머신러닝 파이프라인에서 데이터 전처리 방법
Data Preprocessing in ML Pipeline
본글은 구글 클라우드 블로그에 포스팅한 글을, 재 포스팅 허가를 받은 후 포스팅한 글입니다.
다른 좋은 글들도 많으니 아래 출처 링크를 참고해 주새요
출처 링크
머신러닝 파이프라인에서, 데이터는 모델 학습 및 서빙의 입력에 알맞게 가공되어야 한다. 이를 전처리라고 하는데, 이번 글에서는 전처리에 대한 개념과 이에 대한 구현 옵션등에 대해서 알아보도록 한다.
처리 단계별 데이터 분류
머신러닝에서 데이터 전처리는 모델 학습에 사용되는 데이터 형태로 데이터를 가공하는 과정을 이야기한다.
데이터 전처리는 여러 단계로 이루어지는데, 단계별로 처리된 데이터에 대해서 다음과 같이 명명한다.
Raw data
초기에 수집된 원본 데이터로 분석이나, 머신러닝 학습 용도로 전혀 전처리가 되지 않은 데이터를 의미한다.
하둡과 같은 데이터 레이크에 저장된 데이터나, 기본적인 처리를 통해서 테이블 구조로 데이터 레이크에 저장된 데이터가 Raw 데이터에 해당한다.
Prepared data
Prepared data는 Data engineering 전처리에 의해서, 학습을 위한 데이터만 추출한 서브셋 데이터를 의미한다. 예를 들어 서울 20대 사용자의 구매 패턴을 머신러닝 모델로 만들고자 할때, 서울 20대 사용자 데이터만 추출한 경우 이 데이터를 Prepared data라고 한다. 단순하게 서브셋만을 추출하는 것이 아니라, 깨끗한 상태의 데이터로 정재된 데이터인데, 정재의 의미는 비어 있는 행이나 열을 삭제한 데이터를 의미한다.
Engineered feature
이렇게 정제된 데이터는 머신러닝 학습과 서빙에 적절한 형태로 재가공 되어야 하는데 이를 Feature Engineering 이라고 한다. 예를 들어 숫자와 같은 값을 0~1 사이로 맵핑 시키거나 , 카테고리 밸류 예를 들어 남자/여자를 0,1과 같은 값으로 맵핑 시키고, 전체 데이터를 학습,평가용으로 7:3 분할하여 저장하는 것이 이에 해당 한다.

<그림. 데이터 전처리 단계 및 단계별 생성된 데이터 >
데이터 전처리 기법
그러면, 이 데이터 전처리 과정에서 구체적으로 어떤 기법으로 데이터를 처리할까? 몇가지 대표적인 기법을 정리해보면 다음과 같다.
Data cleansing : 데이터에서 값이 잘못되거나 타입이 맞지 않는 행이나 열을 제거하는 작업을 한다.
Instance selection & partitioning : 데이터를 학습,평가,테스트용 데이터로 나누는 작업을 한다. 단순히 나누는 작업 뿐만 아니라, 데이터를 샘플링 할때, 그 분포를 맞추는 작업을 병행한다. 예를 들어 서울/대구/부산의 선거 투표 데이타가 있을때, 인구 비율이 9:2:3이라고 할때, 전체 인구를 랜덤하게 샘플링해서 데이타를 추출하는 것이 아니라, 서울/대구/부산의 인구 비율에 따라서 서울에서 9, 대구에서 2, 부산에서 3의 비율로 샘플링을 할 수 있다. 이를 stratified partitioning 이라고 한다. 또는 데이터 분포상에서 특정 카테고리의 데이터 비율이 적을때, 이 카테고리에 대해서 샘플의 비율을 높이는 minority classed oversampling 등의 기법을 이 과정에서 사용한다.
Feature tuning : 머신러닝 피처의 품질을 높이기 위해서 0~1값으로 값을 normalization 시키거나, missing value를 제거 하거나, 아웃라이어등을 제거하는 등의 과정을 수행한다.
Representation transformation : 피처를 숫자로 맵핑 시키는 작업을 한다. 카레고리컬 피처를 one hot encoding 등을 통해서 숫자로 맵핑하거나, 텍스트를 embedding 을 통해서 숫자로 변환하는 작업등을 수행한다.
Feature extraction : PCA와 같은 차원 감소 기법을 이용하여, 전체 피처의 수를 줄이는 작업을 수행하거나, 피처를 해시값으로 변환하여, 더 효율적인 피쳐를 사용하는 작업을 한다. .
