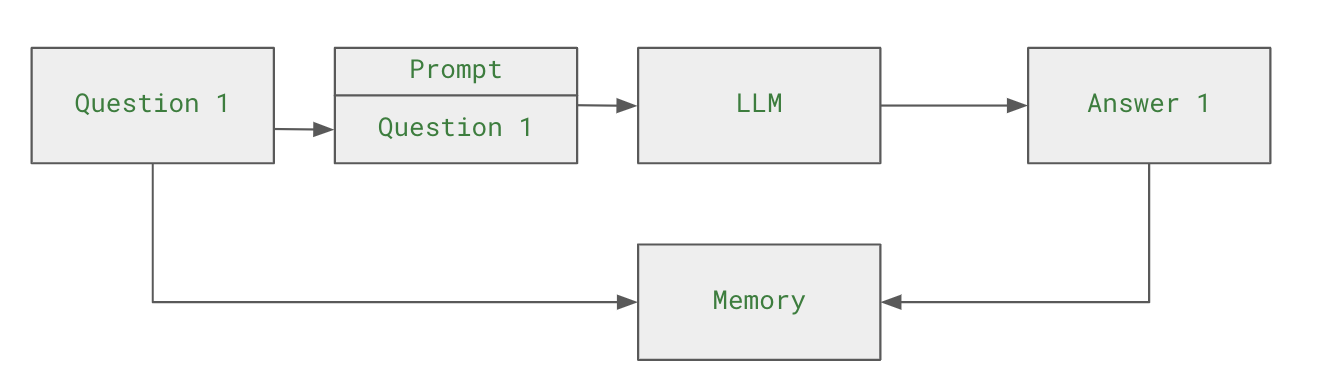
조대협 (http://bcho.tistory.com) 노트 : 이글은 LLM 개발 프레임웍 Langchain의 일부 글입니다. 연재 글은 https://bcho.tistory.com/category/%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%83%80%20%26%20%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D/%EC%83%9D%EC%84%B1%ED%98%95%20AI%20%28ChatGPT%20etc%29 를 참고하세요. LLM 기반의 챗봇 에서는 질문에 대한 답변을 기존의 대화의 내용이나 컨텍스트(문맥)을 참고하는 경우가 많다. 예를 들어, “서울에서 유명한 여행지는 어디야?” 라는 질문 후에, “그 근처에 맛있는 식당이 어디있어?” 라고 질문을 하면 챗봇은 서울의 유..