Vertex.AI로 파이프라인과 metadata 구현하기
Vertex.AI Pipeline(Kubeflow pipeline) & metadata
조대협 (http://bcho.tistory.com)
이 글은 google developer codelab의 Using Vertex ML Metadata with Pipeline 예제를 기반으로 한다. . (코드 소스 : https://codelabs.developers.google.com/vertex-mlmd-pipelines)
예제 코드의 실행은 위의 링크를 참고하면, step by step으로 진행할 수 있다.
Vertex.AI는 구글 클라우드의 AI 플랫폼 솔루션으로 여러가지 컴포넌트를 가지고 있다.
이 예제에서는 데이터를 읽어서 학습하고, 모델을 만들어서 배포하는 파이프라인에 대해서 설명한다.
파이프라인의 개념은, 여러개의 컴포넌트를 순차적으로 실행하는 워크플로우로 볼 수 있다.
이 예제의 시나리오는 다음과 같다.
- 빅쿼리 테이블에서 데이터를 읽어서 CSV 파일로 컨버팅한 다음에 GCS에 저장한다.
- GCS에 저장된 CSV파일을 읽어서 pandas dataframe으로 변환한다.
- 변환된 데이터를 sklearn의 Decision Tree Classifier를 이용한다.
- 학습중에 정확도, 프레임웍이름, 데이터셋 사이즈를 메타데이터에 저장한다.
- 학습이 완료된 모델을 (GCS)에 저장한다.
- GCS 에 저장된 모델을 읽어서 Vertex.AI 모델 서비스에 등록한다.
- 등록된 모델을 Vertex.AI 서빙 시스템은 EndPoint에 배포한다.
이 워크플로우가 어떻게 구현이 되는지 코드를 통해서 살펴보자
라이브러리 임포트
| import kfp import matplotlib.pyplot as plt import pandas as pd import requests from kfp import dsl from kfp.v2 import compiler from kfp.v2.dsl import (Artifact, Dataset, Input, InputPath, Model, Output, OutputPath, ClassificationMetrics, Metrics, component) from google.cloud import aiplatform from google.cloud.aiplatform import pipeline_jobs from typing import NamedTuple # We'll use this beta library for metadata querying from google.cloud import aiplatform_v1beta1 |
먼저 필요한 라이브러리들을 임포트 해야 하는데, Vertex.AI 파이프라인은 오픈소스 Kubeflow pipeline의 매니지드 서비스 버전으로, Kubeflow pipeline SDK를 이용하여 파이프라인을 구현한다. 그래서 위와 같이 kfp.* 패키지들을 import 한다.
컴포넌트 구현
앞의 시나리오에서 설명한 내용을 구현하기 위해서 크게 3가지 컴포넌트를 구현한다.
- get_dateframe
빅쿼리 테이블에서 데이터를 읽어서 CSV로 변환한 후에, GCS에 파일로 저장한다. - sklearn_train
GCS에서 CSV 파일을 읽어서 sklearn을 이용해서 학습을 한후, 학습된 모델을 GCS에 저장한다. - deploy_model
GCS에 저장된 모델을 읽어서 vertex.ai model에 등록한 후에, vertex.ai endpoint에 서빙을 위해서 배포한다.
그러면 각각의 컴포넌트에 대해서 코드를 보면서 이해해보자
get_dateframe
| @component( packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow"], base_image="python:3.9", output_component_file="create_dataset.yaml" ) from google.cloud import bigquery import pandas as pd bqclient = bigquery.Client() table = bigquery.TableReference.from_string( bq_table ) rows = bqclient.list_rows( table ) dataframe = rows.to_dataframe( create_bqstorage_client=True, ) dataframe = dataframe.sample(frac=1, random_state=2) dataframe.to_csv(output_data_path) |
@component는 dsl 정의로, 이 함수가 kubeflow pipeline에서 호출되는 컴포넌트임을 정의한다.
이 컴포넌트는 기본적으로 컨테이너로 배포되서 동작이 된다.
