ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #4 텍스트 임베딩하기
OpenAI Embedding 모델을 이용하여 텍스트 임베딩 하기
조대협 (http://bcho.tistory.com)
앞의 글에서 Pinecone 데이터베이스를 이용하여 벡터 데이터를 어떻게 저장하는지 알아보았다.
그러면 텍스트나 이미지와 같은 데이터를 어떻게 벡터데이터로 변환하는 지를 알아보도록 하겠다.
이렇게 원본 데이터를 벡터로 변환하는 과정을 임베딩이라고 한다. 임베딩의 개념과 임베딩된 데이터에 대한 검색 방법은 https://bcho.tistory.com/1400 글을 참고하기 바란다.
데이터를 임베딩하는 방법은 간단하게 API를 사용하면 되는데, OpenAI의 경우 다양한 임베딩 API 를 제공한다.
1 세대 모델은 다음과 같다.

요즘은 “text-embedding-ada-002” 모델을 주로 사용한다. 이 모델은 최대 8191개의 토큰을 하나의 벡터로 임베딩할 수 있으며, 임베딩된 벡터의 크기는 1536 차원 (Dimension)이다.
아래 코드는 주피터랩에서 작성하였다.
먼저 사용할 라이브러리들을 인스톨한다.
!pip install openai scipy plotly-express scikit-learn umap-learn umap
임베딩에 사용할 텍스트 파일은 USPGA 골프 규칙으로 약 30+ 개의 규칙을 각각의 파일에 담고 있다.
예제에서 사용한 텍스트 파일들은 이 글에 첨부하였다.
import os
import openai
import pandas as pd
# Set your OpenAI API key
openai.api_key = "{Youe OpenAI API Key}"
# Define the directory containing the files
input_directory = "./golf_rule_paragraph"
# List all files in the directory and sort them alphabetically
file_list = sorted(os.listdir(input_directory))
# Limit to the first 10 files
file_list = file_list[:50]
# Initialize an empty list to store document texts and embeddings
data = []
# Read the content of each file, get the embedding, and append to the data list
for filename in file_list:
file_path = os.path.join(input_directory, filename)
with open(file_path, 'r', encoding='utf-8') as file:
document_text = file.read()
embedding_result = openai.Embedding.create(
model = "text-embedding-ada-002",
input = document_text
)
embedding = embedding_result['data'][0]['embedding'] #embedding with 1536 dim
data.append({"document_text": document_text, "embedding": embedding})
# Create a DataFrame from the data list
df = pd.DataFrame(data)
위의 코드는 input_directory 디렉토리 안의 파일들을 순차적으로 읽어서 임베딩을 수행하고 이를 Pandas DataFrame에 저장하는 코드이다.
실제 임베딩이 이뤄지는 코드는 아래 부분이다.
embedding_result = openai.Embedding.create(
model = "text-embedding-ada-002",
input = document_text
)
Embedding.create를 이용하여 document_text를 “text-embedding-ada-002” 모델을 이용하여 임베딩한다.
embedding = embedding_result['data'][0]['embedding'] #embedding with 1536 dim
임메딩된 결과는 embedding_result[‘data’][0][‘embedding’] 부분에 저장된다. Embedding result는 임베딩된 벡터 이외에도 다양한 메타 정보를 포함하고 있다.
임베딩된 벡터는 1536 길이의 배열인데, 임베딩이 된 결과를 벡터 공간에 시각화해서 나타내보자.
차원이 1536차원이기 때문에, 화면에 나타낼 수 없기 때문에, 차원 감소 기법 중 하나인 t-SNE를 이용하여 2차원으로 차원을 변환한 후에, 2차원에 그래프를 표현해보겠다.
from sklearn.manifold import TSNE
import numpy as np
import matplotlib.pyplot as plt
# Create a DataFrame from the data list
df = pd.DataFrame(data)
# Perform t-SNE to reduce the embedding dimensionality to 2
perplexity_value = min(5, len(df))
tsne = TSNE(n_components=2, perplexity=perplexity_value, random_state=42)
embedding_2d = tsne.fit_transform(np.array(list(df['embedding'])))
# Add the 2D embedding to the DataFrame
df['embedding_2d'] = list(embedding_2d)
# Plot the 2D embedding
plt.figure(figsize=(10, 8))
for i in range(len(df)):
plt.scatter(embedding_2d[i, 0], embedding_2d[i, 1])
plt.text(embedding_2d[i, 0], embedding_2d[i, 1], df['document_text'][i][:20]) # Display part of the document text
plt.title('t-SNE 2D Embedding')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.show()
아래는 시각화한 결과이다.
