LLM 애플리케이션 개발을 위한 Langchain - #3 Model 및 호출 방법
Langchain Model 컴포넌트와 호출 방법
조대협 (http://bcho.tistory.com)
Model은 Langchain 에서 ChatGPT나 PaLM 모델을 추상화한 객체이다. 보통 LLM모델들이 문장을 완성하는 LLM 기능 (질문에 대한 답변, 문서 요약, 아이디어 제공 등등)의 모델과, 사람과 상호작용을 하는 채팅을 위한 두 가지 모델을 제공한다. Langchain도 마찬가지로 이 두 가지 모델에 대한 추상화 계층을 제공하고 있다.
LLM은 입력된 프롬프트의 명령에 따라 답변을 내는 모델이다.
ChatGPT, PaLM API등의 LLM 모델에 대한 추상화 객체를 제공한다.
LLM 모델 객체를 생성하는 방법은 모델 제공자에 따라 다르며, 특히 모델 제공자에 따라서 지원하는 튜닝 가능한 패러미터들도 다르다. 예를 들어 chatgpt의 경우에는 temperature값을 설정할 수 있고, 구글의 PaLM Vertex AI의 경우 temperature, Top-K/P 등의 값을 추가로 설정할 수 있다. Langchain에서 지원되는 LLM 모델에 대해서는 langchain 공식 문서 https://python.langchain.com/docs/integrations/llms/ 를 참고하기 바란다.
LLM 객체를 생성한 후에 호출하는 방법은 여러가지 방법이 있는데, 먼저 간단하게 동기 방식으로 LLM에 질문을 하는 방법은 다음과 같이 llm.invoke(prompt) 메서드를 사용하면 된다.
# Invoke
from langchain import PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="{YOUR_API_KEY}")
prompt = "What is famous street foods in Seoul Korea in 200 characters"
llm.invoke(prompt)
앞의 예제는 LLM을 호출할때, 단순하게, 하나의 프롬프트만 동기형으로 호출하였는데, 여러개의 프롬프트를 동시에 호출하거나 또는 호출을 비동기로 하는 등의 다양한 호출 패턴이 있을 수 있다. Langchain은 이러한 다양한 호출 패턴을 지원한다. (참고. 지원하는 LLM에 따라서 지원되는 호출 패턴이 다를 수 있으니 https://python.langchain.com/docs/integrations/llms/ 에서 지원 되는 호출 패턴을 미리 확인하기 비란다.)
Batch
먼저 Batch는 만약에 여러개의 질문이나 명령을 내려야 할 경우, 루프를 도는 것이 아니라,파이썬 리스트에 프롬프트 목록을 저장한 후에 batch 호출을 이용하여, 한번에 여러 질문을 호출할 수 있다.
# Batch
prompts = [
"What is top 5 Korean Street food?",
"What is most famous place in Seoul?",
"What is the popular K-Pop group?"
]
llm.batch(prompts)
다음은 호출 결과 이다.
['\n\n1. Tteokbokki (Spicy Rice Cakes)\n2. Odeng (Fish Cake Skewers)\n3. Sundae (Korean Blood Sausage)\n4. Gimbap (Korean Sushi Roll)\n5. Hoppang (Steamed Rice Cakes)',
'\n\nOne of the most famous places in Seoul is Gyeongbokgung Palace, the main royal palace of the Joseon Dynasty. It is considered one of the most iconic landmarks in the city and is a popular tourist destination.',
'\n\nThe most popular K-Pop group is BTS (Bangtan Boys). Other popular K-Pop groups include EXO, Blackpink, Twice, Red Velvet, and NCT.']
[ ]:
Streaming
다음으로는 스트리밍 호출이 있는데, 모델의 사이즈가 크거나 프롬프트가 클때는 응답 시간이 느릴 수 있다. 그래서 이 응답을 모두 기다렸다가 결과를 출력하는데 시간이 많이 소요될 수 있는데, 이런 문제를 해결 하기 위해서 Langchain은 스트리밍 패턴을 지원한다. 응답이 생성되는대로 스트리밍으로 응답을 실시간으로 리턴할 수 있다. 주로 챗봇과 같은 실시간성이 필요한 애플리케이션에서 자주 사용된다.
다음은 호출 예제이다. invoke()대신, stream()을 사용하면, 계속해서 결과를 리턴하는 것을 확인할 수 있다. (예제를 실행해보면 애니메이션 처럼, 문장이 순차적으로 출력되는 것을 확인할 수 있다.)
prompt = "What is famous street foods in Seoul Korea in 200 characters"
for chunk in llm.stream(prompt):
print(chunk, end="", flush=True)
비동기 호출
이 3 가지 invoke, batch, streaming 은 동기 방식이외에도 비동기 방식으로도 호출이 가능하다.
