오픈소스 모니터링툴 - Prometheus #1 기본 개념과 구조
프로메테우스 #1 기본 개념과 구조
조대협 (http://bcho.tistory.com)
프로메테우스는 오픈 소스 기반의 모니터링 시스템이다.
ELK 와 같은 로깅이 아니라, 대상 시스템으로 부터 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템이다.
구조가 간단해서 운영이 쉽고, 강력한 쿼리 기능을 가지고 있으며, 그라파나(Grafana) 를 통한 시각화를 지원한다. 무엇보다 넓은 오픈 소스 생태계를 기반으로 해서, 많은 시스템을 모니터링할 수 있는 다양한 플러그인을 가지고 있는 것이 가장 큰 장점이다.
특히 이런 간편함 때문에 특히나 쿠버네티스의 메인 모니터링 시스템으로 많이 사용되면서 요즘 특히 더 주목을 받고 있다.
기본 구조
프로메테우스의 기본적인 아키텍처 부터 살펴보자
먼저 수집 저장 저장 아키텍처를 보면 다음과 같다.
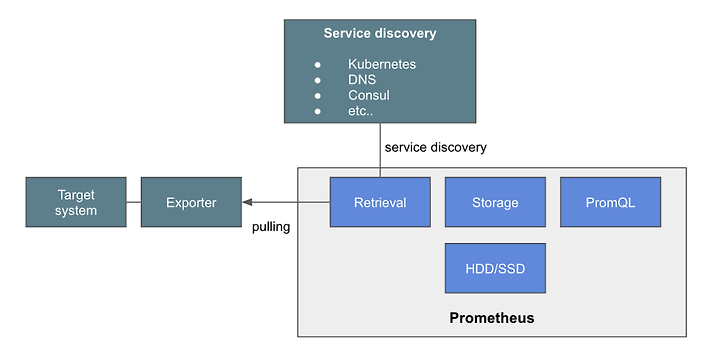
메트릭 수집 부분
수집을 하려는 대상 시스템이 Target system이다. MySQL이나, Tomcat 또는 VM 과 같이 여러가지 자원이 모니터링 대상이 될 수 있다. 이 대상 시스템에서 메트릭을 프로메테우스로 전송하기 위해서는 Exporter 라는 것을 사용한다. (다른 방법도 있지만 이는 나중에 따로 설명한다. )
풀링 방식
프로메테우스가 Target System에서 메트릭을 수집하는 방식은 풀링 방식을 사용한다. 프로메테우스가 주기적으로 Exporter로 부터 메트릭 읽어와서 수집하는 방식이다. 보통 모니터링 시스템의 에이전트 들은 에이전트가 모니터링 시스템으로 메트릭을 보내는 푸쉬 방식을 사용한다. 특히 푸쉬 방식은 서비스가 오토 스켈링등으로 가변적일 경우에 유리하다. 풀링 방식의 경우 모니터링 대상이 가변적으로 변경될 경우, 모니터링 대상의 IP 주소들을 알 수 가 없기 때문에 어려운 점이 있다. 예를 들어 웹서버 VM 2개의 주소를 설정 파일에 넣고 모니터링을 하고 있었는데, 오토 스케일링으로 인해서 VM이 3개가 더 추가되면, 추가된 VM들은 설정 파일에 IP가 들어 있지 않기 때문에 모니터링 대상에서 제외 된다.
이러한 문제를 해결하기 위한 방안이 서비스 디스커버리라는 방식인데, 특정 시스템이 현재 기동중인 서비스들의 목록과 IP 주소를 가지고 있으면 된다. 예를 들어 앞에서 VM들을 내부 DNS에 등록해놓고 새로운 VM이 생성될때에도 DNS에 등록을 하도록 하면, DNS에서 현재 기동중인 VM 목록을 얻어와서 그 목록의 IP들로 풀링을 하면 되는 구조이다.
