 그림은 Chatgpt 3.5 turbo 모델을 두번 순차적으로 호출하는 구조인데, 첫번 모델 호출은 캐싱을 사용하고 두번째 모델은 캐싱을 사용하고 싶지 않은 경우이다.
아래 예제를 보자.
# Memory cache example
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
from langchain.globals import set_llm_cache
from langchain.cache import InMemoryCache
from langchain.globals import set_debug
set_debug(False)
set_llm_cache(InMemoryCache())
llm1 = OpenAI(openai_api_key="{YOUR_API_KEY}")
llm2 = OpenAI(openai_api_key="{YOUR_API_KEY}",cache=False)
prompt = "Please tell me about the famous street foods in Seoul Korea in 50 characters"
with get_openai_callback() as callback:
response = llm1.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
with get_openai_callback() as callback:
llm.invoke(prompt)
response = llm2.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
위의 캐싱을 사용한 코드와 거의 유사하지만 llm2는 생성시에 “llm2 = OpenAI(openai_api_key="{YOUR_API_KEY}",cache=False)” 와 같이 “cache=False” 를 지정하여 명시적으로 캐시를 사용하지 않도록 하였다.
그래서 결과는 아래와 같이 둘다 Token 카운트가 0 이상으로 캐싱을 사용하지 않은 것을 확인할 수 있다.
Bulgogi, Kimbap, Tteokbokki, Mandu, Hotteok, Odeng, Dakkochi, Twigim, Sundae, Gimbap, Pajeon, Gyeranppang, Beondegi, Bibimbap, Jokbal, Japchae.
Total Tokens: 84
Tteokbokki, kimbap, hotteok, mandu, odeng, sundae, samgyeopsal, bingsu, gimbap, jjajangmyeon, kimchi, bibimbap, ddeokbokki, bulgogi.
Total Tokens: 78
외부 캐싱
위의 예제는 로컬 메모리를 사용하였기 때문에, 캐시에 저장되는 내용이 휘발성이다. 즉 애플리케이션을 테스트하다가 애플리케이션을 재시동 하면, 캐시의 내용이 삭제된다. 또한 여러명이 동시에 개발을 할때 캐시를 공유할 수 있다면 캐시의 히트율을 높여서 비용을 절약할 수 있다.
Langchain은 외부의 데이터베이스를 캐시 저장소로 사용할 수 있다. 로컬에서 작동하는 SqlLite에서 부터 Redis와 같은 메모리 스토어, Cassandra와 같은 NoSQL 데이터 베이스를 지원한다.
지원되는 데이터 베이스와 개발 가이드는 Langchain 문서 https://python.langchain.com/docs/integrations/llms/llm_caching 를 참고하기 바란다.
여기서는 캐시로 가장 널리 사용되는 Redis 를 캐시로 사용하는 방법을 살펴본다.
테스트를 위한 redis 인스턴스는 https://redis.com/ 에서 제공하는 무료 redis instance를 사용하였다. (30M 인스턴스까지는 무료로 사용이 가능하다.)
# Redis cache example
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
from langchain.globals import set_llm_cache
from langchain.cache import RedisCache
from redis import Redis
set_llm_cache(RedisCache(redis_=Redis(host='{YOUR_REDIS_INTANCE_ADDRESS}',
port={YOUR_REDIS_INSTANCE_PORT},
password='{YOUR_REDIS_INSTANCE_PASSWORD}')))
llm = OpenAI(openai_api_key="{YOUR_API_KEY}")
prompt = "What is famous street foods in Seoul Korea in 200 characters"
with get_openai_callback() as callback:
response = llm.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
with get_openai_callback() as callback:
llm.invoke(prompt)
response = llm.invoke(prompt)
print(response)
print("Total Tokens:",callback.total_tokens)
결과를 보면 아래와 같이 첫번째는 토큰 카운트가 243으로 실제로 chatgpt api를 호출하였고, 두번째는 0으로 캐싱된 내용을 활용한것을 확인할 수 있다.
