ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #6 임베딩을 위한 효과적 문장 분리 방법
임베딩을 위한 효과적 문장 분리 방법
조대협(http://bcho.tistory.com)
임베딩에서 알고리즘도 중요하지만 가장 중요한 것중 하나는 어떻게 문서를 파편으로 잘라낼것인가? (이를 영어로 Chunking이라고 한다.) 이다.
임베딩은 텍스트를 고정된 크기의 벡터로 변경하는 것이기 때문에, 긴 문단을 작은 벡터로 임베딩하게 되면 디테일한 의미를 잃어버릴 수 있고, 반대로 작은 문장으로 임베딩을 하면, 검색시 문장에 대한 정확도는 올라가겠지만, 문장이 짧아서 문장 자체가 가지고 있는 정보가 부족하게 된다. 그래서 적절한 Chunk 사이즈를 찾아내는 방법이 중요한데, 이를 Chunking strategy (문서 파편화 전략)이라고 한다.
이 글에서는 몇가지 대표적인 Chunking 방식과, 같이 활용할 수 있는 팁에 대해서 알아보기로 한다.
Fixed Size Chunking
가장 간단한 Chunking 방식은 문서를 고정된 길이 단위로 잘라내는 방법이다. 예를 들어 5000문자의 문서가 있을때, 기계적으로 100자나 200자씩 등으로 잘라내는 방식이다.

<그림. 고정 길이 Chunk 개념>
이 방식은 구현이 매우 쉽지만, 문제는 문장이 온전하지 않게 잘릴 수 있는 문제를 가지고 있기 때문에, 그다지 좋은 방법은 아니다.
Content-Aware chunking
다음 방식으로는 문맥을 인지하는 방식으로 Chunking을 하는 방식인데, 쉽게 말해서 문장이나 문단 단위로 문서를 잘라내는 방식이다. 문장과 문단을 온전히 보장할 수 있는 장점이 있는 반면에, 문장이나 문단의 길이가 길 경우 Chunk의 사이즈가 커지는 문제가 있다. 또한 텍스트에서 마침표나 줄 띄위기등을 제대로 사용하지 않았을 경우에 제대로 문장을 나눠내지 못하며, 제목이나, 번호 (문서에서 1. 2. 3. 식으로 번호를 달았을 경우 마침표를 인식해서 숫자를 하나의 문장으로 인식해버릴 수 있다.)
아래는 NLTK 파서를 이용하여, 문장 단위로 Chunk를 추출하는 예제이다.
text="""
To Kill a Mockingbird by Harper Lee is a classic American novel set in the racially charged atmosphere of the 1930s in the fictional town of Maycomb, Alabama. The story is narrated by Scout Finch, a young girl, and follows the Finch family, particularly her father, Atticus Finch, who is a lawyer.
The narrative unfolds as Atticus defends Tom Robinson, a black man falsely accused of raping a white woman, Mayella Ewell. The novel explores themes of racial injustice, moral growth, and the loss of innocence. Through the lens of Scout's childhood, the reader witnesses the harsh realities of prejudice and discrimination prevalent in the Deep South.
Atticus Finch emerges as a moral compass in the story, embodying principles of justice, empathy, and integrity. His defense of Tom Robinson, despite the pervasive racial biases of the town, symbolizes a stand against ingrained social norms. The trial becomes a focal point, revealing the deeply rooted racism and injustice in the community.
Scout and her brother, Jem, befriend a boy named Dill, and the trio becomes fascinated by their reclusive neighbor, Boo Radley. Boo becomes a symbolic figure representing the unknown and the misunderstood. The children's curiosity about Boo provides a parallel narrative to the trial, emphasizing the themes of prejudice and the consequences of making judgments based on appearances.
: <중략>
"""
#NLTK Sentence Tokenizer
import nltk
nltk.download('punkt')
# Splitting Text into Sentences
def split_text_into_sentences(text):
sentences = nltk.sent_tokenize(text)
return sentences
sentences = split_text_into_sentences(text)
for sentence in sentences[:3]:
print(sentence)
print("="*40)
아래 결과를 보면, “.” 마침표를 기점으로 문장단위로 Chunk를 추출한것을 확인할 수 있다.
To Kill a Mockingbird by Harper Lee is a classic American novel set in the racially charged atmosphere of the 1930s in the fictional town of Maycomb, Alabama.