서비스 디스커버리 (Service discovery)
그래서 프로메테우스도 서비스 디스커버리 시스템과 통합을 하도록 되어 있다. 앞에서 언급한 DNS나, 서비스 디스커버리 전용 솔루션인 Hashicorp사의 Consul 또는 쿠버네티스를 통해서, 모니터링해야할 타겟 서비스의 목록을 가지고 올 수 있다.
Exporter
Exporter는 모니터링 에이전트로 타겟 시스템에서 메트릭을 읽어서, 프로메테우스가 풀링을 할 수 있도록 한다. 재미 있는 점은 Exporter 는 단순히 HTTP GET으로 메트릭을 텍스트 형태로 프로메테우스에 리턴한다. 요청 당시의 데이타를 리턴하는 것일뿐, Exporter 자체는 기존값(히스토리)를 저장하는 등의 기능은 없다.
Retrieval
서비스 디스커버리 시스템으로 부터 모니터링 대상 목록을 받아오고, Exporter로 부터 주기적으로 그 대상으로 부터 메트릭을 수집하는 모듈이 프로메테우스내의 Retrieval 이라는 컴포넌트이다.
저장
이렇게 수집된 정보는 프로메테우스 내의 메모리와 로컬 디스크에 저장된다. 뒷단에 별도의 데이타 베이스등을 사용하지 않고, 그냥 로컬 디스크에 저장하는데, 그로 인해서 설치가 매우 쉽다는 장점이 있지만 반대로 스케일링이 불가능하다는 단점을 가지고 있다. 대상 시스템이 늘어날 수 록 메트릭 저장 공간이 많이 필요한데, 단순히 디스크를 늘리는 방법 밖에 없다.
프로메테우스는 구조상 HA를 위한 이중화나 클러스터링등이 불가능하다. (클러스터링 대신 샤딩을 사용한다. HA는 복제가 아니라 프로메테우스를 두개를 띄워서 같은 타겟을 동시에 같이 저장 하는 방법을 사용한다. 이 문제에 대한 해결 방법은 Thanos 라는 오픈 소스를 사용하면 되는데, 이는 다음에 다시 설명하도록 한다. )
서빙
이렇게 저장된 메트릭은 PromQL 쿼리 언어를 이용해서 조회가 가능하고, 이를 외부 API나 프로메테우스 웹콘솔을 이용해서 서빙이 가능하다. 또한 그라파나등과 통합하여 대쉬보드등을 구성하는 것이 가능하다.
이 외에도 메트릭을 수집하기 위한 gateway, 알람을 위한 Alert manager 등의 컴포넌트등이 있지만, 기본적인 엔진 구조를 이해하는데는 위의 컴포넌트들이 중요하기 때문에, 이 컴포넌트들은 다른 글에서 설명하도록 한다.
프로메테우스 아키텍처에서 주의할점
간단하게 프로메테우스 아키텍처를 살펴보았는데, 이 구조에서 몇가지 생각해볼만한 점이 있다.
어디까지나 근사치라는 점
일단 풀링 주기를 기반으로 메트릭을 가지고 오기 때문에, 풀링하는 순간의 스냅샷이라는 것이다. 15초 단위로 폴링을 했다고 가정했을때, 15초 내에 CPU가 올라갔다 내려와서, 풀링 하는 순간에는 CPU가 내려간 값만 관측이 될 수 있다. 스냅삿에 대한 연속된 모음일 뿐이고, 근사값의 형태라는 것을 기억할 필요가 있다.
싱글 호스트
프로메테우스는 싱글 호스트 아키텍처이다. 확장이 불가능하고, 저장 용량이 부족하면 앞에서 언급한데로 디스크 용량을 늘리는 것 밖에 방안이 없다. 특히나 문제점은 프로메테우스 서버가 다운이 되거나 또는 설정 변경등을 위해서 리스타트등을 하더라도 그간에 메트릭은 저장이 되지 않고 유실이 된다는 점이다.