시맨틱 캐싱 (Semantic Caching)
LLM에 대한 프롬프트 캐싱을 하는데 생각해봐야 하는 문제는 우리가 사용하는 프롬프트는 자연어 라는 사실이다. 즉 같은 의미를 갖는 질문이라도, 문자열 관점에서 봤을때는 다른 프롬프트로 인식될 수 있다. 예를 들어 “서울에서 유명한 음식 5가지?”와 “서울에서 맛볼 수 있는 유명한 음식 5가지?”는 문맥상으로는 같은 의미지만, 문자열이 다르기 때문에 캐시가 히트가 되지 않는다.
아래 예제를 보자. 아래 는 “서울에서 유명한 음식 10가지"와 “서울에서 유명한 음식 5가지"를 질의하는 예제이다.
# Redis cache example (Semantic cache test / without semantic cache)
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
from langchain.globals import set_llm_cache
from langchain.cache import RedisCache
from redis import Redis
set_llm_cache(RedisCache(redis_=Redis(host='{YOUR_REDIS_INTANCE_ADDRESS}',
port={YOUR_REDIS_INSTANCE_PORT},
password='{YOUR_REDIS_INSTANCE_PASSWORD}')))
llm = OpenAI(openai_api_key="{YOUR_API_KEY}")
prompt1 = "What is top 10 famous street foods in Seoul Korea in 200 characters"
prompt2 = "What is top 5 famous street foods in Seoul Korea in 200 characters"
with get_openai_callback() as callback:
response = llm.invoke(prompt1)
print(response)
print("Total Tokens:",callback.total_tokens)
with get_openai_callback() as callback:
llm.invoke(prompt)
response = llm.invoke(prompt2)
print(response)
print("Total Tokens:",callback.total_tokens)
결과는 아래와 같다. 당연히 프롬프트의 문자열이 다르기 때문에, 두번째 호출은 캐시를 사용하지 않는다.
1. Tteokbokki (spicy rice cakes)
2. Kimbap (rice and vegetable rolls)
3. Jokbal (braised pig's feet)
4. Hotteok (sweet pancakes)
5. Gimbap (fried seaweed rolls)
6. Sundae (blood sausage)
7. Odeng (fish cake skewers)
8. Mandu (dumplings)
9. Pajeon (scallion pancakes)
10. Eomuk (fish cake soup)
Total Tokens: 121
1. Tteokbokki – spicy rice cakes in a savory sauce
2. Kimbap – seaweed rice rolls with various fillings
3. Japchae – stir-fried glass noodles with vegetables and meat
4. Hotteok – sweet pancakes filled with brown sugar and nuts
5. Gimbap – seaweed rice rolls with a variety of ingredients such as bulgogi or vegetables.
Total Tokens: 103
유사한 질문에 대해서 캐시를 사용하게 하기 위한 기능으로 시맨틱 캐시(Semantic Cache) 라는 기능이 있다. 프롬프트 문자열을 벡터로 임베딩한후에, 문장의 유사도를 기반으로 유사한 문장의 경우 캐시된 데이터를 활용하는 방식이다. 임베딩과 임베딩된 문장에 대한 검색에 대해서는 차후에 설명한 RAG 파트를 참고하기 바란다. 여기서는 내용이 유사한 프롬프트를 캐시키로 검색한다는 개념정도만 알면된다.
아래 코드는 Redis에서 시맨틱 캐시를 사용하는 방법이다. 주의할 사항은 ChatGPT open api 키를 환경 변수 OPEN_API_KEY에 넣어야 한다. 이유는 Redis의 SementaicCache는 프롬프트를 Redis에 저장하기 위해서 프롬프트 문자열을 임베딩을 해야 하는데, 이때 OpenAIEmbedding API를 사용하는데, 이때 OPEN_API_KEY를 필요로하고 이를 환경 변수로 넘겨야 한다.
Redis Semantic Cache를 사용하는 방법은 간단하다. 앞의 예제에서 RedisCache 클래스를 아래와 같이 RedisSematicCache 클래스로 변경해주고, 임베딩 API를 추가해주면 된다.
