LLM 애플리케이션 개발을 위한 Langchain - #2 주요 컴포넌트
Langchain의 주요 구성 요소 소개
조대협 (http://bcho.tistory.com)
Langchain이 어떤 컴포넌트로 구성되어 있는지 살펴보자. 2023년 12월 현재 Langchain 라이브러리는 많은 업데이트가 있어서 이전 버전에 비교해서 컴포넌트 구성이나 기능이 다소 변경되었다.
Langchain을 구성하는 주요 컴포넌트로는 Model, Prompt Template, Output Parser, Chain, Agent, Retrieval이 있다. 각각의 컴포넌트에 대해서 살펴보자.
Model
먼저 Model 컴포넌트는 LLM 모델을 추상화하여 제공한다. 모델 컴포넌트는 입력으로 들어온 프롬프트에 대해서 텍스트 답변을 리턴하는 기능을 제공한다.
Langchain은 다양한 LLM 모델을 지원하고 있다. (지원되는 LLM 리스트 : https://python.langchain.com/docs/integrations/llms/) LLM에 따라서 다른 옵션을 제공하는데 예를 들어 OpenAI ChatGPT의 경우에는 temperature를 세팅이 가능하지만 Top-K,P는 설정이 불가능하다. Google PaLM2 API의 클라우드 버전인 Vertex.AI 모델은 Temperature, output 토큰등 다양한 옵션 지원이 가능하다. 각각 지원되는 옵션은 Langchain 문서를 참고하기 바란다.

<그림. Langchain에서 Model 컴포넌트의 개념 >
모델은 LLM뿐만 아니라 LLM 기반의 ChatModel도 지원한다. LLM이 하나의 문자열을 읽어서 하나의 문자열을 리턴하는 모델이라면, ChatModel은 여러 대화 문장을 입력으로 받아서 다음 대화 문장을 답변하는 형태의 채팅에 최적화된 모델이다. LLM 모델과 같이 ChatModel 역시 다양한 벤더에서 제공되는 모델과 오픈소스 모델들이 있으며, Langchain에서 지원되는 ChatModel의 목록은 https://python.langchain.com/docs/integrations/chat/ 를 참고하기 바란다.
일반적인 텍스트 처리는 LLM모델을 사용하고, 챗봇같은 경우에는 ChatModel을 사용하여 LLM 애플리케이션을 개발하게 된다.
Prompt Template
LLM 모델에 프롬프트를 입력하여 결과를 받는 과정을 보면, 유스케이스나 사용자에 따라서 프롬프트 자체는 똑같은데, 일부 내용만 변경하여 같은 프롬프트를 사용하는 경우가 있다. 예를 들어 “서울에서 가장 유명한 관광지는?”, “샌프란시스코에서 가장 유명한 관광지는?”와 같이 도시 이름은 변경되고 전체 프롬프트는 변경이 안되는데, 이렇게 변경되는 부분만 변수 처리를 하고, 템플릿에 이를 넣어서 프롬프트를 생성하는 컴포넌트를 Prompt Template 이라고 한다.

<그림. Prompt Template의 개념>
Output Parser
LLM 모델에서 나온 출력 결과를 요구사항에 따라서 JSON,XML 또는 Pandas DataFrame 과 같은 다양한 포맷으로 포맷팅을 해야할 필요가 있는데, Output Parser는 LLM모델에서 결과로 나온 값을 포맷에 맞춰서 파싱하여 텍스트로 반환하는 역할을 한다.
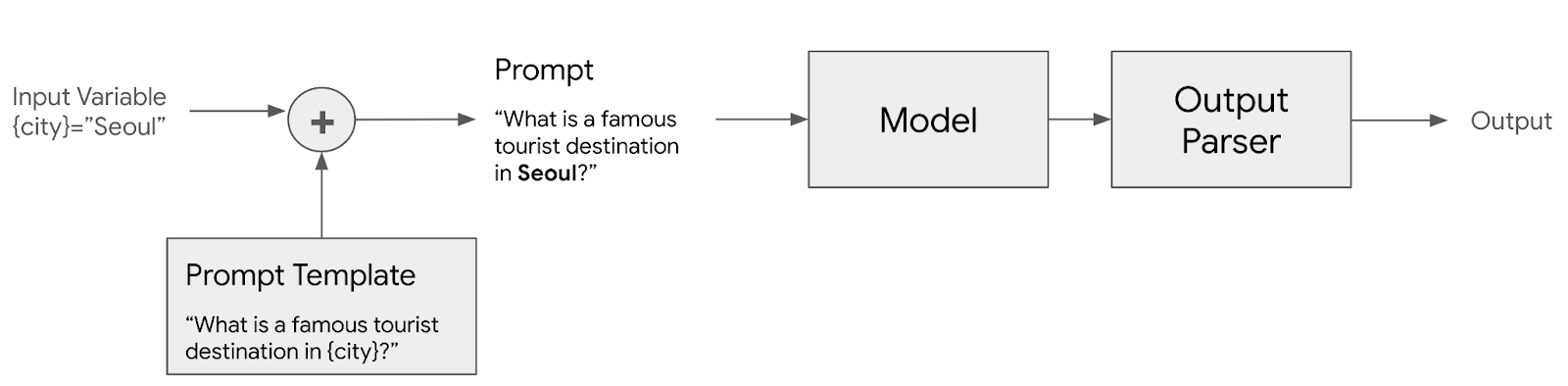
<그림. Output Parser 컴포넌트 개념>
Chain
LLM 으로 애플리케이션을 개발할때, 하나의 프롬프트로 해결이 어려운 경우가 있다. 예를 들어 한글로 프롬프트를 만드는 것보다 영문으로 프롬프트를 만들때 정확도가 높다면 첫번째 LLM 호출에서 한글을 영어로 번역한 후에, 두번째 LLM 호출에서 영문 프롬프트를 실행하는 흐름이다.
단순하게 두번 호출을 연결하는 모델을 예시로 들었지만 실제 LLM 애플리케이션은 경우에 따라서 훨씬 많은 단계를 필요로 할 수 도 있다. 아래 그림을 보자.