아래는 같은 프롬프트를 ainvoke를 이용해서 비동기로 10번 호출하고, invoke로 10번 호출하여 호출 시간을 비교한 예제 코드이다. (참고로 아래 코드는 Jupyter 노트북에서 작성하여 실행하였다.)
import asyncio
import time
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="{YOUR_API_KEY}")
prompt = "What is famous Korean food? Explain in 50 characters"
# Async call
async def invoke_async(llm):
result = await llm.ainvoke(prompt)
print(result)
async def invoke_parallel():
tasks = [invoke_async(llm) for _ in range(10)]
await asyncio.gather(*tasks)
start_time = time.perf_counter()
await invoke_parallel()
end_time = time.perf_counter()
print("Async execution time:" , (end_time-start_time))
# Sync call
start_time = time.perf_counter()
for i in range(10):
result = llm.invoke(prompt)
print(result)
end_time = time.perf_counter()
print("Sync execution time:" ,(end_time-start_time))
비동기 api를 사용한 경우 동시에 병렬로 호출이 되기 때문에, 호출 속도가 동기 5.8초 대비 1.9초로 빠른것을 확인할 수 있다.
Kimchi, a fermented vegetable dish, is a famous Korean food.
Kimchi, a spicy fermented cabbage dish, is a famous Korean food.
Kimchi, a spicy fermented cabbage dish, is a popular Korean food.
Kimchi, a spicy fermented cabbage dish, is a famous Korean food.
Kimchi, a fermented cabbage dish, is the most famous Korean food.
Kimchi - a spicy, fermented cabbage dish that's a staple of Korean cuisine.
Kimchi, a spicy fermented vegetable dish, is the most famous Korean food.
Kimchi, a fermented cabbage dish, is one of the most famous Korean foods.
Korean BBQ, kimchi, bibimbap, and japchae are all famous Korean dishes.
Kimchi, a spicy fermented cabbage dish, is the most famous Korean food.
Async execution time: 1.911825390998274
Kimchi, a spicy fermented cabbage dish, is the most famous Korean food.
Korean BBQ, Kimchi, Bibimbap, and Japchae are popular Korean dishes.
Kimchi, a spicy fermented cabbage dish, is one of the most famous Korean foods.
Kimchi, a spicy fermented cabbage dish, is a famous Korean food.
Kimchi, a fermented cabbage dish, is a famous Korean food.
Kimchi, a spicy fermented cabbage dish, is a famous Korean food.
Kimchi, bulgogi, bibimbap, and samgyeopsal are some of the most popular Korean dishes.
Kimchi, a spicy fermented cabbage dish, is a famous Korean food.
Kimchi, a fermented vegetable dish, is one of the most famous Korean foods.
Kimchi, a spicy fermented cabbage dish, is the most famous Korean food.
Sync execution time: 5.830645257010474
대부분 동기와 비동기 호출의 개념에 대해서는 알고 있겠지만 정리하는 의미해서 설명하고 가면, 동기 호출은 API를 호출하였을때 응답을 받아야 다음 코드로 진입을 할 수 있는 호출 방식이다. 즉 10개의 API를 호출 하였으면, 각 API에 대한 응답을 받아야 다음번 호출을 할 수 있다. 반면 비동기 호출은 답변을 기다리지 않고, 호출을 한다. 10개의 API를 호출 하면서 응답을 기다리지 않고 바로 다음 코드로 진행을 한다. 응답이 올때까지 대기 하기 위해서 위의 코드에서는 await 를 사용하였다.
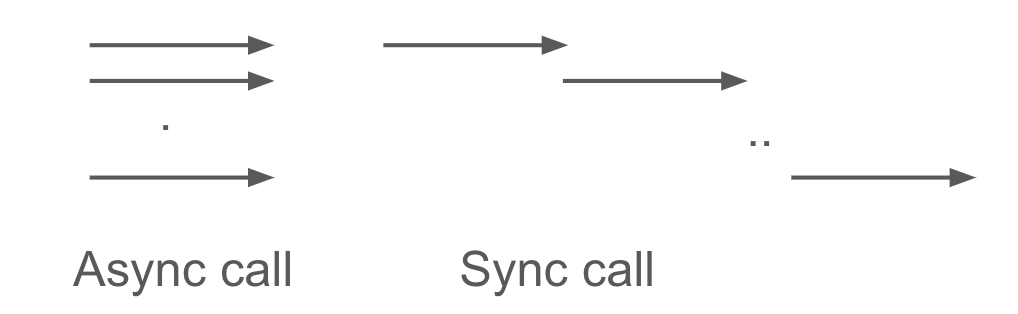
<그림. 동기/비동기 호출을 통한 LLM 모델 호출 개념>
그림으로 표현해보면 비동기 호출은 동시에 10개의 api 를 호출 하는 좌측 그림이고, 동기호출은 api를 각각 하나씩 호출하고 응답을 받는 형태의 패턴이다.