========================================
The story is narrated by Scout Finch, a young girl, and follows the Finch family, particularly her father, Atticus Finch, who is a lawyer.
========================================
The narrative unfolds as Atticus defends Tom Robinson, a black man falsely accused of raping a white woman, Mayella Ewell.
========================================
Recursive chunking
다음 방법은 Recursive chunking (재귀적 파편화) 기법인데, 앞의 Fixed와 Context-Aware 방식을 혼합했다고 생각하면 된다.
먼저 “.” 나 줄바꿈 단위로 문장을 추출한 다음에, 그 문장이 원하는 고정 사이즈 (Fixed Size)보다 클 경우, 다시 Fixed size로 자른후, 나머지 문장을 “.”나 줄바꿈으로 재귀적으로 호출하는 방식이다.

<그림. Recursive chunking의 개념>
아래 코드는 langchain 오픈 소스의 RecursiveCharacterTextSplitter를 이용하여 Recursive chunking을 하는 예제이다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 300,
chunk_overlap = 100,
length_function = len,
is_separator_regex = False,
)
docs = text_splitter.split_text(text)
for chunk in docs[:10]:
print(len(chunk))
print(chunk)
print('='*10)
아래 결과를 보면 처음 297 길이의 문장은 “.” 까지 온전히 추출된걸 볼 수 있지만 두번째 문장은 300자보다 길기 때문에, 중간에 잘려서 293,154 문자열 두개로 추출된것을 확인할 수 있다.
297
To Kill a Mockingbird by Harper Lee is a classic American novel set in the racially charged atmosphere of the 1930s in the fictional town of Maycomb, Alabama. The story is narrated by Scout Finch, a young girl, and follows the Finch family, particularly her father, Atticus Finch, who is a lawyer.
==========
293
The narrative unfolds as Atticus defends Tom Robinson, a black man falsely accused of raping a white woman, Mayella Ewell. The novel explores themes of racial injustice, moral growth, and the loss of innocence. Through the lens of Scout's childhood, the reader witnesses the harsh realities of
==========
154
of innocence. Through the lens of Scout's childhood, the reader witnesses the harsh realities of prejudice and discrimination prevalent in the Deep South.
==========
294
Atticus Finch emerges as a moral compass in the story, embodying principles of justice, empathy, and integrity. His defense of Tom Robinson, despite the pervasive racial biases of the town, symbolizes a stand against ingrained social norms. The trial becomes a focal point, revealing the deeply
Chunking 테크닉
이렇게 문서의 단락을 추출하는 방법은 여러가지가 있지만 여기에 덧붙여서 같이 활용할 수 있는 기법들이 있다. 특히 짧은 문장만으로는 LLM 모델이 원하는 정보를 제대로 전달할 수 없고 또는 문장이 중간에 잘려 버렸을 경우에는 온전한 의미 전달이 어렵기 때문에, 이를 보완하기 위한 방법이 필요하다.
Overlapping
첫번째 기법은 오버래핑 이라는 기법이다. 앞의 예제의 출력 결과의 두번째와 세번째 문장을 잘 살펴 보면 문장이 겹치는 부분이 있다. (아래 예제에서 하이라이트 부분)
297
To Kill a Mockingbird by Harper Lee is a classic American novel set in the racially charged atmosphere of the 1930s in the fictional town of Maycomb, Alabama. The story is narrated by Scout Finch, a young girl, and follows the Finch family, particularly her father, Atticus Finch, who is a lawyer.
==========
293
The narrative unfolds as Atticus defends Tom Robinson, a black man falsely accused of raping a white woman, Mayella Ewell. The novel explores themes of racial injustice, moral growth, and the loss of innocence. Through the lens of Scout's childhood, the reader witnesses the harsh realities of
==========
154
of innocence. Through the lens of Scout's childhood, the reader witnesses the harsh realities of prejudice and discrimination prevalent in the Deep South.
==========
294
Atticus Finch emerges as a moral compass in the story, embodying principles of justice, empathy, and integrity. His defense of Tom Robinson, despite the pervasive racial biases of the town, symbolizes a stand against ingrained social norms. The trial becomes a focal point, revealing the deeply
이는 문장을 추출하다가 고정 크기(Fixed length)에 의해서 문장이 잘렸을 경우, 앞의 일정 길이의 문장을 중첩해서 추출하는 방식이다. 이 방식을 사용할 경우, 문장이 강제적으로 잘리더라도 최소한 앞의 문장을 덧 붙임으로써 의미가 훼손되는 것을 방지 할 수 있다.