그래서 위의 코드와 같이 컨테이너의 베이스 이미지를 base_image로 정의한 후에, 필요한 패키지들을 인스톨할 수 있도록 종속 관계에 있는 파이썬 패키지들을 package_to_install에 정의한다.
def get_dataframe 부터는 파이썬 함수로, 실제 비즈니스 로직을 구현한다.
| def get_dataframe( bq_table: str, output_data_path: OutputPath("Dataset") ): |
첫번째 인자는 데이터를 읽어올 빅쿼리 테이블 명을 인자로 받는다. 두번째는 output을 쓸 경로로 받는데, kubeflow pipeline의 OutputPath annotation으로 지정이 된다. 구글 클라우드에서는 OutputPath가 디폴트로 GCS가 된다. 각 컴포넌트 별로 연산된 결과 파일들을 다음 단계로 넘기기 위해서는 중간 저장소가 필요한데, 구글 클라우드에서는 GCS를 그 저장소로 사용한다. Output 중에서 “Dataset” 아웃풋으로 지정한다.
다음 빅쿼리 클라이언트를 생성해서 지정된 테이블을 읽고, 그 테이블에서 전체 row들을 읽어와서 rows 변수에 저장한다.
| bqclient = bigquery.Client() table = bigquery.TableReference.from_string( bq_table ) rows = bqclient.list_rows( table ) |
읽어들인 row들을 dataframe으로 컨버팅 한다음에 sample 링을 이용해서 일부 데이터만 추출한후 to_csv를 이용해서 output_data_path에 경로에 파일로 저장한다.
| dataframe = rows.to_dataframe( create_bqstorage_client=True, ) dataframe = dataframe.sample(frac=1, random_state=2) dataframe.to_csv(output_data_path) |
이 단계가 끝나면 GCS의 {project id}/pipeline_root/{사용자 account}/{jobid}/{컴포넌트 이름}/ 디렉토리 아래에 csv 파일이 저장된다.
{project id} /pipeline_root/322120889349/mlmd-pipeline-large-20210902222800/get-dataframe_-7726338577126129664/output_data_path
sklearn_train
학습 데이터가 준비되었기 때문에, 실제로 학습을 해야 한다. 함수 정의 부분을 보면 다음과 같다.
| @component( packages_to_install=["sklearn", "pandas", "joblib"], base_image="python:3.9", output_component_file="beans_model_component.yaml", ) def sklearn_train( dataset: Input[Dataset], metrics: Output[Metrics], model: Output[Model] ): |
dataset은 input 입력인데, Dataset 부분에서 데이터를 읽어오도록 한다. “Dataset”은 앞에 get_dataframe에서 output_data_path를 OutputPath(“Dataset”)으로 지정하였기 때문에, 이 output이 sklearn_train의 input이 된다.
다음 아래 코드 블럭에서 CSV 파일을 읽어서 학습을 진행한다.
| from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import roc_curve from sklearn.model_selection import train_test_split from joblib import dump import pandas as pd df = pd.read_csv(dataset.path) labels = df.pop("Class").tolist() data = df.values.tolist() x_train, x_test, y_train, y_test = train_test_split(data, labels) skmodel = DecisionTreeClassifier() skmodel.fit(x_train,y_train) score = skmodel.score(x_test,y_test) print('accuracy is:',score) |
다음 코드 블록이 흥미롭게 살펴볼 수 있는 내용인데,
학습에서 발생한 각종 지표(예를 들어 학습 정확도 등)이나 각 컴포넌트마다 로그 처럼 저장하고 싶은 지표들은 별도로 메타데이터라고 하여 관리가 가능하다.
다음은 metrics라는 메타 데이터로 3개의 데이터를 저장하는 내용이다.
| metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "Scikit Learn") metrics.log_metric("dataset_size", len(df)) |
이렇게 저장한 데이터들은 나중에 vertex.ai metadata 부분에서 확인이 가능하다.
| dump(skmodel, model.path + ".joblib") |
마지막으로 dump 함수를 이용하여 학습된 모델을 지정된 위치에 저장한다. model 변수는 Ouput타입중에 [Model]을 저장하는 타입으로 지정하였다.
deploy_model
모델 학습이 완료되면 이 모델을 Vertex.AI Model 리파지토리에 저장하고, 저장된 Model을 Vertex.AI 서빙 플랫폼인 Endpoint에 배포하는 과정을 거친다.
