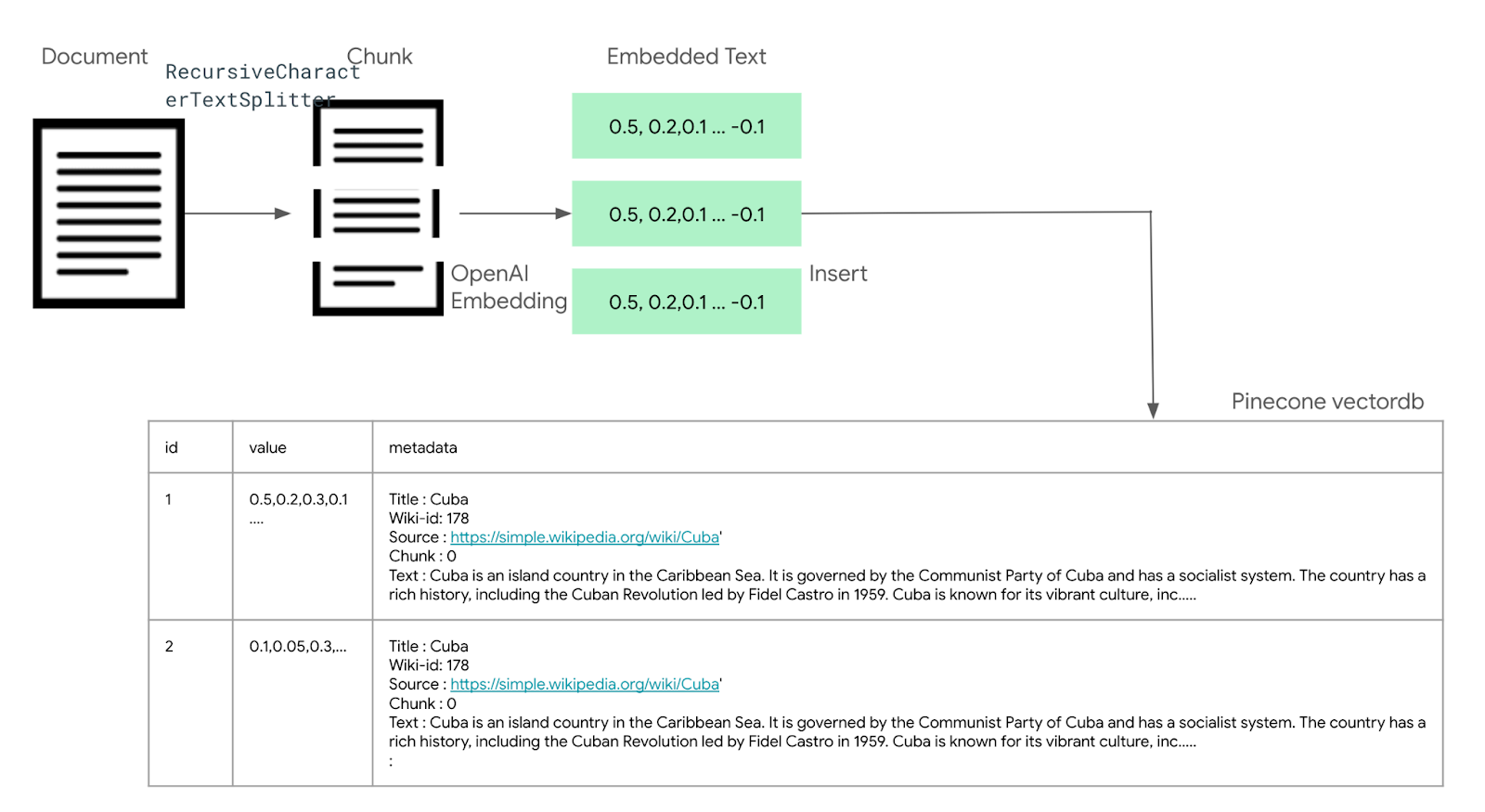
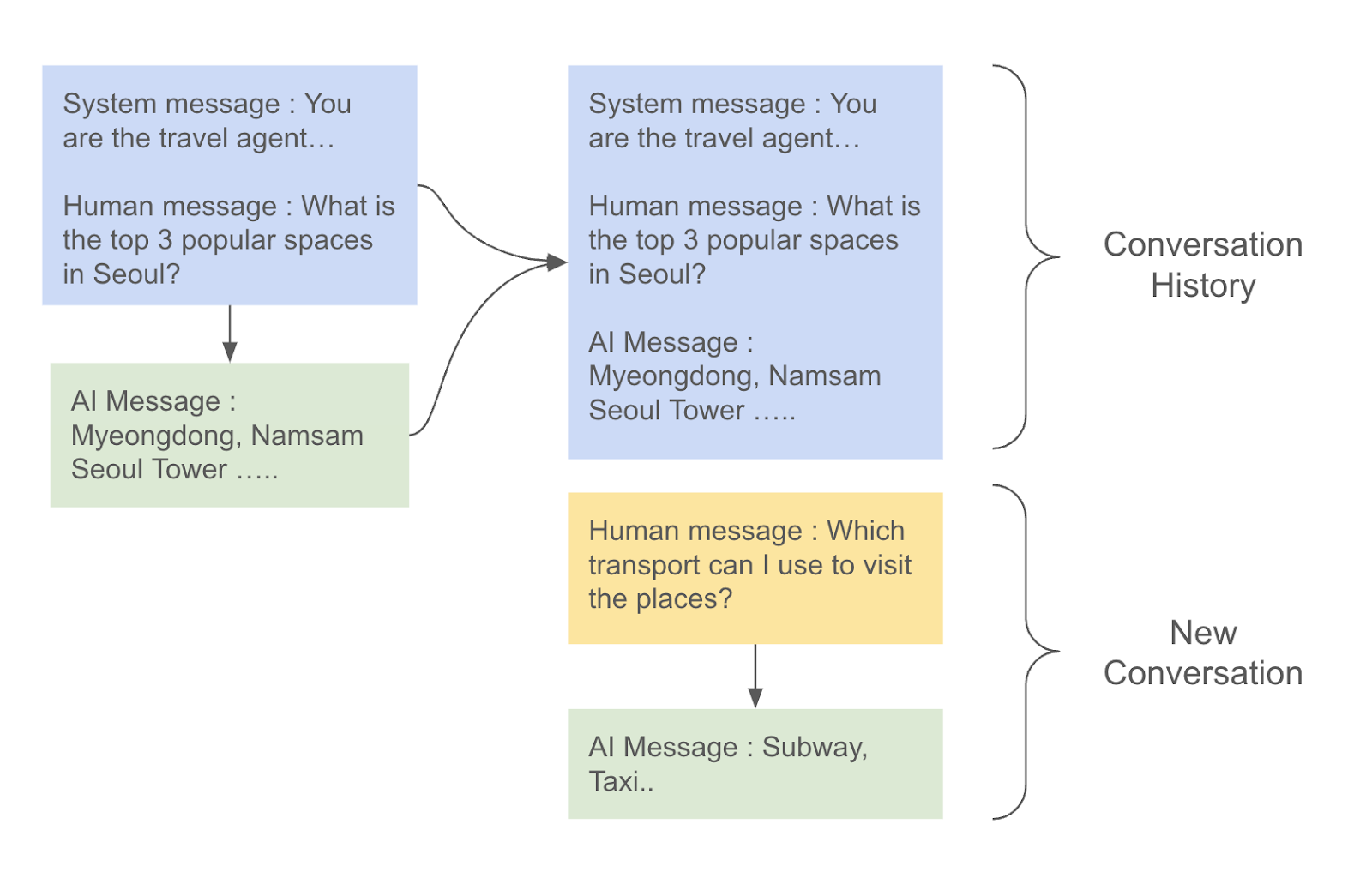
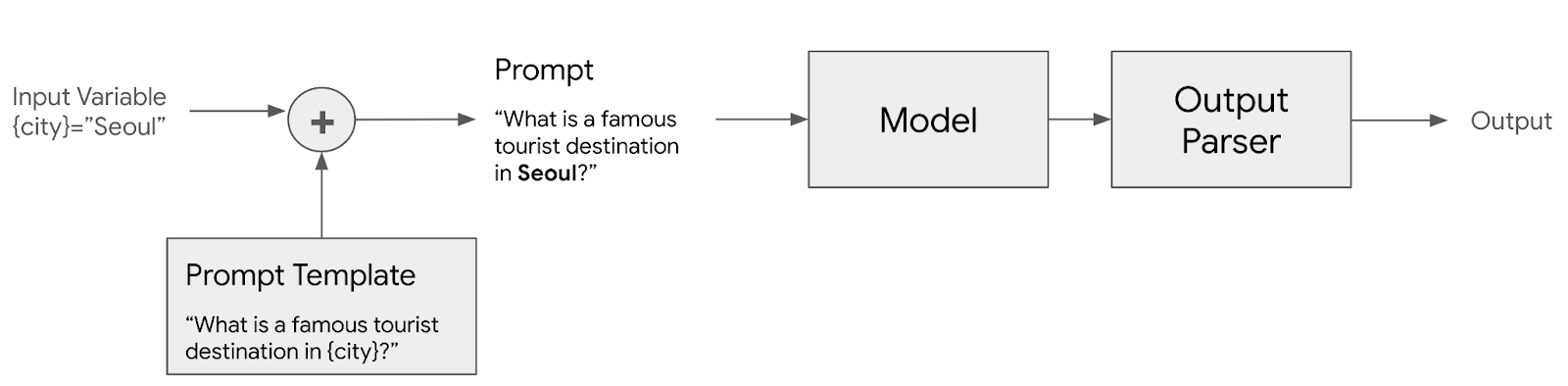
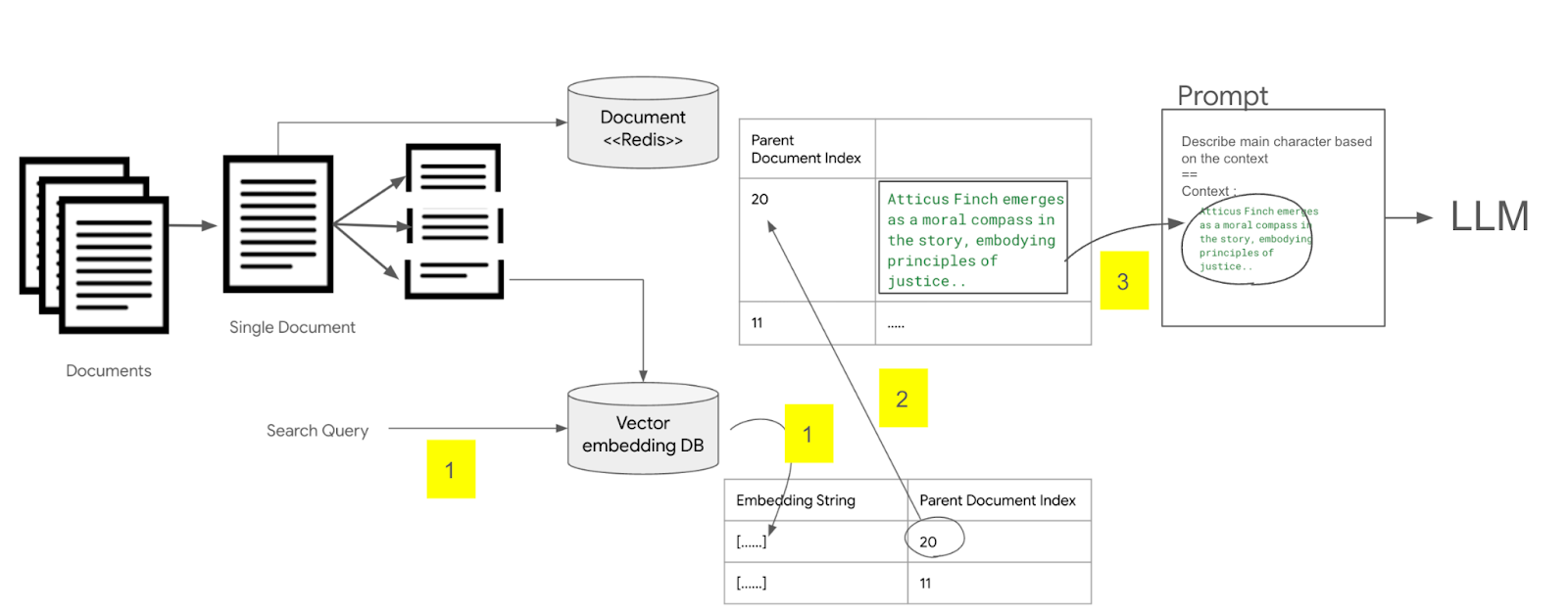
LLM은 학습 당시의 데이터만 기억하고 있기 때문에 학습 이후에 데이터에 대한 질의에 답변할 수 없고, LLM의 고질적인 문제인 환상(Halluciation)효과를 방지하기 위해서는 Ground Truth(진실)에 해당하는 외부 문서를 참조해서 답변하도록 하는것이 좋다. 이러한 구조를 RAG (Retrieval Agumentated Generation) 이라고 하는데, 이번글에서는 Langchain을 이용하여 RAG를 구현하는 방법에 대해서 알아보자. 이 구조를 이해하기 위해서는 벡터 임베딩, 유사도 검색, 벡터데이터 베이스에 대한 선수 지식이 필요한데, 아래 글을 참고하기 바란다. 1. RAG와 벡터데이터 베이스 Pinecone 2. 임베딩과 유사도 검색 3. Pinecone 둘러보기 4. 텍스트 임베..