Parent Child chunking
다음 방식은 Parent Child Chunking 기법으로, 일반적으로 LLM은 프롬프트에 32,000자의 입력을 넣을 수 있고, ChatGPT4-Turbo의 경 300 페이지의 입력을 넣을 수 있다. 프롬프트에 컨텍스트 정보를 넣을 것이며 궂이 한문장이나 한문단 정도만 넣을 필요 없이, 그 정보를 담고 있는 페이지 전체를 넣으면 더 높은 정확도를 기대할 수 있다. (단 입력 내용이 많아질수록 토큰 수가 증가하기 때문에, 호출 비용이 증가 한다.)
이런 구조를 지원하기 위한 기법이 Parent Child Chunking 방식이다.
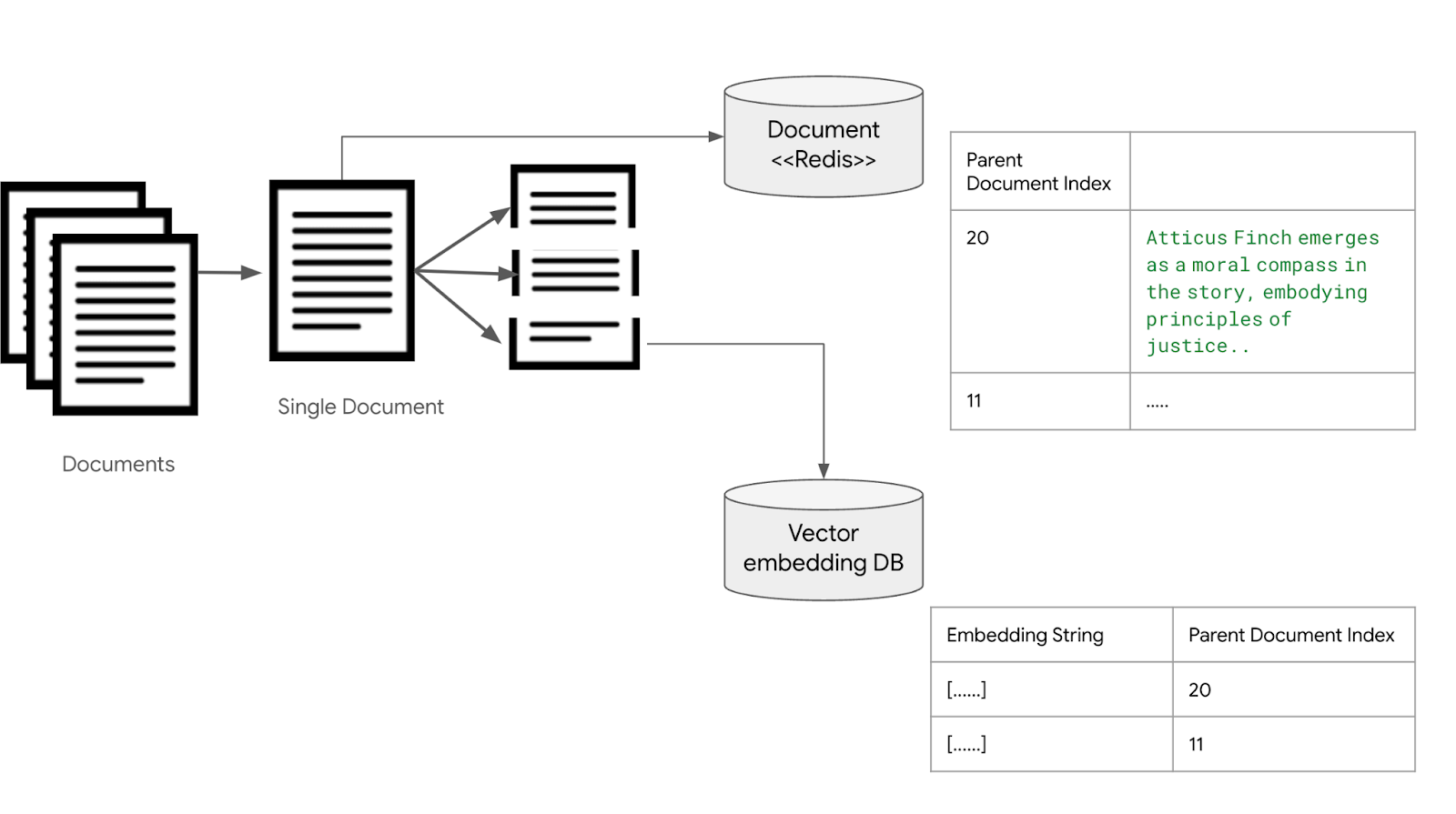
<그림. 부모/자식 검색 구조를 위해서 임베딩과 원본 문서를 분리 저장하는 구조>
문서들을 작은 Chunk 단위로 나눠서 벡터 임베딩 데이터베이스 (Vector Embedding DB)에 저장하는 과정은 같다. 이때, 필드에 임베딩과 문장의 내용을 저장하는 것이 아니라, 이 문장이 속해 있는 문서의 인덱스를 저장한다. 각 문서는 redis나 DB, 파일 시스템등에 저장해놓는다.