앞의 두 컴포넌트는 Kubeflow pipeline 기반으로 사실상 구글 클라우드에 대한 종속성이 없는데 반해서, 아래 코드는 Model을 저장하고, Endpoint로 서빙하는 기능은 Vertex.AI에 고유 기능이기 때문에, 구글 클라우드에 대한 종속성이 발생한다.
| @component( packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn"], base_image="python:3.9", output_component_file="beans_deploy_component.yaml", ) def deploy_model( model: Input[Model], project: str, region: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project, location=region) deployed_model = aiplatform.Model.upload( display_name="beans-model-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name |
- 모델 업로드는 aiplatform.Model.upload를 이용해서 모델을 업로드 한다.모델은 서빙 가능한 컨테이너 형태로 패키징 되서 업로딩 되는데, 이를 위해서 serving_container_image를 이용해서, 베이스 이미지를 지정한다. 여기서는 sklearn cpu 컨테이너 이미지를 지정하였다.
- 다음으로 업로드된 모델을 vertex.ai의 서빙환경인 endpoint에 deploy 메서드를 이용해서 배포한다.
Pipeline
각각의 컴포넌트를 구현 하였으면, 이 컴포넌트를 묶어야 한다.
순차적으로 get_dataframe task → sklearn_train task → deploy_model task를 아래와 같이 수행한다.
| @dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="mlmd-pipeline", ) def pipeline( bq_table: str = "", output_data_path: str = "data.csv", project: str = PROJECT_ID, region: str = REGION ): dataset_task = get_dataframe(bq_table) model_task = sklearn_train( dataset_task.output ) deploy_task = deploy_model( model=model_task.outputs["model"], project=project, region=region ) |
파이프라인이 모두 완성되었으면, 이를 실행하기 위해서, 파이프라인을 컴파일 한후에 실행해야 한다.
| compiler.Compiler().compile( pipeline_func=pipeline, package_path="mlmd_pipeline.json" ) run1 = pipeline_jobs.PipelineJob( display_name="mlmd-pipeline", template_path="mlmd_pipeline.json", job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP), parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"}, enable_caching=True, ) run1().run |
실행
학습을 실행하면, 실행한후에 학습 진행 현황이나 결과를 비주얼하게 모니터링할 수 있는데, 이 기능이 오픈소스 Kubeflow pipeline에 비해서 Vertex.AI가 가지고 있는 장점이라고 할 수 있다. Kubeflow pipeline도 파이프라인에 대한 UI를 가지고 있고 각종 지표를 모니터링할 수 있는 기능을 가지고는 있지만, 아무래도 상업 서비스인 Vertex.AI에 비해서는 상대적으로 완성도가 떨어진다.
파이프라인 실행 모니터링
파이프라인을 실행해서 Vertex.AI > Pipeline 메뉴를 보면 현재 실행중인 파이프라인을 볼 수 있다. 아래는 실행중인 파이프라인인데, 순차적으로 수행되는 3개의 컴포넌트 get-bean-df, beans-sklearn, deploy-model 를 볼 수 있다. 각 컴포넌트 뒤에는 컴포넌트별로 생성되는 아웃풋과 이에 대한 자세한 정보를 클릭하면 볼 수 있다.
