ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #2 - 임베딩과 유사도 검색
ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #2 - 임베딩과 유사도 검색
조대협 (http://bcho.tistory.com)
앞의 글에서 RAG가 어떻게 작동하는지에 대한 대략적인 개념에 대해서 살펴보았다. 이 글에서는 벡터데이터 베이스가 유사한 문서를 찾아내는 방법인 유사도 검색과, 텍스트등의 데이터를 이 벡터 공간으로 맵핑 시키는 임베딩의 개념에 대해서 알아보도록 한다.
임베딩의 개념
Pinecone 데이터베이스를 이해하기 위해서는 먼저 임베딩이라는 개념을 이해해야 한다. 텍스트를 그냥 데이터 베이스에 저장하는 것이 아니라, 벡터로 바꿔서 저장하는데, 단순하게 해시와 같은 방법으로 맵핑을 하는 것이 아니라 벡터 공간에 의미를 담은 상태로 변환하는 것을 임베딩이라고 한다. 즉 텍스트 임베딩은 컴퓨터가 텍스트를 이해할 수 있도록 단어나 문장을 벡터로 표현하는 방법이다. 벡터는 실수 값의 배열로, 벡터의 각 값은 단어나 문장의 특정 특성을 나타낸다.
Pinecone에 테스트 데이터를 저장하려면 먼저 텍스트를 임베딩 과정을 통하여 벡터로 변환한 후에, 저장한다.
임베딩의 예를 하나 보자 "man", "boy", "woman", "girl"의 벡터를 표현하면 다음과 같이 표현된다
man: [1, 7]
boy: [1, 2]
woman: [9, 7]
girl: [9.2]
이 벡터에서 첫 번째 차원은 성별을 나타낸다. "man"과 "boy"는 첫 번째 차원에서 1로 표현되어 있어서 남성이라는 것을 나타내고. "woman"과 "girl"은 첫 번째 차원에서 9로 표현되어 있어서 여성이라는 것을 나타낸다.
두 번째 차원은 나이를 나타낸다. "man"과 "woman"은 두 번째 차원에서 7로 표현되어 있어서 성인이고, "boy"와 "girl"은 두 번째 차원에서 2와 9.2로 표현되어 있어서 어린이라는 것을 나타낸다.
이 벡터는 단어의 의미를 잘 표현하고 있다. 예를 들어, "man"과 "boy"는 첫 번째 차원에서 유사한 위치를 차지하고 있는데, 이는 두 단어가 모두 남성이라는 의미를 나타낸다. 두 단어는 두 번째 차원에서 약간 떨어져 있지만, 여전히 유사한 공간에 있다. 이는 두 단어가 모두 성인이라는 의미를 나타내기 때문이다.

<그림 출처 : 벡터 공간에 man,boy,woman,girl 데이터를 표기한 예제>
유사도 측정 알고리즘
임베딩을 통해서 저장된 데이터 후에는 데이터를 검색해야 하는데, 여기서 검색은 벡터공간안의 저장된 데이터 간의 유사도를 측정하여 데이터를 검색한다. 예를 들어 위의 예제에서 처럼 남자에 가까운 것은 무엇인가? 에 대한 쿼리에는 boy가 리턴되어야 한다. 이를 유사도 측정 알고리즘이라고 하는데, Pinecone에서 두 벡터간의 유사도를 측정하는데 사용되는 알고리즘은 유클리안 거리 측정(Euclidean Distance), 코사인 유사도(Cosine 유사도), Dot Product(내적) 3가지 방식이 있다.
- 유클리안 거리
두 벡터간의 거리를 피타고라스 정리를 이용하여 측정한다.

<그림 출처 : https://www.pinecone.io/learn/vector-similarity/ >
공식은 : sqrt((x1 - x2)^2 + (y1 - y2)^2)
두 점(벡터)간의 거리를 측정하기 때문에 직관적이고 이해하고 쉬우나, 차원이 높아질수록 성능이 저하될 수 있다.
- 코사인 유사도
두 벡터간의 각도를 이용하여 유사도를 측정한다. 벡터의 크기(길이)에 산광없이 방향에 중점을 두기 때문에, 고차원 데이터에 효과적이자만, 벡터의 크기를 고려하지 못하기 때문에 벡터의 크기가 다른 벡터간의 유사도를 측정하기 어려운 점이 있다.