RedisSemanticCache(redis_url="redis://default:{YOUR_REDIS_PASSWORD}@{YOUR_REDIS_INSTANCE_ADDRESS}:{YOUR_REDIS_INSTNACE_PORT}", embedding=OpenAIEmbeddings())
)
전체 예제 코드는 아래와 같다.
# Redis Semantic cache example
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
from langchain.globals import set_llm_cache
from redis import Redis
from langchain.cache import RedisSemanticCache
from langchain.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "{YOUR_API}KEY}"
llm = OpenAI()
# with Semantic Cache
set_llm_cache(
RedisSemanticCache(redis_url="redis://default:{YOUR_REDIS_PASSWORD}@{YOUR_REDIS_INSTANCE_ADDRESS}:{YOUR_REDIS_INSTNACE_PORT}", embedding=OpenAIEmbeddings())
)
prompt1 = "What is top 10 famous street foods in Seoul Korea in 200 characters"
prompt2 = "What is top 5 famous street foods in Seoul Korea in 200 characters"
with get_openai_callback() as callback:
response = llm.invoke(prompt1)
print(response)
print("Total Tokens:",callback.total_tokens)
with get_openai_callback() as callback:
llm.invoke(prompt)
response = llm.invoke(prompt2)
print(response)
print("Total Tokens:",callback.total_tokens)
결과를 보면 다음과 같다.
1. Tteokbokki - spicy rice cakes
2. Samgyeopsal - grilled pork belly
3. Kimbap - rice rolls with various fillings
4. Jajangmyeon - black bean noodles
5. Hotteok - sweet pancakes with filling
6. Mandu - dumplings
7. Gimbap - seaweed rice rolls
8. Dakkochi - grilled chicken skewers
9. Sundae - Korean blood sausage
10. Bungeoppang - fish-shaped pastry filled with red bean paste.
Total Tokens: 134
1. Tteokbokki - spicy rice cakes
2. Samgyeopsal - grilled pork belly
3. Kimbap - rice rolls with various fillings
4. Jajangmyeon - black bean noodles
5. Hotteok - sweet pancakes with filling
6. Mandu - dumplings
7. Gimbap - seaweed rice rolls
8. Dakkochi - grilled chicken skewers
9. Sundae - Korean blood sausage
10. Bungeoppang - fish-shaped pastry filled with red bean paste.
Total Tokens: 0
결과를 보면 두번째 결과는 Token이 0으로 캐싱이 된것을 확인할 수 있다.
여기서 우리는 잠깐 생각해봐야 하는 문제가 있다. 서울에서 유명한 음식이라는 문맥적은 의미는 유사하지만 첫번째 프롬프트는 10개의 음식을 두번째 프롬프트는 5개의 음식을 추천해달라고 했는데, 두번째 결과는 10개의 음식이 캐시의 값에서 리턴되었다. 임베딩을 이용한 유사도 분석은 말 그대로 유사도 분석으로 비슷한 단어가 많이 나오는 문장을 찾을뿐이고 100% 정확한 의미를 찾아낼 수 없다. 그래서 문장 의미 수준의 캐시 히트는 기대할 수 없으니 이 부분을 유의할 필요가 있다.
또한 RedisSementicCache의 경우에는 유사도 분석 알고르즘을 지정할 수 없고, 어느정도 정확도로 매칭이 되면 캐시가 히트 된것인지 (즉 Throughput 값)를 지정할 수 없다.
운영환경 수준에서 세부 캐시 컨트롤이 필요할 경우 임베딩 알고리즘과 벡터 데이터베이스를 이용해서 직접 캐싱 시스템을 구축하는 것을 권장한다.
정확도는 떨어지지만 개발과정에서 불필요한 반복적인 LLM 모델 호출 횟수를 줄여서 비용 절감을 할 수 있고 또한 API 호출 횟수를 줄임으로써 응답시간을 향상 시킬 수 있기 때문에, , 유스케이스 시나리오에 따라서는 운영 환경에서도 활용할 수 있기때문에, LLM 애플리케이션 개발에서는 캐싱을 꼭 고려해보기를 추천한다.