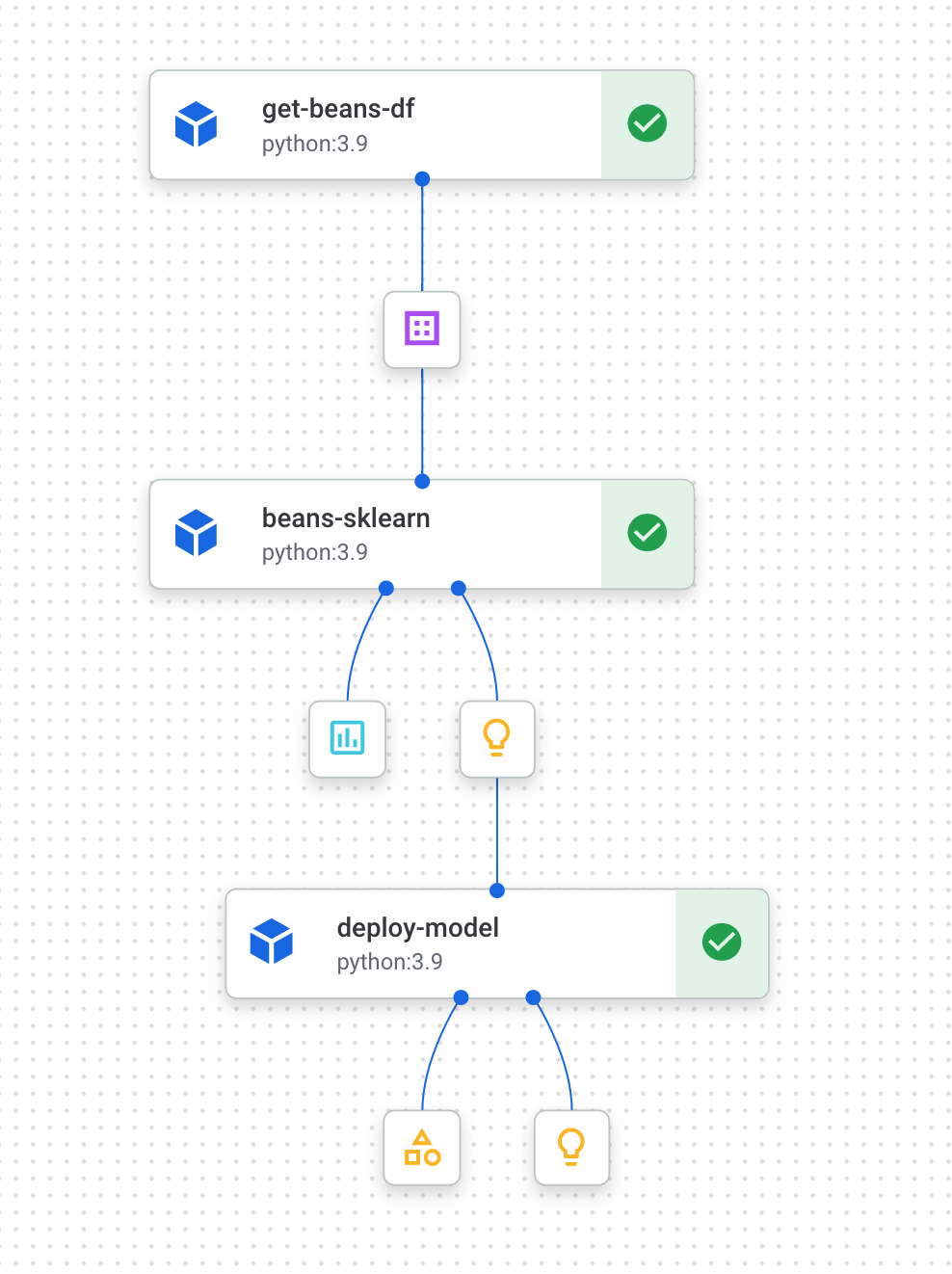
각 컴포넌트는 실행될때 도커 컨테이너로 구현된 컴포넌트를 실행하는데, 실행 런타임은 Vertex.AI > Training을 사용한다. Custom Job 메뉴를 보면 각 컴포넌트들이 실행된 Job을 모니터링할 수 있다. (아래 그림)
잡 모니터링

각 Job을 클릭하면, 각 컴포넌트를 수행하는데서 생성된 상세한 로그와, CPU, 메모리 GPU 사용량등을 모니터링 할 수 있다.