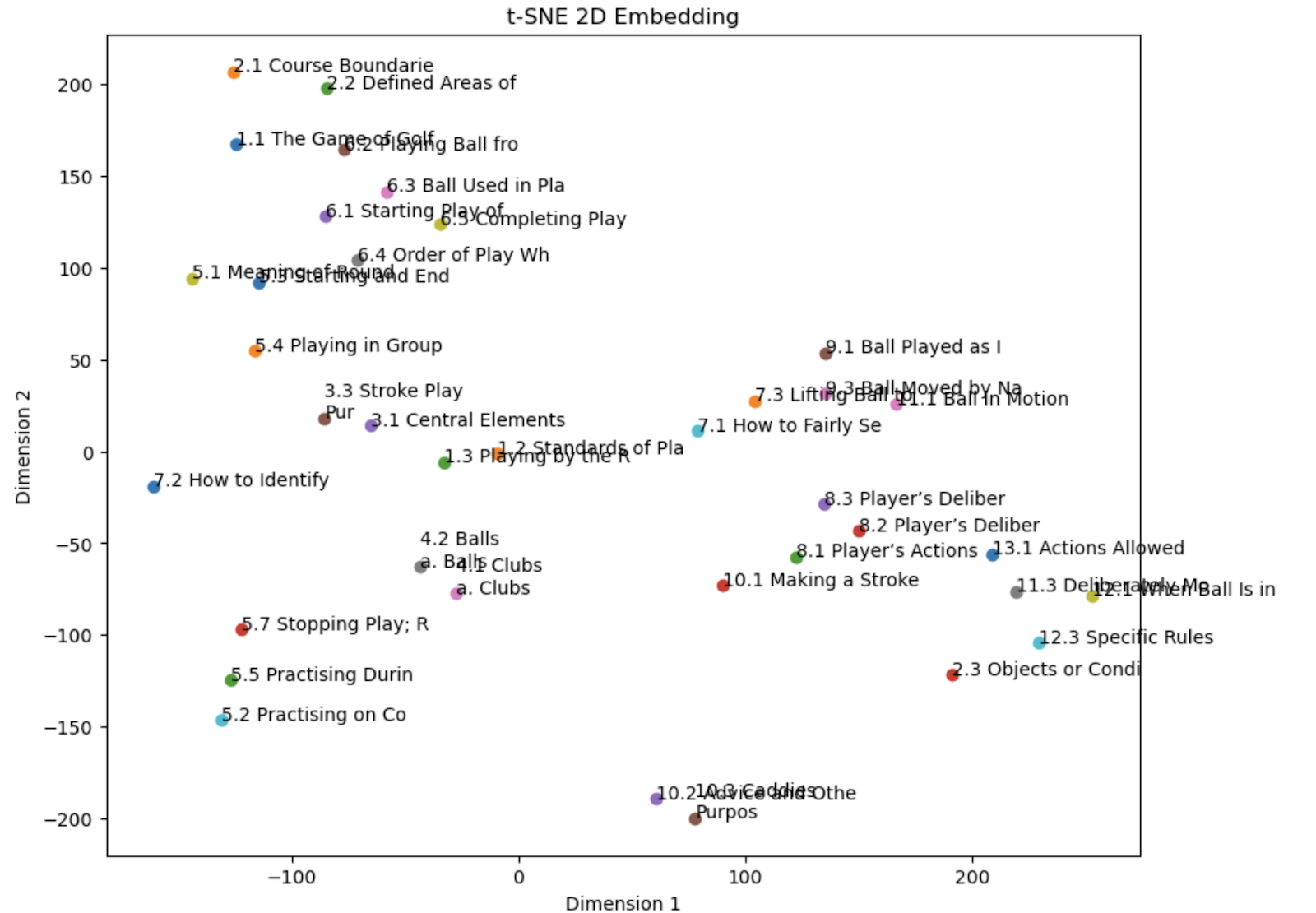
그림에서와 같이 Ball과 Club에 관련된 규칙들은 비슷한 위치에 군집이 되어 있는 것을 확인할 수 있다.
다음 글에서는 Embedding API를 이용하여, 텍스트를 임베딩한 후에, 메타 데이터와 함께 Pinecone에 저장하는 방법을 알아보도록 한다.