Feature selection : 여러개의 피처(컬럼)중에 머신러닝에 사용할 피처만을 선별한다.
Feature construction : 기존의 피처를 기반으로 polynomial expansion 이나, feature crossing 등의 기법을 이용하여 새로운 피처를 만들어낸다.
데이터 전처리 단위
Instance level transformation & Full pass transformation
데이터 전처리를 할때 어떤 단위로 데이터를 전처리 할지에 대한 정의이다. 예를 들어 숫자 데이터의 값을 0~1 사이로 맵핑하고자 하면, 그 데이터의 최소/최대 값을 알아야 0~1사이로 맵핑할 수가 있는데, 최소/최대값을 추출하려면, 전체 데이터에 대한 스캔이 필요하다. 반대로 NULL 값을 0으로 변환하는 작업은 전체 데이터에 대한 스캔이 필요없고 개별 데이터만 변환하면 된다. 앞에 설명한 전체 데이터에 대한 스캔이 필요한 방식을 full pass transformation 이라고 하고, 전체 데이터를 볼 필요 없이 개별 데이터에 대해 변환하는 작업을 instance level transformation이라고 한다.
Window aggregation
전체 데이터의 볼륨이 클 경우 이를 윈도우 단위로 잘라서 처리할 수 있는 방법이 있는데, 예를 들어 10분 단위로 데이터를 처리해서, 10분 단위로 최소/최대 값을 구하거나 또는 10분 단위로 어떤 값의 평균값을 대표값으로 사용하는 것들이 이에 해당한다.
일반적으로 입력값은 (entity, timestamp, value) 형태가 되며, 전처리된 출력 값은 다음과 같이. (entity, time_index, aggregated_value_over_time_window) 엔터티(피쳐)에 대해서 윈도우별로 처리된 값을 저장하는 형태가 된다. 보통 이런 window aggregation 방식은 리얼 타임 스트리밍 데이터에서 시간 윈도우 단위로 데이터를 처리하는 경우에 많이 사용이 되며, Apache Beam과 같은 스트리밍 프레임워크를 이용하여 구현한다.
구글 클라우드에서 데이터 전처리 방식
이러한 데이터 전처리는 다양한 컴포넌트를 이용해서 처리할 수 있는데, 어떤 방식이 있는지 살펴보기 전에 먼저 구글 클라우드 기반의 머신러닝 학습 파이프라인 아키텍처를 살펴보자. 아래는 일반적인 구글 클라우드 기반의 머신러닝 파이프라인 아키텍처이다.

<그림. 구글 클라우드 플랫폼 기반의 일반적인 머신러닝 학습 파이프라인 아키텍처 >
원본 데이터는 빅쿼리에 저장된다. (테이블 형태의 데이터가 아닌 이미지나 텍스트등은 클라우드 스토리지(GCS)에 저장된다.)
저장된 원본 데이터는 Dataflow를 이용해서 머신러닝 학습에 알맞은 형태로 전처리 된다. 학습/평가/테스트 셋으로 나누는 것을 포함해서, 가능하면 텐서플로우 파일형태인 *.tfrecord 형태로 인코딩 된후에, GCS 에 저장된다.
텐서플로우등으로 모델을 개발한 후에, trainer-package로 패키징을 하고, AI Platform 트레이닝에 이 모델을 업로드 한다. 업로드된 모델을 앞서 전처리된 데이터를 이용해서 학습이되고, 학습이 된 모델은 GCS에 저장된다. (텐서플로우에서 SavedModel로 저장한다.)
GCS 에 저장된 모델은 AI Plaform 서빙 엔진에 배포되고 REST API를 이용하여 서빙된다.
클라이언트에서는 이 REST API를 이용하여 학습된 모델에 대한 서빙을 이용한다.
전체 워크플로우에 대한 파이프라인 관리는 Apache Airflow 매니지드 서비스인 Composer 를 이용한다. 또는 머신러닝에 특화된 파이프라인이기 때문에, AI Platform pipeline을 사용하는 것이 좋다.