<그림 출처 : https://www.pinecone.io/learn/vector-similarity/ >
공식: (A·B) / (||A|| * ||B||)
- 내적 기반 유사도
벡터의 내적(곱)으로 벡터간의 방향성과 크기 양쪽을 모두 고려하기 때문에, 벡터의 크기가 달라도 유사도 측정이 가능하다.
<그림 출처 : https://www.pinecone.io/learn/vector-similarity/ >
공식 : A·B
예를 들어 벡터 A(2,3), B(4,1), C(1,4)가 아래 그림과 같이 있다고 하자

각 유사도 측정 알고리즘으로 측정한 결과는 다음과 같다.
| 알고리즘 | A와 B의 유사도 | A와 C의 유사도 | 더 유사한 것 |
| Euclidean Distance | 2.83 | 1.41 | A와 C |
| Cosine Similarity | 0.74 | 0.94 | A와 C |
| Dot Product | 11 | 14 | A와 C |
이러한 원리를 이용하여 벡터 데이터 베이스는 유사한 문서를 찾아낸다.
이런 유사도 검색 알고리즘은 기본적인 개념이고 실제로 검색 쿼리에 가까운 유사 문서를 찾기 위해서는 KNN과 같은 알고리즘을 사용한다. KNN에 대한 소개는 이 문서 (https://bcho.tistory.com/1009) 를 참고
KNN은 작은 차원을 갖는 작은 데이터 셋에서 유용한 알고리즘이고 이해하기가 상대적으로 편하다. 실제 Pinecone과 같은 다차원 임베딩 벡터를 대용량으로 검색하기 위해서는 다른 알고리즘이 필요한데, Pinecone에서는 ANN(Approximate Nearest Neighbors)를 사용한다.
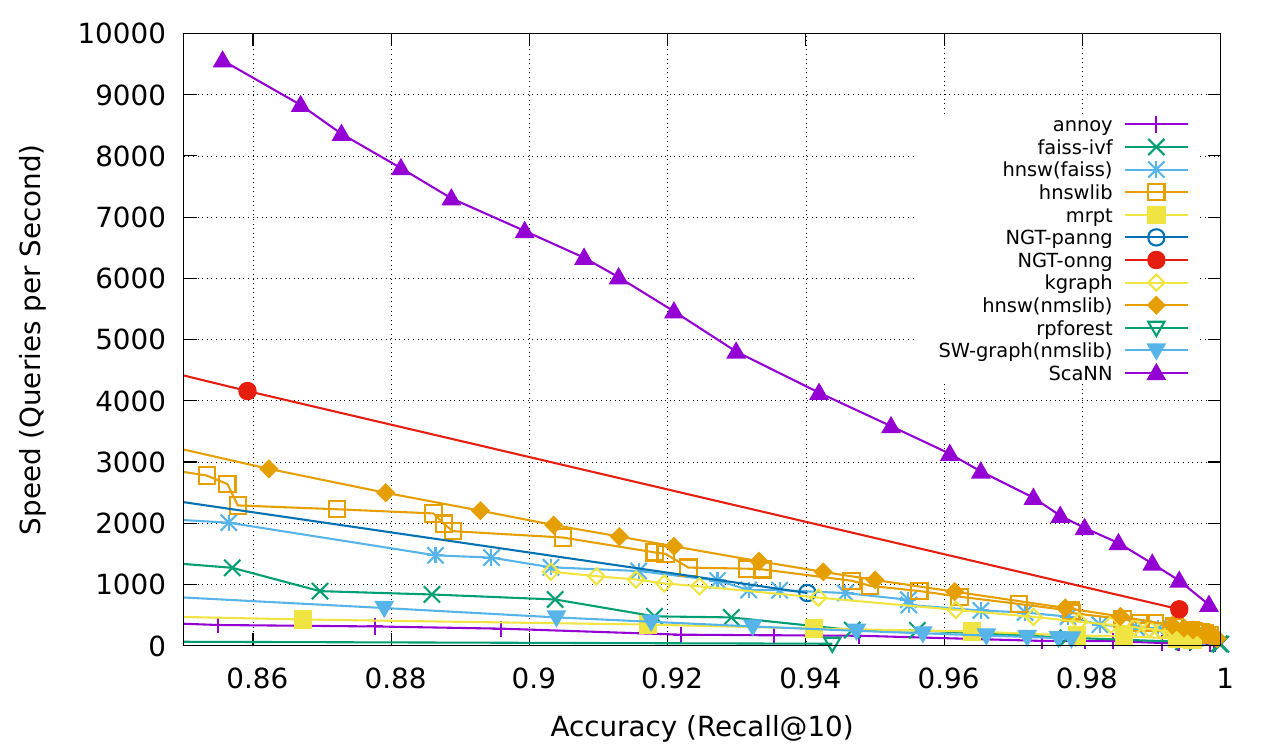
구글에서 제공하는 벡터 데이터 베이스인 Vertex.AI Vector Search Engine의 경우에는 ScaNN (Scalable Nearest Neighbors) 알고리즘을 사용하는데, ANN 알고리즘들에 비해서, 많은 데이터가 있을 경우 더 빠른 서치 성능을 보인다.
다음글에서는 벡터데이터 베이스인 Pinecone을 소개하고 실제적인 사용법을 살펴보도록 하겠다.