메타 데이터 확인
앞에서 각 컴포넌트에서 생성된 메타 데이터를 저장했는데, 단계별로 생성된 메타 데이터는 Vertex.AI의 Meta 데이터 저장소에 저장된다.
아래 파이프라인에서 보면 sklearn-train에서 training accuracy와 dataset_size 등을 메타데이타에 저장하였는데, 메타데이터 아이콘을 클릭하면 아래 그림과 같이 저장한 메타 데이터를 확인할 수 있다.

Pipeline 메뉴로 가면 과거에 실행한 그리고 실행중인 파이프라인을 볼 수 있는데, 실행된 파이프라인들을 아래 그림과 같이 여러개를 선택한 후에 Compare 버튼을 누르면 메타 데이타를 비교할 수 있다.
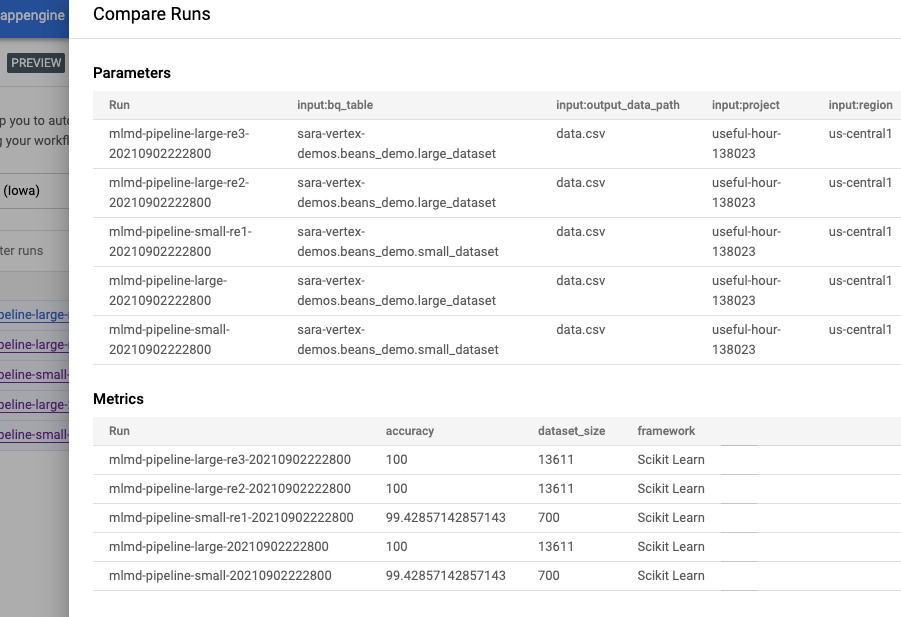
학습간 메타 데이타 비교

아래는 5개 RUN에 대한 Metric을 비교하는 화면인데, 각 RUN마다 어떤 프레임웍을 사용했는지, 데이터 양은 어떻게 되는지 그리고 모델별 정확도는 어떻게 차이가 나는지 비교해볼 수 있다.
리니지 모니터링
머신러닝 파이프라인에서 중요하게 지켜봐야하는 것중 하나는 데이터가 어디서 와서 어디로 이동하는지, 데이터의 이동 경로 (리니지라고 한다)를 추적할 필요가 있는데, Vertex.AI에서는 아래 그림과 같이 데이터의 입력/출력을 아래 그림과 같이 표현하여 경로를 추적할 수 있도록 해준다.

이렇게 학습이 끝난 모델은 export 된 후, serving이 가능한 형태로 컨테이너로 패키징이 되서 Vertex.AI Models 에 저장되게 되는데, 아래는 실제로 모델이 Models 리파지토리에 저장된 결과이다.
배포된 모델 확인

이번 예제에서는 Vertex.AI에서 파이프라인 구현 방법과, 각 컴포넌트에 대한 구현 방법 그리고 메터 데이터 저장 방법에 대해서 알아보았고, 실제로 UI상에서 어떻게 모니터링할 수 있는지를 알아보았다.