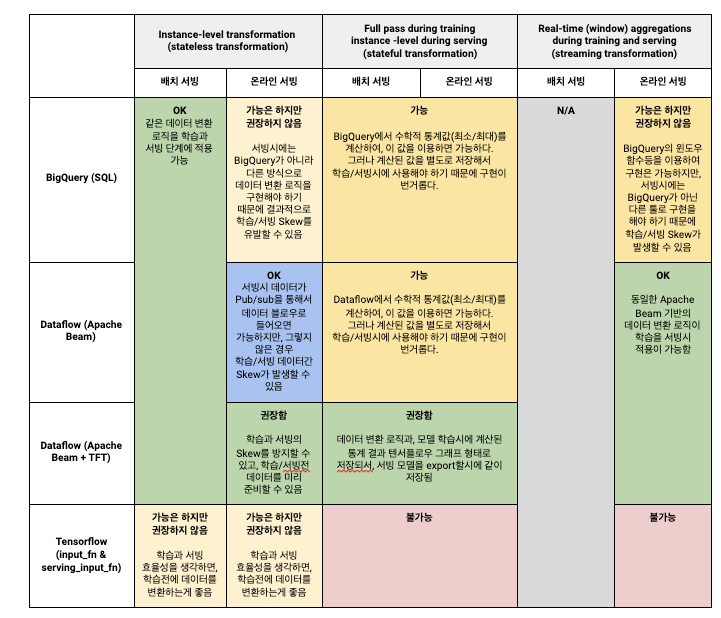
Option A: 빅쿼리에서 데이터 전처리
일반적으로 빅쿼리를 이용한 전처리는 다음과 같은 시나리오에 유용하다.
Sampling : 데이터에서 랜덤하게 일부 데이터셋만 가지고 오는 용도
Filtering : 학습에 필요한 데이터만 WHERE 문을 이용해서 가지고 오는 용도
Partitioning : 데이터를 학습/평가/테스트 용도로 나누는 용도
주로 빅쿼리는 Dataflow로 데이터를 인입하기 전체 최초 전처리 용도로 사용이 되는데, 주의할점은 빅쿼리에 전처리 로직이 많을 경우 향후 서빙에서 재 구현이 필요할 수 있다. 무슨 이야기인가 하면, 서빙시에도 입력 데이터에 대한 동일한 전처리가 필요한데, 빅쿼리에서 SQL로 작성한 전처리 로직은 서빙시에는 사용할 수 없기 때문에, 자바나 파이썬으로 전처리 로직을 다시 구현해야 하는 이중작업이 될 수 있다. 물론 서빙이 빅쿼리에 있는 데이터를 사용하는 배치 서빙일 경우 문제가 없지만, 리얼타임으로 단건의 데이터에 대해서 서빙을 하는 경우에는 빅쿼리에서 서빙용 데이터를 전처리할 수 없다.
그럼에도 불구하고 배치 서빙용인 경우 전처리를 빅쿼리를 이용할 경우 편리하고 특히 Dataflow 에 데이터를 입력하기전에 Full pass transformation 이 필요한 전체 통계 데이터 (예를 들어 평균,분산,최소/최대값)은 SQL을 통해서 쉽게 뽑아낼 수 있는 장점이 있다.
Option B: Dataflow 에서 데이터 전처리
복잡한 데이터 변환 로직이 있는 경우등에 효율적으로 사용할 수 있는 방식인데, Instance level transformation 뿐만 아니라, full pass transformation, 그리고 window aggregation 타입 모두를 지원할 수 있다.
Dataflow는 Apache Beam 오픈소스 기반의 런타임이지만, 다양한 구현 방식을 지원하고 있다.
Apache Beam을 사용하는 방법 : 가장 일반적인 방식으로 Apache Beam Java/Python SDK 을 이용하여 데이터 변환 로직을 구현할 수 있다.
Tensorflow Transformation 을 사용하는 방법 : 텐서플로우의 경우 Tensorflow Transformation (이하 TFT) 이라는 이름으로 데이터 변환 프레임워크를 제공한다. TFT는 Apache Beam 기반으로 동작하는데, 텐서플로우 코드를 기반으로 하기 때문에, 머신러닝 개발자 입장에서는 접근이 상대적으로 쉬운 장점이 있다.
Dataflow SQL을 사용하는 방법 : 앞의 두 방식의 경우에는 Java나 Python 기반의 코딩이 필요한데, 이런 코딩 없이 Window aggregation이나, 기타 복잡한 로직을 구현하고자 할때 사용할 수 있는 방식이 Dataflow SQL이다.SQL을 사용하여 구현하지만, Dataflow의 함수등을 사용할 수 있는 장점이 있다.
Dataflow Template + UDF를 사용 하는 방법 : 복잡한 변환이 아니라 단순한 맵핑이나 문자열 변환들을 어렵지 않게 구현하는 방식으로 Dataflow는 Pre-built in 된 Template을 제공한다. 이 템플릿 중에는 비즈니스 로직을 자바스크립트로 넣을 수 있는 UDF 라는 방식을 지원하는데, Apache Beam 형태로 구현할 필요 없이 단순한 변환 로직을 자바스크립트로 구현하여 GCS에 파일을 저장하고, 설정 정보에서 자바 스크립트 파일만 지정하면되기 때문에, 쉽게 사용할 수 있다.