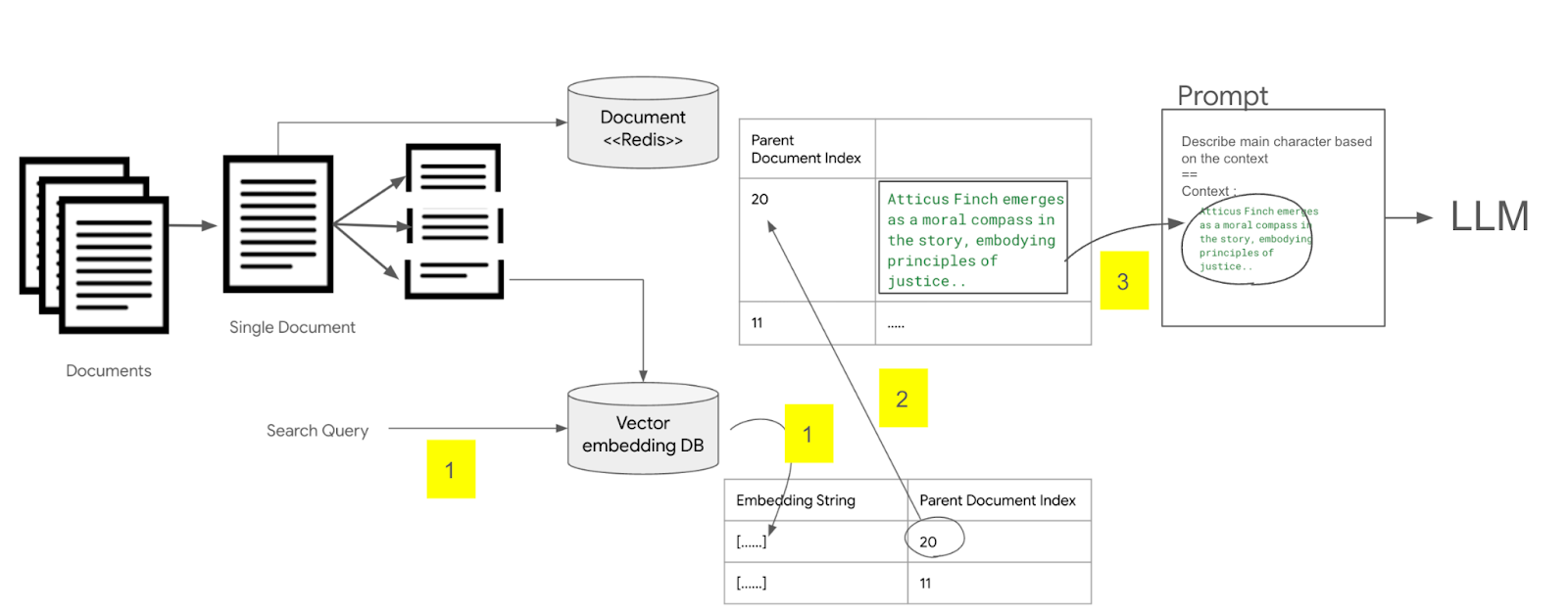
<그림. 부모 문서를 검색해서 LLM 프롬프트에 삽입하는 구조>
다음으로 문서를 검색할때는 벡터 임베딩 데이터 베이스에서 해당 문장과 유사한 문장을 찾은 후에, 저장된 문서의 인덱스 값을 이용하여, redis에서 문서 전체를 추출한 후, 이 문서 전체 내용을 LLM 프롬프트에 컨텍스트로 사용하여 질의하는 방식이다.