<그림. Chain 예시>
예를 들어 특정 토픽에 대한 트워터 메세지를 분류하는 시스템이 있다고 가정하자.
- Model 1 에서는 트위터 메세지를 영문으로 변경한다.
- Model 2 에서는 영문으로 변경된 메세지를 가지고 어떤 카테고리의 메세지인지를 분류한다.
- Model 3에서는 원본 트위터 메세지를 가지고 메시지의 언어가 어느 언어인지(한글, 영어, 중국어)를 판단한다.
- 마지막으로 Model 4에서는 Model2와 Model3의 출력값을 조합하여 포맷팅하여 출력한다.
이렇게 다단계에 걸친 흐름 제어가 가능하며, 더 나아가서 텍스트 처리에 대한
- 동기/비동기 호출
- 배치 처리
- 여러 LLM에 대한 병렬 처리
- 단계별로 다른 LLM 모델 사용 (예를 들어 Model 1은 Google PaLM Model, Model 4는 ChatGPT 3.5)
- 출력값에 대한 스트리밍 처리
등이 가능하다. Chain은 고급 LLM 애플리케이션을 만들기 위해서 중요한 기능이기 때문에 뒤에서 다시 자세하게 설명하도록 하겠다.
Agent & Tools
LLM은 모델 안에 지식이 이미 학습되어 있기 때문에, 모델이 아는 한도내에서만 답변을 할 수 있다. 그러나 실제 애플리케이션은 기업내 시스템의 데이터베이스에서 데이터를 가지고 와서 이를 기반으로 분석하여 답변을 내야할 수 도 있고, 구글 서치 엔진을 통하여, 인터넷의 데이터를 가지고와서 검색된 문서를 기반으로 답변을 만들 수 있다. 이렇게 LLM이 외부 서비스와 연동할 수 있게 해주는 컴포넌트를 Tool이라고 한다.
LLM 모델은 동시에 여러개의 Tool 들을 사용할 수 있는데, 이때 문제는 주어진 질문에 대해서 어떤 Tool을 사용할까이다. 이를 결정해주는 것이 Agent이다. Agent는 질문에 대한 적절한 Tool을 찾기 위해서 여러가지 방법을 사용하는데, 일반적으로는 Agent는 Tool을 등록할때 포함되는 Tool에 대한 설명 (Description)을 이용하여 LLM이 어떤 Tool이 해당 문제에 적절한지를 판단하도록 한다.

<그림. Agent & Tool의 개념 구조>
Retrieval
마지막으로 Retrieval은 RAG (Retrieval Argument Generation) 아키텍처에서 사용되는 라이브러리이다.
앞서도 언급했듯이 LLM은 학습된 지식을 기반으로만 답변을 할 수 있는데, 회사에 문서가 있거나, 또는 특정 서비스에 대한 메뉴얼과 같은 문서가 있을때, 이 문서를 Document Database에 저장해놓고, LLM에 대한 질문에 대해서 답변을 하기 위해 필요한 정보가 있을 경우 Document Database를 검색하여, 질문과 관련된 문장(또는 문단)을 검색한 후, 이 문장을 기반으로 LLM이 답변을 하게 하는 구조이다.

<그림. Document Retrieval의 개념>
이를 위해서는 문서를 저장해서 검색 인덱스를 만들기 위한 기능, 큰 문서를 여러개의 조각으로 나눠서 인덱스를 만드는 기능등 여러가지 추가 기능이 필요한데, Retrieval 컴퍼넌트를 이런 기능들을 제공한다.
지금까지 LangChain을 구성하고 있는 각각의 컴포넌트의 개념에 대해서 간단하게 알아 보았다. 다음 챕터 부터는 Langchain의 각 컴포넌트에 대한 구체적인 설명과 예제를 소개하도록 한다.