서빙시에도 다양한 아키텍처 구현이 가능한데, Pub/Sub 큐를 통해서 데이터를 실시간으로 인입한 데이터를 머신러닝 모델로 서빙한후에, Pub/Sub으로 내보내는 near realtime 서빙이 가능하고 또는 bigtable에 서빙 결과를 저장하여 마치 serving 결과에 대한 캐쉬식으로 사용하는 구조도 가능하다.

<그림. 스트림 데이터를 이용하여 서빙을 제공하는 아키텍처>
Option C: Tensorflow 모델 내에서 데이터 전처리
아니면 데이터 전처리를 Tensorflow 모델 코드내에서 하는 방식이 있다.
feature_column 를 이용하여 피처를 임베딩하거나, 버킷화 하는 방식이 있고
아니면 데이터를 피딩하는 input functions(train_input_fn, eval_input_fn, and serving_input_fn) 안에 데이터 전처리 로직을 구현하는 방법이 있다.
Custom estimator를 사용하는 경우에는 model_fn 자체에 데이터 전처리 로직을 넣을 수 있다.
이렇게 텐서 플로우 코드단에 전처리 기능을 넣는 경우는 Instance level transformation은 가능하지만 다른 방식에 대해서는 불가능하다. 그렇지만 이미지 데이터를 학습전에 rotation하거나 flip 하는 argumentation 등은 텐서플로우 코드에서 하게 되면 동적으로 데이터를 학습 단계에 argumentation할 수 있기 때문에 효율이 좋은 장점이 있다.
Option D: DataPrep을 이용한 데이터 전처리
구글 클라우드 플랫폼에서는 데이터의 특성을 분석하고 간단한 변환을 지원하기 위한 wrangling 도구로 DataPrep을 제공한다. Engineered feature 단계까지 데이터를 가공하는 것은 어려울 수 있겠지만, Raw data를 Prepared data 형태로 cleansing 하는 용도로는 충분히 사용할 수 있으며, 특히 시각화를 통한 데이터 분포나 아웃라이어 분석이나 단순 변환등에는 효과적으로 사용할 수 있다.

<그림 DataPrep 을 이용한 Wrangling 과정 예시>
Option E: DataProc을 이용한 데이터 전처리
DataProc은 Hadoop/Spark 에 대한 구글 매니지드 서비스이다. Apache Beam을 사용하는 Dataflow와 같이 코딩을 기반으로 한다는 점은 같지만, 기존에 Hadoop/Spark 에코 시스템에 익숙한 사용자들의 경우에는 기존의 에코 시스템과 개발 코드를 재활용할 수 있다는 장점을 가지고 있다.
데이터 전처리시 고려할점
그러면 이러한 기술을 이용해서 데이터를 전처리할때, 고려해야하는 점은 무엇이 있을까?
학습/서빙 데이터에 대한 스큐(skew)
모델을 학습하여, 서비스에 배포한후에, 향후 들어오는 데이터로 서빙을 하게 되는데, 이때 학습에서 사용한 데이터와 서빙시 사용한 데이터의 특성이 다를때 이를 training-serving skew 라고 한다.
예를 들어 피처 A가 학습시에 범위가 1~255 였는데, 서빙시에 1~500 사이로 들어오게 되면 이 모델의 서빙 결과는 정확하지 못하게 된다.
(참고 : 이런 문제를 해결하기 위해서 데이터의 분포나, 수학적 통계값을 저장해 놓은 후에, 서빙전에 검증하는 방식을 사용할 수 있으며 이는 Tensorflow data validation으로 구현이 가능하다. )
Full pass transformation
Option C의 텐서플로우 모델내의 데이터 변환 로직은 Full pass transformation을 지원하지 않기 때문에, feature scaling이나, normalization 적용이 불가능하다. 이러한 전처리 기법은 최소/최대값등의 통계 데이터가 필요한데, 이러한 데이터는 모델 학습전에 계산되어야 하고, 계산된 데이터는 어디에든 저장되어 있어야 하며, 학습과/서빙 단계에 모두 일관되게 사용될 수 있어야 한다.
성능 향상을 위한 Up front data loading
Option C 텐서플로우 모델내에 데이터 변환 로직을 구현할때, 고려해야 하는 사항이다.