상대적으로 비용은 많이 들지만, 전체의 문맥을 온전히 LLM에 전달할 수 있고, 정보 유실이 없기 때문에 정확한 정보 전달이 필요한 경우에는 추천되는 방식이다.
Chunk summarization
다른 방식으로는 문서를 문단 단위로 잘라낸 다음에, 일정 크기 이하로 요약하는 방법이다. 즉 Context-Aware Chunking을 이용하여, 문단을 추출한후, LLM을 통하여 OOO자 이하로 요약을 하게 한 후에, 이 요약된 문장으로 임베딩 인덱스를 만드는 방법이다.
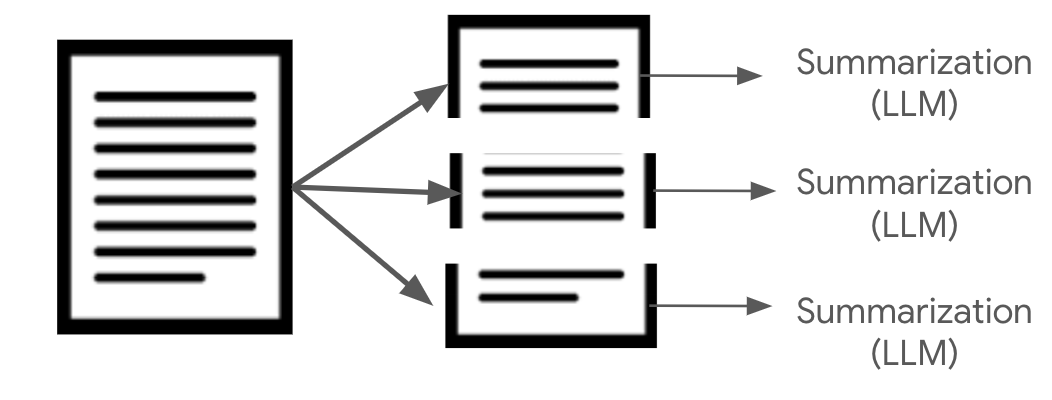
문장이 중간에 잘리지 않는 장점이 있지만 반대로 요약 과정에서 정보가 유실될 수 있는 단점이 있다.
Extract candidate question
요약과 유사하게 문서 (문장도 가능)를 LLM에 컨택스트로 제공한후, 해당 문서(또는 문장)에서 예상되는 질문 N개를 추출하도록 한후에, 이 질문으로 임베딩 인덱스를 생성하는 방법이다.
이 방법은 챗봇이나 Q&A 시스템등에 효율적으로 사용될 수 있ㄷ.
하이브리드 접근 방식
위의 여러가지 팁을 설명하였지만, 궂이 하나의 방법만을 사용할 필요는 없다. 예를 들어 Extract candidate question과, Parent Child Chunk 방식을 같이 사용하여 결과를 합쳐서 사용하는 등, 해당 유스케이스 시나리오에 적합한 정확도를 높이는 방식을 사용하면 된다.
또한 임베딩뿐 아니라 Elastic Search와 같은 FTS (Full Text Search)와 혼합하여, 텍스트 검색을 통해서 검색된 문서와 임베딩 검색을 통해서 검색된 문서를 합해서 정확도로 랭킹을 한 후에, 그 결과를 프롬프트에 활용하는 방식도 있다.
이때 FTS와 벡터 서치 결과를 합쳐야 하는데, 여러개의 모델의 결과를 병합하는 방법을 Ensemble이라고 하는데, Ensemble에는 크게 Begging과 Boosting 방식이있다. FTS와 벡터 서치의 결과를 합치기 위해서는 Boosting 알고리즘을 활용하는 것이 좋다. Boosting의 개념에 대해서는 https://bcho.tistory.com/1354 글을 참고하기 바란다.