모델 코드 상에 데이터 전처리 로직이 있을 경우, 아래 그림과 같이 데이터 변환 작업이 끝나면, 그 데이터로 모델을 학습 시키는 구조가 된다.

<그림. 데이터 전처리가 모델 학습전에 발생하여, 대기하는 현상>
이 경우에 데이터가 전처리되고 있는 동안에는 학습이 이루어지지 않기 때문에 자원이 낭비되는 문제가 발생하고, 모델의 학습 시간에 전처리 시간까지 포함되기 때문에 전체 학습시간이 상대적으로 오래걸린다.
Option B의 데이터 플로우를 사용하는 것처럼 미리 여러 학습에 사용될 데이터를 전처리를 해놓거나 아니면 아래 그림과 같이 병렬적으로 데이터 플로우에서 데이터를 전처리하면서 모델은 학습에만 전념하도록 하면, 모델의 전체학습 시간을 줄일 수 있다.

<그림. 병렬로 데이타 전처리를 해서 모델 학습을 최적화 하는 방식>
이를 up front data loading 이라고 하는데, 텐서플로우에서는 Prefetching, Interleave, Parallel mapping 등을 tf.data.DataSet에서 다양한 방식으로 이를 지원하고 있다.
Tensorflow Transform
텐서플로우 프레임웍은 이러한 데이터 변환을 위해서 Tensorflow Transform (이하 TFT) 라는 프레임웍을 데이터 전처리 기능을 제공한다. 이 TFT를 구글 클라우드에서 실행하게 되면, Dataflow를 기반으로 실행할 수 있다. (Option B)
tf.Transform 이라는 패키지로 제공된다. TFT는 instant level transformation 뿐만 아니라, full pass transformation, window aggregation 을 지원하는데, 특히 full pass transformation을 지원하기 위해서 데이터를 변환하기 전에 Analyze 라는 단계를 거치게 된다.
아래 그림이 TFT가 작동하는 전반적인 구조를 기술한것인데,

Analyze 단계에서는 데이터의 통계적인 특성 (최소,최대,평균 값등)을 추출하고, Transform 단계에서는 이 값을 이용하여, 데이터 변환을 수행한다. 각 단계는 tft_beam.AnalyzeDataset , tft_beam.TransformDataset 로 실행될 수 있으며, 이 두 단계를 tft_beam.AnalyzeAndTransformDataset 로 합쳐서 한번에 실행하는 것도 가능하다.
Analyze 단계 : Analyze 단계에서는 통계적인 값을 Full pass operation 을 통해서 계산해내는 것이외에도, transform_fn을 생성해내는 작업을 한다. transform_fn은 텐서플로우 그래프로, 데이터 변환에 대한 instance level operation 을 계산해낸 통계값을 사용해서 수행한다.
Transform 단계 : 데이터 변환 단계에서는 transform fn을 인입 데이터에 적용하여, instance level로 데이터를 변환하는 작업을 수행한다.
모델 학습시 데이터에 대한 전처리는 학습 데이터뿐만 아니라, 평가 (Eval) 데이터에도 동일하게 적용이 되어야 하는데, Analyze는 학습데이터에만 적용되서 데이터의 특성을 추출하고, 평가 데이터에는 별도로 Analyze를 수행하지 않고, 학습 데이터에서 추출된 데이터 특성을 그대로 사용한다
TFT pipeline export
transform_fn으로 구성된 데이터 변환 파이프라인은 내부적으로 텐서 플로우 그래프로 변환이 되는데, 학습된 텐서플로우 모델을 export 하여 SavedModel로 저장할때, 이 transform_fn 그래프가 서빙용 데이터 입력함수인 serving_input_fn에 붙어서 같이 export 된다. 이 말은, 학습에서 사용한 데이터 전처리 로직인 transform_fn이 그대로 서빙단에도 같이 적용된다는 이야기이다. 물론 full-pass transformation에서 계산한 통계값도 상수형태로 저장하게 된다. 그래서 입력값에 대해서 학습과 서빙시 같은 변환 로직을 사용할 수 있게 된다.
데이터 전처리 옵션 정리
앞서 설명한 데이터 변환 전처리 옵션을 Instance level transformation, full pass level transformation, window aggregation 에 따라 정리해보면 다음과 같다.
Disclaimer
본 글의 작성자는 Google 직원입니다. 그러나 본 글의 내용은 개인의 입장에서 작성된 글이며, Google의 입장을 대변하지 않으며, Google이 본 컨텐츠를 보장하지 않습니다.
References